用于一致性训练的无监督数据增强
最近,在缺乏标签数据的情况下,半监督学习在改善深度学习模型方面显示出很大的希望。 在最近的方法中,常见的是在大量未标记的数据上使用一致性训练来约束模型预测对输入噪声的不变性。 在这项工作中,我们提出一个关于如何有效地对未标记示例引入噪声的新观点,并认为噪声的质量特别是由先进的数据增强方法产生的噪声,在半监督学习中起着至关重要的作用。 通过用先进的数据增强方法替换简单的噪声操作,我们的方法在相同的一致性训练框架下,对六种语言任务和三种视觉任务带来了实质性改进。 在仅有 20 个标记示例的 IMDb 文本分类数据集上,我们的方法实现了 4.20 的错误率,优于在 25,000 个标记示例上训练的最新模型。 在标准的半监督学习基准 CIFAR-10 上,我们的方法优于所有以前的方法,仅 4,000 个示例就可实现 2.7% 的错误率,几乎与在 50,000 个带标签示例上训练的模型的性能相匹配。 我们的方法还能与迁移学习很好地结合起来,如从 BERT 进行微调时,而且在高数据体系下能产生改进,如 ImageNet 无论是只有 10% 的标记数据还是使用带有 1.3M 额外未标记示例的完整标记集。1
1 简介
深度学习的根本缺点是,它通常需要大量标记数据才能正常工作。 半监督学习(SSL)(Chapelle 等人,2009)是利用无标签数据解决这一弱点的最有希望的方法之一。 最近在 SSL 方面的工作多种多样,但它们当中基于一致性训练的工作(Bachman 等人,2014;Rasmus 等人,2015;Laine & Aila,2016;Tarvainen & Valpola,2017)在许多基准上都显示出良好的效果。
简而言之,一致性训练方法简单地将模型预测正则化为对输入实例(Miyato 等人,2018;Sajjadi 等人,2016;Clark 等人,2018)或隐藏状态(Bachman 等人,2014;Laine 和 Aila, 2016)的小噪声保持不变。 这个框架直观上是有意义的,因为好的模型应该对输入示例或隐藏状态中的任何小变化都具有鲁棒性。 在这个框架下,这种类别中的不同方法主要不同之处在于如何应用噪声注入以及在何处应用噪声注入。 典型的噪声注入方法有添加高斯噪声、丢弃噪声和对抗性噪声。
在这项工作中,我们研究噪声注入在一致性训练中的作用,并观察到先进的数据增强方法,特别是在监督学习中效果最好的方法(Simard 等人,1998;Krizhevsky 等人,2012;Cubuk 等人,2018;Yu 等人,2018),在半监督学习中也表现良好。 在监督学习中数据增强操作的性能与一致性训练中的性能之间确实存在着很强的相关性。 因此,我们建议用高质量的数据增强方法代替传统的噪声注入方法,以改善一致性训练。 为了强调在一致性训练中使用更好的数据增强,我们将方法命名为无监督数据增强或 UDA。
我们在各种语言和视觉任务上评估 UDA。 在六个文本分类任务上,我们的方法实现了比最先进模型的显著改进。 值得注意的是,在 IMDb 上,具有 20 个标记示例的 UDA 优于在 1250 倍标记数据上训练的最先进模型。 我们还在视觉标准半监督学习基准上评估 UDA,如 CIFAR-10 和 SVHN。 UDA 明显优于所有现有的半监督学习方法。 在具有 4,000 个带标签示例的 CIFAR-10 上,UDA 的错误率达到 5.29,几乎与使用 50,000 个带标签示例的完全受监督模型的性能相匹配。 此外,通过更好的架构 PyramidNet+ShakeDrop,UDA 实现了新的最先进错误率 2.7。 在 SVHN 上,UDA 仅使用 1,000 个带标签的示例实现了 2.55 的错误率。 最后,我们还发现在有大量监督数据的情况下 UDA 同样是有益的。 例如,在 ImageNet 上,UDA 利用 10% 的标记数据集就使得 top-1 准确率从 58.84 改进到 68.78,当使用全部标记数据集和 1.3M 外部没有标记的数据集时,准确率从 78.43 改进到 79.05。
我们的主要贡献和发现可以总结如下:
- 首先,我们表明,在监督学习中发现的最先进的数据增强也可以作为强制一致性半监督框架下的优秀噪声源。 结果参见表 1 和 表 2。
- 其次,我们表明,UDA 可以匹配甚至优于使用多几个数量级标记数据的纯监督学习。
- 最后,我们表明,UDA 与迁移学习很好地结合在一起例如当从 BERT 进行微调时(请参见表 4),并且在高数据体系下有效例如在 ImageNet上(请参见表 5)。
2 无监督数据增强(UDA)
在本节中,我们首先阐述任务,然后介绍 UDA 背后的关键方法和概念。 在整个论文中,我们将重点放在分类问题上,并使用 x 表示输入,y* 表示其实际预测目标。 我们关注于学习一个模型 pθ(y∣x) ,它根据输入 x 预测 y*,其中 θ 表示模型参数。 最后,我们将使用 L 和 U 分别表示标记的和未标记的示例集。
2.1 背景:有监督数据增强
数据增强的目的是在不改变标签的情况下,通过对示例进行转换,创建新颖的、看起来很真实的训练数据。 形式上,设 q(ˆx∣x) 是一种增强转换,根据它可以基于原始示例 x 得出增强示例 ˆx。 为了使增强变换有效,要求从这个分布得出的任何示例 ˆx ∼q(ˆx∣x) 与 x 具有相同的真实标签。 给定有效的增强变换,我们可以简单地在增强示例上将负对数似然性最小化。
有监督数据的增强可以等效地看作是从原始有监督数据集构造增强的有标记数据集,然后在增强的数据集上训练模型。 因此,增强的数据集需要提供额外的归纳偏差才能更有效。 因此,如何设计增强变换就变得至关重要。
近年来,在监督环境下的 NLP(Yu 等人,2018)、视觉(Krizhevsky 等人,2012;Cubuk 等人,2018)和语音(Hannun 等人,2014;Park 等人,2019)的数据增强设计方面取得了重大进展。 尽管取得了令人鼓舞的结果,但数据增强通常被认为是“蛋糕上的樱桃”,它提供稳定但有限的性能提升,因为到目前为止这些增强仅应用于一系列通常很少的标记示例。 在这种限制的激励下,通过一致性训练框架,我们将监督数据增强的进步扩展到了丰富的无标签数据的半监督学习中。
2.2 无监督数据增强
如简介中所述,半监督学习的最新工作是利用未标记的示例来增强模型的平滑性。 这些工作的一般内容可以概括如下:
- 给定输入 x,计算根据 x 输出的分布 pθ(y∣x) 和通过注入微小噪声 ε 版本的输出分布 pθ(y∣x,ε)。 噪声可以应用于 x 或隐藏状态。
- 最小化两个分布之间的差异值 Ɗ
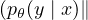 pθ(y ∣ x, ε))。
pθ(y ∣ x, ε))。
此过程使模型对噪声 ε 不敏感,因此相对于输入(或隐藏)空间的变化更平滑。 从另一个角度来看,最小化一致性损失会逐渐将标签信息从已标记的示例传播到未标记的示例。
在本工作中,我们关注将噪声注入到输入 x 这种方式,即 ˆx =q(x,ε),如先前的工作所述(Sajjadi 等人,2016;Laine & Aila,2016;Miyato 等人,2018)。 但是与已有的工作不同,我们的焦点在于没有关注过的问题,即噪声操作 q 的形式或“质量”如何影响此一致性训练框架的性能。 具体而言,为了强制一致性,先前的方法通常采用简单的噪声注入方法,例如添加高斯噪声对未标记噪声的示例进行简单的输入增强。 相比之下,我们假设在监督学习中更强的数据增强在半监督一致性训练框架中用于对未标记的示例进行噪声处理时,也可以带来更优的性能,因为已经证明,更高级的数据增强、更多样化和自然的数据增强可以在监督环境中带来显著的性能提升。
遵循这个想法,我们提出使用在各种有监督情况下验证过的丰富的最先进数据增强方法来注入噪声,并在未标记的示例上优化相同的一致性训练目标。 当结合带标签的示例进行训练时,我们利用加权因子 λ 平衡有监督的交叉熵和无监督的一致性训练损失,如图 1 所示。 从形式上看,完整的目标可以写为:
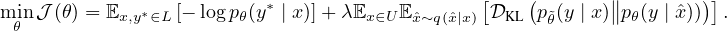 |
其中 q(ˆx∣x) 是数据增强转换,˜θ 是当前参数 θ 的 固定 副本,表示梯度不会通过 θ 传播,如 Miyato 等人 (2018)。 我们还遵循 VAT(Miyato 等人,2018)使用 KL 散度。 对于大多数实验,我们将 λ 设置为 1,并对监督数据和非监督数据使用不同的批次大小。 在视觉领域中,应用简单的增强到有标记的示例,包括裁剪和翻转。 为了最大程度地减少无标签示例的有监督训练和预测之间的差异,我们将相同的简单增强应用于无标签示例以计算 p˜θ(y∣x)。
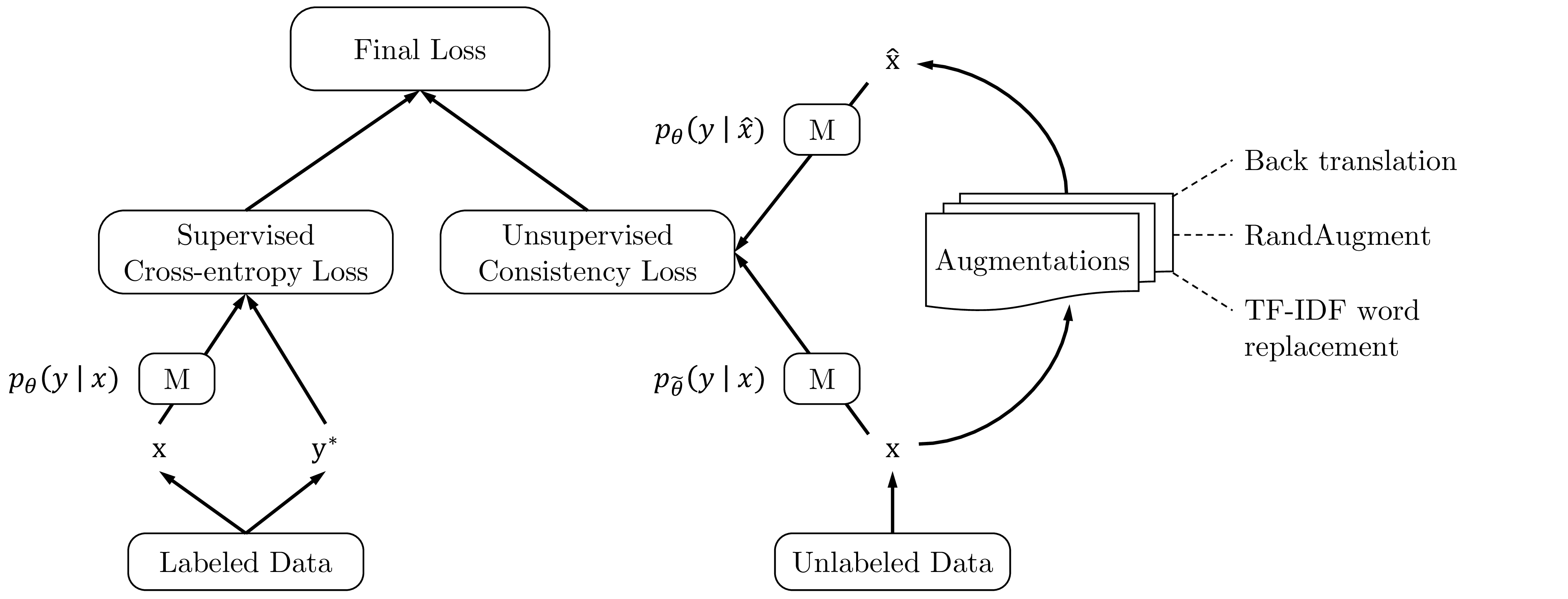
讨论: 在详细介绍本工作中使用的增强操作之前,我们首先从三个方面提供一些直观的认识,说明更先进的数据增强相对于早期工作中使用的简单增强如何能够提供额外的优势:
- 有效的噪声:在监督学习中表现出色的先进数据增强方法通常会生成逼真的增强示例,这些示例与原始示例具有相同的真实标签。 因此,可以放心地地鼓励原始未标记示例和增强的未标记示例之间的预测一致性。
- 多样化的噪声:先进的数据增强可以生成各种各样的示例,因为它可以对输入示例进行大量修改而无需更改其标签,而简单的高斯噪声仅可以进行局部更改。 鼓励在各种增强实例上保持一致性可以显着提高采样效率。
- 目标归纳偏差:不同的任务需要不同的归纳偏差。 在有监督的训练中行之有效的数据增强操作实质上提供了缺少的归纳偏差。
2.3 不同任务的增强策略
现在,我们详细介绍在本工作中使用的针对不同任务定制的增强方法。
用于图像分类的 RandAugment。 我们使用一种称为 RandAugment(Cubuk 等人,2019)的数据增强方法,该方法受 AutoAugment(Cubuk 等人,2018)的启发。 AutoAugment 使用一种搜索方法来组合 Python 图像库(PIL)中的所有图像处理转换,以找到良好的增强策略。 在 RandAugment 中,我们不使用搜索,而是从 PIL 中的同一组增强变换中统一采样。 换句话说,RandAugment 更简单并且不需要标记数据,因为不需要搜索最佳策略。
文本分类的反向翻译。 当作为一种增强方法使用时,回译(Sennrich 等人,2015;Edunov 等人,2018)指的是将语言 A 中的现有示例 x 翻译成另一种语言 B ,然后再将其翻译回 A ,以获得增强的示例 ˆx 的过程。 据 Yu 等人 (2018)观察,反向翻译可以在保留原始句子的语义的同时生成多种释义,从而大大提高了问答的性能。 在本例中,我们使用反向翻译来转述文本分类任务的训练数据。2
我们发现,转述的多样性比质量或有效性更为重要。 因此,我们采用具有可调 temperature 的随机采样来代替 beam search 生成。 如图 2 所示,反向翻译句子所产生的转述形式多样且具有相似的语义。 更具体地说,我们使用 WMT'14 的英语-法语翻译模型(双向)对每个句子进行反向翻译。 为了方便将来的研究,我们将反向翻译系统以及翻译检查点开源。
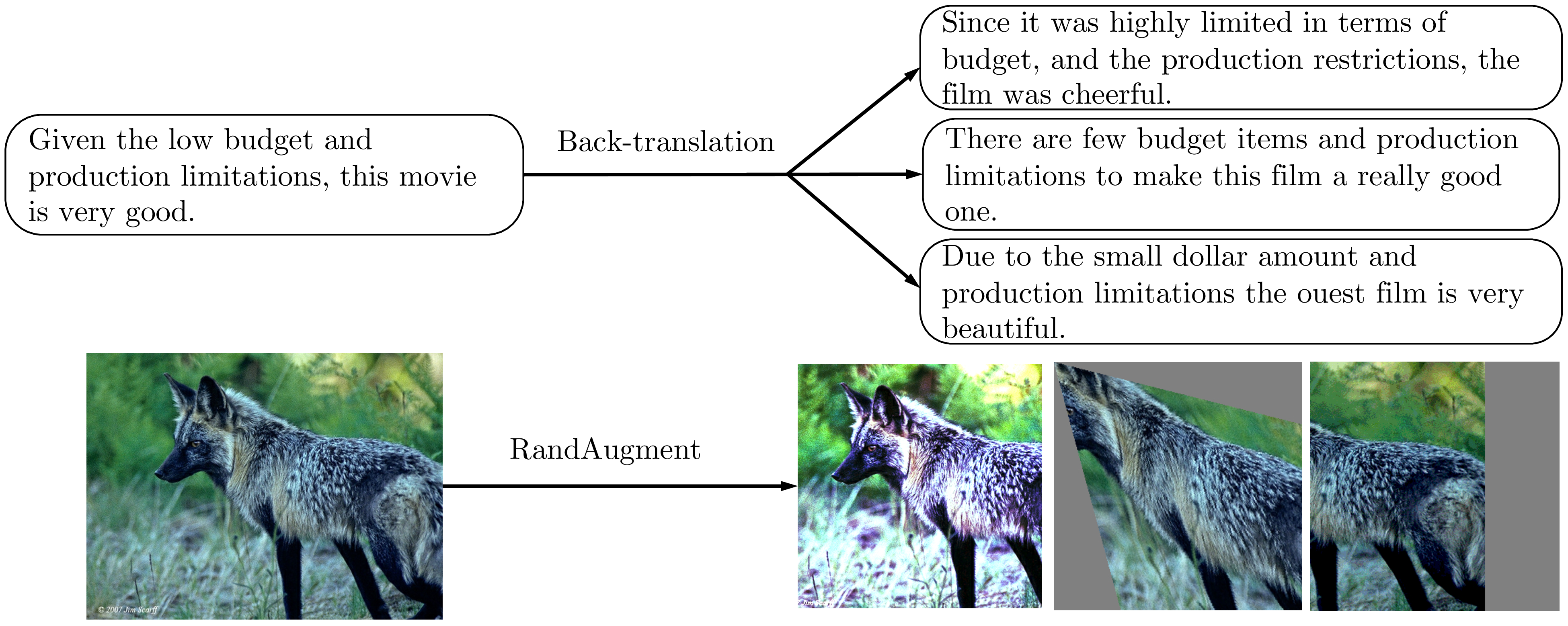
文本分类的 TF-IDF 单词替换。 虽然反向翻译擅长于维护句子的全局语义,但是几乎不控制将保留哪些单词。 此要求对于主题分类任务(例如 DBPedia)很重要,在该任务中,某些关键字比其他单词在确定主题时更具信息性。 因此,我们提出一种增强方法,用较低 TF-IDF 分数的单词替换无信息的单词,同时保留较高 TF-IDF 值的单词。 我们为读者提供附录 C 的详细说明。
2.4 针对低数据环境的训练信号退火
在半监督学习中,我们经常遇到这样一种情况,即未标记数据量和标记数据量之间存在巨大差距。 因此,该模型通常会快速拟合有限数量的标记数据,而仍不足以拟合未标记数据。 为了解决这一难题,我们引入了一种称为训练信号退火(TSA)的新训练技术,该技术会随着训练的进行逐渐释放带有标签示例的“训练信号”。 直观地讲,只有当模型对有标注示例的置信度低于一个预定义的阈值时,我们才会利用这个示例,而这个阈值会按照计划增加。 具体来说,在训练步骤 t 中,如果模型对正确类别的预测概率 pθ(y*∣x) 高于阈值 ηt,我们从损失函数中删除该示例。 假设 K 是类别数,通过将 ηt 从 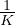 逐渐增加到 1,阈值 ηt 用作防止在容易标记的示例上过度训练的上限。
逐渐增加到 1,阈值 ηt 用作防止在容易标记的示例上过度训练的上限。
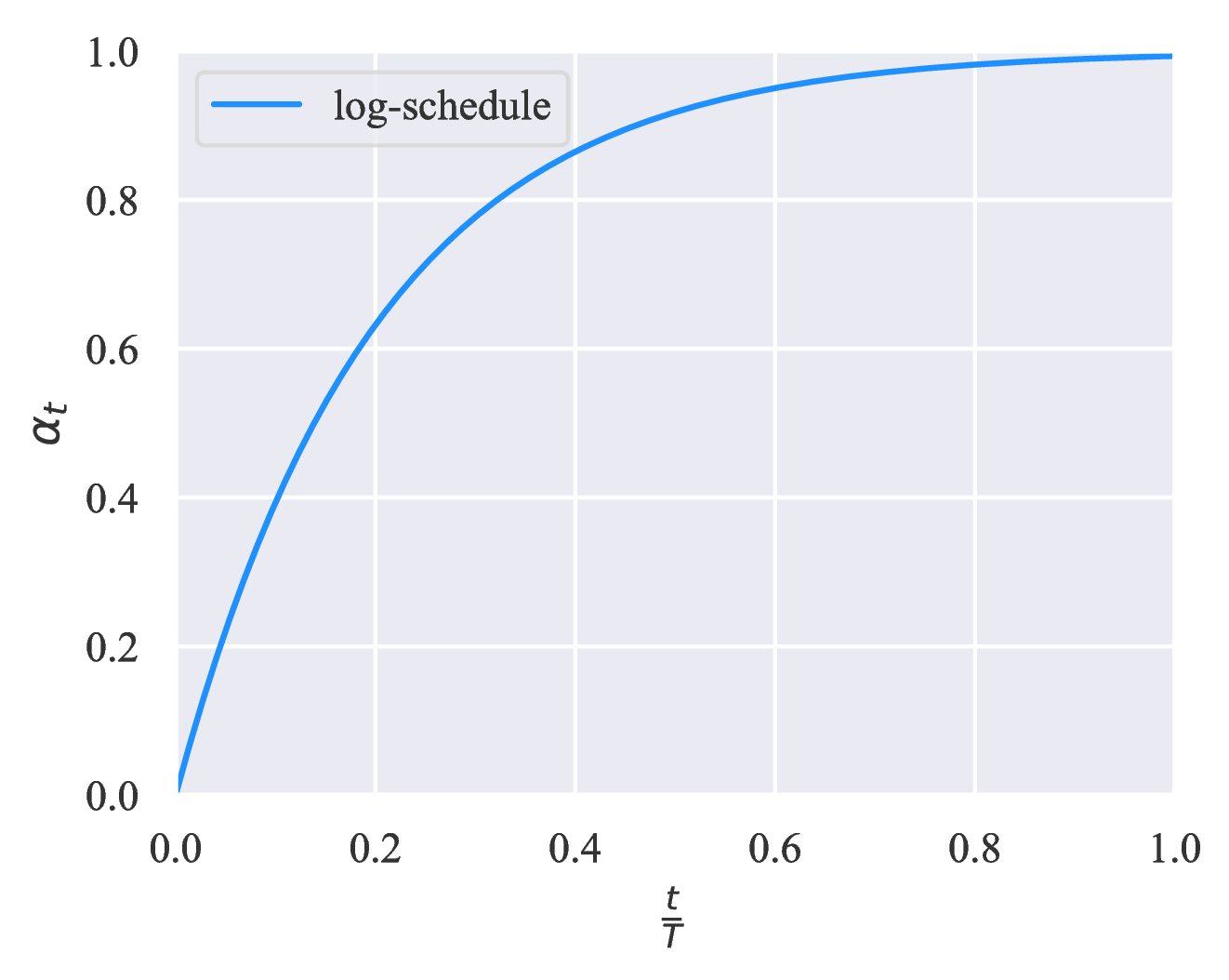
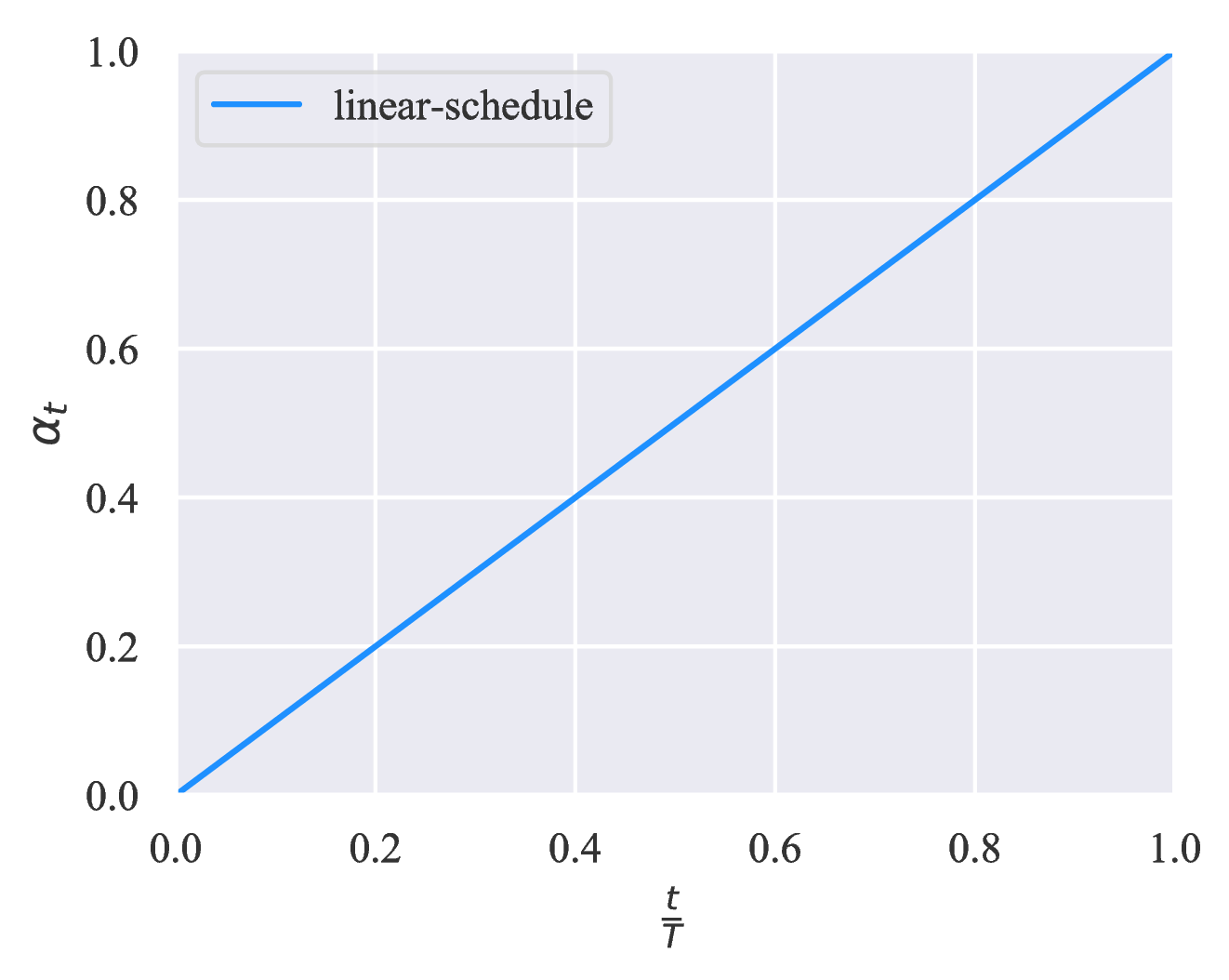
我们考虑不同应用场景下 ηt 的三个递增调度表。 假设 T 为训练步骤的总数,三个调度表显示在图 3 中。 直观地,当模型倾向于过拟合例如问题相对容易解决或标记示例的数量非常有限时,由于监督信号大部分在训练结束时释放,因此 exp-schedule 最合适。 相反,当模型不太可能过拟合时(例如,当我们有大量带有标签的示例时,或者当模型采用有效的正则化时),log-schedule 可以很好地发挥作用。
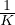 ) +
) + 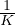 。 log、linear 和 exp schedules 的 αt 分别设置为 1 − exp(−
。 log、linear 和 exp schedules 的 αt 分别设置为 1 − exp(−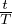 * 5)、
* 5)、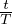 和 exp((
和 exp((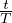 − 1) * 5) 。
− 1) * 5) 。3 实验
在本节中,我们将评估各种语言和视觉任务的 UDA。 对于语言任务,我们基于六个文本分类基准数据集,包括 IMDb、Yelp-2、Yelp-5、Amazon-2 和 Amazon-5 情感分类以及 DBPedia 主题分类(Maas 等人,2011 ;Zhang 等人,2015)。 对于视觉任务,我们使用两个经常用于比较半监督算法的较小数据集 CIFAR-10(Krizhevsky&Hinton,2009),SVHN(Netzer 等人,2011),以及更大规模的ImageNet(Deng 等人,2009)来测试 UDA 的可扩展性。 有关标记和未标记数据的详细信息以及实验的详细信息,我们请读者阅读附录E。
3.1 有监督与半监督性能之间的相关性
第一步,我们尝试验证 UDA 的基本概念,即在监督学习和半监督学习中,数据增强的有效性存在正相关关系。 基于 Yelp-5(一项语言任务)和 CIFAR-10(一项视觉任务),我们比较在完全监督或半监督环境下不同数据增强方法的性能。 对于 Yelp-5,除反向翻译外,我们还包括一种更简单的方法 Switchout(Wang 等人,2018),该方法用从词汇表中统一随机采样的词符替换一个词符。 对于 CIFAR-10,我们将 RandAugment 与两种更简单的方法进行比较:(1)cropping & flipping 增强和(2)Cutout。
根据这个设置,表 1 和表 2 显示数据增强效果在监督和半监督设置之间的强相关性。 这验证了我们的想法,即在监督学习中发现的更强的数据增强,在应用到半监督学习环境中时,总能带来更多的收益。
3.2 视觉半监督学习基准的算法比较
通过上面建立的相关性,我们要问的下一个问题是,与现有的半监督学习算法相比,UDA的性能如何。 为回答这个问题,我们将重点放在最常用的半监督学习基准 CIFAR-10 和 SVHN 上。
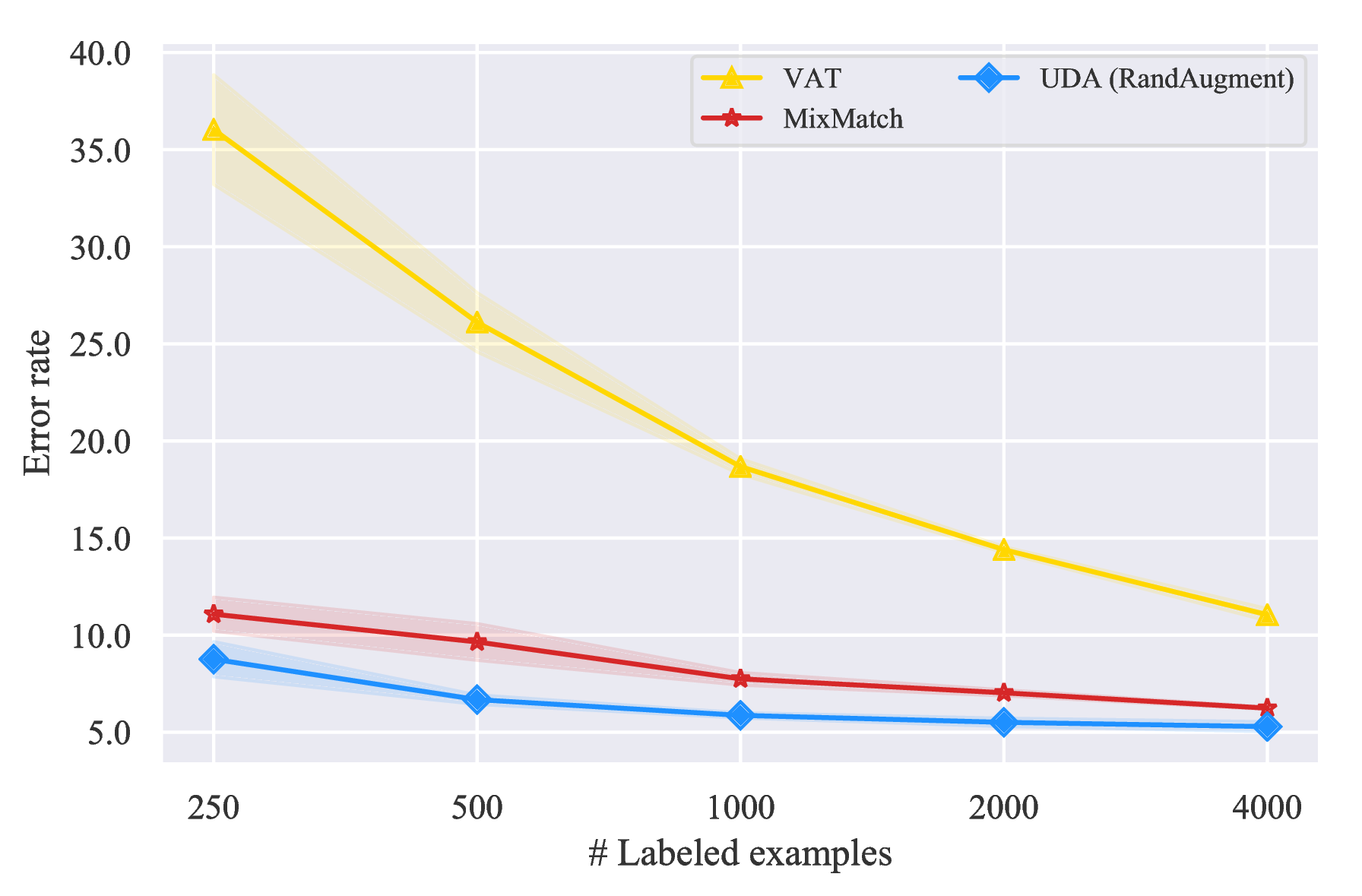
不同数据量的有标记数据。 首先,我们遵循(Oliver 等人,2018)中的设置,以 Wide-ResNet-28-2(Zagoruyko&Komodakis,2016;He 等人,2016)作为骨干模型,使用各种监督数据大小评估 UDA。 具体来说,我们将 UDA 与两个具有竞争性的基准进行比较:(1)虚拟对抗训练(VAT)(Miyato 等人,2018),一种在输入时产生对抗性高斯噪声的算法,以及(2)MixMatch(Berthelot 等人,2019),这是一项并行的工作,结合了先前在半监督学习中的进步。 比较结果显示在图 4 中,有两个主要观察结果。
- 首先,虽然标签数据的大小不同,UDA 始终以明显的优势超过两个基准。
- 另外,UDA 和 VAT 之间的性能差异显示了基于数据增强噪声的优越性。 UDA 和 VAT 的区别本质上是噪声过程。 VAT 产生的噪声通常以较高频率包含真实图像中不存在的人为图像,而数据增强通常会生成多种逼真的图像。
与已发表结果的比较 接下来,我们直接将 UDA 与先前发表的结果在不同模型架构下进行比较。 接着前面的工作,分别将 4k 和 1k 标记的示例用于 CIFAR-10 和 SVHN。 如表 3 所示,在相同的结构下,UDA 的性能明显优于所有已发表的结果,并且几乎与完全受监督的性能相匹配,后者使用 10 倍的标记示例。 这表明在视觉领域的一致性训练框架下,最先进数据增强的巨大潜力。
| 方法 | 模型 | #参数 | CIFAR-10(4k) | SVHN(1k) |
| Π-Model (Laine & Aila, 2016) | Conv-Large | 3.1M | 12.36 ± 0.31 | 4.82 ± 0.17 |
| Mean Teacher (Tarvainen & Valpola, 2017) | Conv-Large | 3.1M | 12.31 ± 0.28 | 3.95 ± 0.19 |
| VAT + EntMin (Miyato et al., 2018) | Conv-Large | 3.1M | 10.55 ± 0.05 | 3.86 ± 0.11 |
| SNTG (Luo et al., 2018) | Conv-Large | 3.1M | 10.93 ± 0.14 | 3.86 ± 0.27 |
| VAdD (Park et al., 2018) | Conv-Large | 3.1M | 11.32 ± 0.11 | 4.16 ± 0.08 |
| Fast-SWA (Athiwaratkun et al., 2018) | Conv-Large | 3.1M | 9.05 | - |
| ICT (Verma et al., 2019) | Conv-Large | 3.1M | 7.29 ± 0.02 | 3.89 ± 0.04 |
| Pseudo-Label (Lee, 2013) | WRN-28-2 | 1.5M | 16.21 ± 0.11 | 7.62 ± 0.29 |
| LGA + VAT (Jackson & Schulman, 2019) | WRN-28-2 | 1.5M | 12.06 ± 0.19 | 6.58 ± 0.36 |
| mixmixup (Hataya & Nakayama, 2019) | WRN-28-2 | 1.5M | 10 | - |
| ICT (Verma et al., 2019) | WRN-28-2 | 1.5M | 7.66 ± 0.17 | 3.53 ± 0.07 |
| MixMatch (Berthelot et al., 2019) | WRN-28-2 | 1.5M | 6.24 ± 0.06 | 2.89 ± 0.06 |
| Mean Teacher (Tarvainen & Valpola, 2017) | Shake-Shake | 26M | 6.28 ± 0.15 | - |
| Fast-SWA (Athiwaratkun et al., 2018) | Shake-Shake | 26M | 5.0 | - |
| MixMatch (Berthelot et al., 2019) | WRN | 26M | 4.95 ± 0.08 | - |
| UDA (RandAugment) | WRN-28-2 | 1.5M | 5.29 ± 0.25 | 2.55 ±0.09 |
| UDA (RandAugment) | Shake-Shake | 26M | 3.7 | - |
| UDA (RandAugment) | PyramidNet | 26M | 2.7 | - |
3.3 在文本分类数据集上评估
接下来,我们进一步评估语言领域中的 UDA。 此外,为了测试 UDA 是否可以与无监督表示学习成功结合使用(例如 BERT,Devlin 等人,2018),我们进一步考虑四种初始化方案:(a)随机 Transformer;(b)BERT BASE;(c)BERT LARGE;(d)BERT FINETUNE:BERT LARGE 在领域内未标记的数据 3 上进行微调。 在这四种初始化方案下,我们比较使用和不使用 UDA 的性能。
| 完全监督的基准结果 | |||||||
| 数据集 | IMDb | Yelp-2 | Yelp-5 | Amazon-2 | Amazon-5 | DBpedia | |
| (# Sup examples) | (25k) | (560k) | (650k) | (3.6m) | (3m) | (560k) | |
BERT前SOTA | 4.32 | 2.16 | 29.98 | 3.32 | 34.81 | 0.70 | |
BERT
LARGE | 4.51 | 1.89 | 29.32 | 2.63 | 34.17 | 0.64 | |
| 半监督的结果 | |||||||
初始化 | UDA | IMDb | Yelp-2 | Yelp-5 | Amazon-2 | Amazon-5 | DBpedia |
| (20) | (20) | (2.5k) | (20) | (2.5k) | (140) | ||
Random | ✗ | 43.27 | 40.25 | 50.80 | 45.39 | 55.70 | 41.14 |
| ✓ | 25.23 | 8.33 | 41.35 | 16.16 | 44.19 | 7.24 | |
BERT BASE | ✗ | 18.40 | 13.60 | 41.00 | 26.75 | 44.09 | 2.58 |
| ✓ | 5.45 | 2.61 | 33.80 | 3.96 | 38.40 | 1.33 | |
BERT LARGE | ✗ | 11.72 | 10.55 | 38.90 | 15.54 | 42.30 | 1.68 |
| ✓ | 4.78 | 2.50 | 33.54 | 3.93 | 37.80 | 1.09 | |
BERT FINETUNE | ✗ | 6.50 | 2.94 | 32.39 | 12.17 | 37.32 | - |
| ✓ | 4.20 | 2.05 | 32.08 | 3.50 | 37.12 | - | |
结果显示在表4中,在此我们要强调三个观察结果:
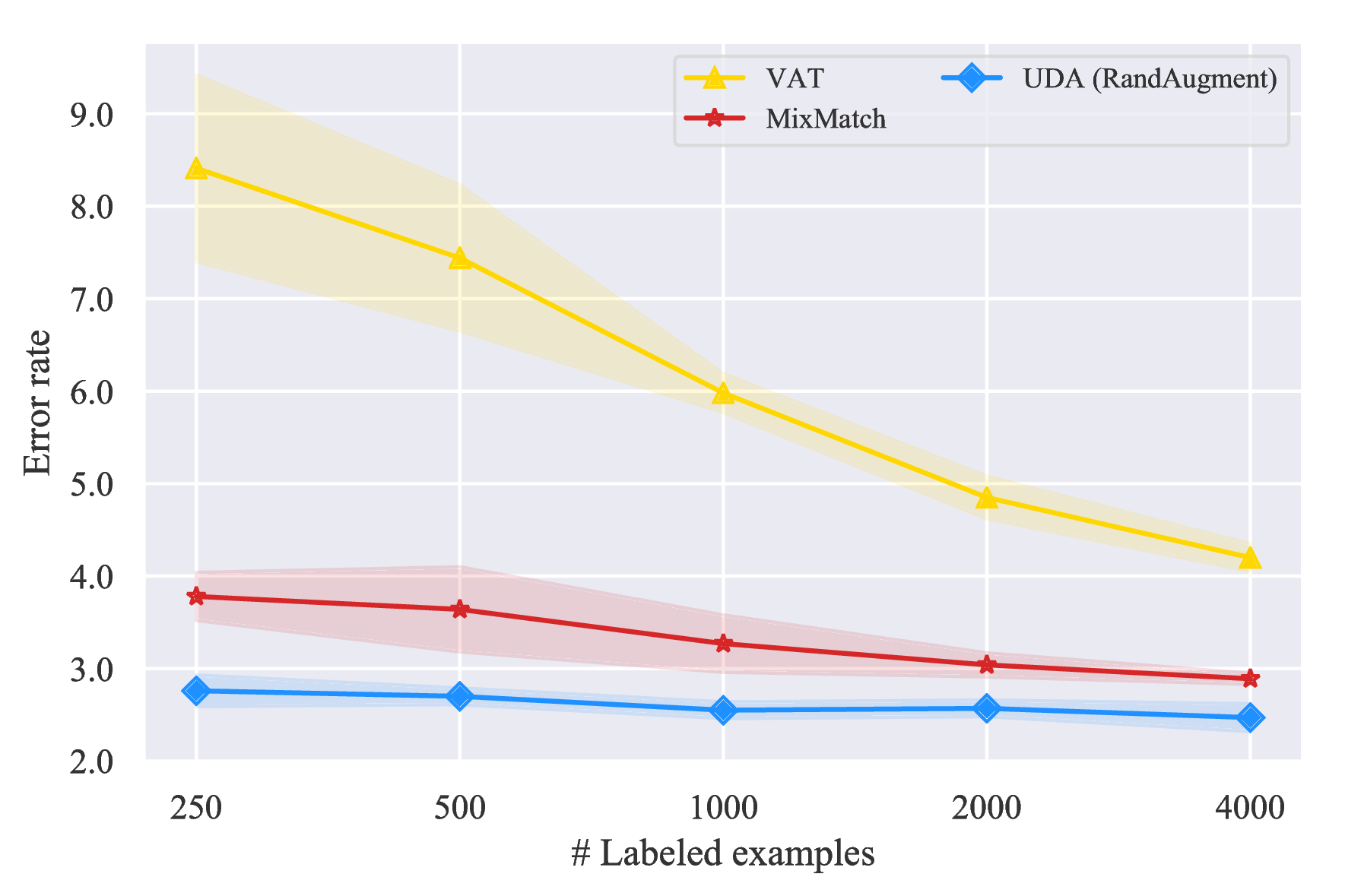
- 首先,即使标注的例子非常少,与使用完全监督数据训练的 SOTA 模型相比,UDA也能提供不错甚至有竞争力的性能。 特别是在二元情感分析任务上,在仅有 20 个监督示例的情况下,UDA 在 IMDb 上的表现优于之前用完全监督数据训练的 SOTA,在 Yelp-2 和 Amazon-2 上也有竞争力。
- 其次,UDA 是迁移学习/表示学习的补充。 我们可以看到,当使用 BERT 初始化并在领域内数据上进一步微调时,在 IMDb 上UDA 仍然可以将错误率从 6.50 显著降低到 4.20。
- 最后,我们还注意到,对于五类别情感分类任务,每类别有 500 个标签示例的 UDA 和在整个监督集上训练的 BERT 之间仍然存在明显的差距。 直观地讲,五类别情感分类比对应的二元分类困难得多。 这表明将来有进一步改进的空间。
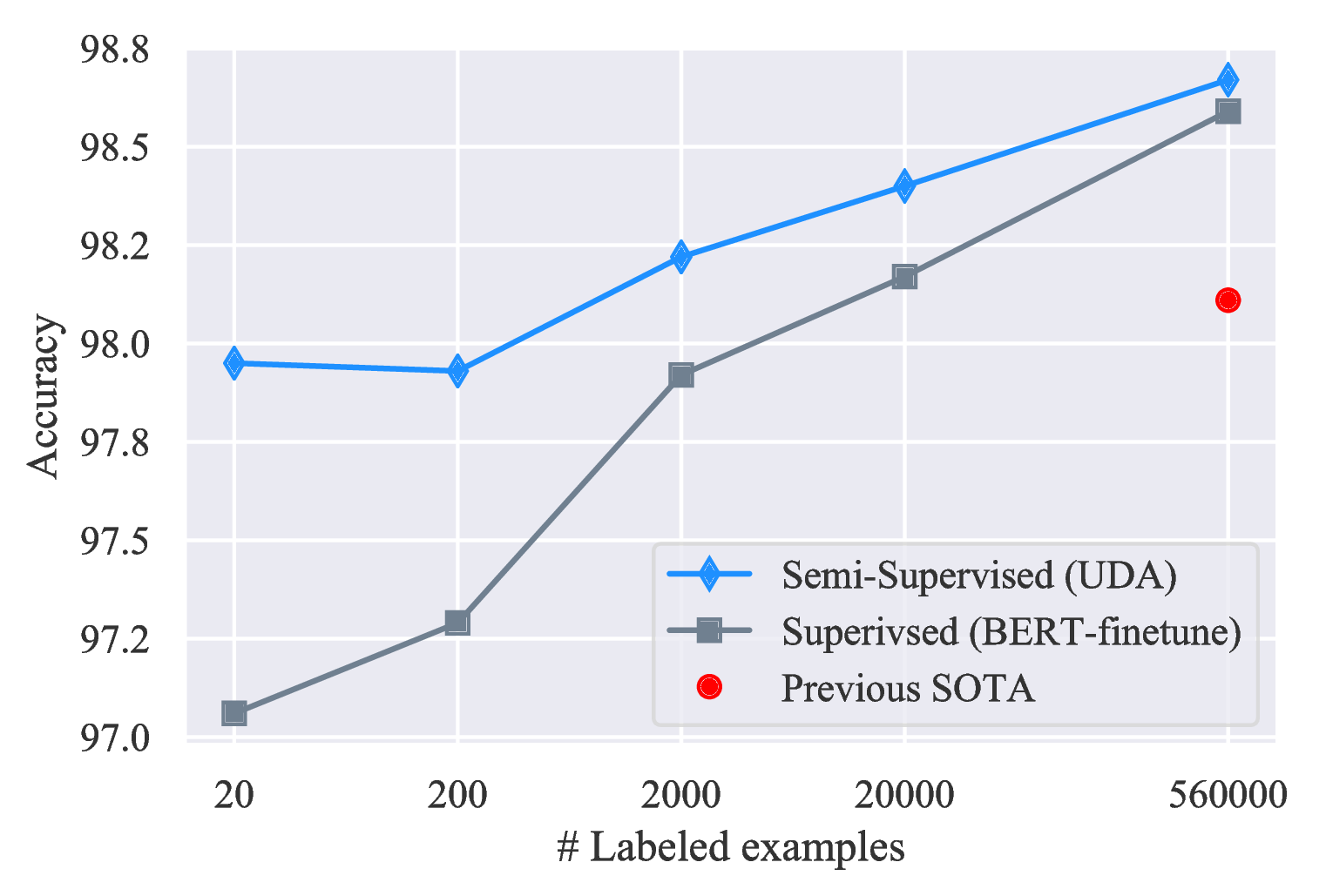
不同标签集大小的结果。 我们还在图 5 中显示,在 IMDb 和 Yelp-2 上,UDA 在所有标签数据大小的情况下都会带来一致的改进。
3.4 ImageNet 数据集上的可扩展性测试
然后,为了评估 UDA 是否可以扩展到规模较大、难度较高的问题,我们现在转向以 ResNet-50 为底层架构的 ImageNet 数据集。 具体来说,我们考虑两种性质不同的实验设置:
- 我们使用 ImageNet 监督数据的 10%,同时将所有其他数据用作未标记数据。 结果,未标记的示例完全在域内。
- 在第二种设置中,我们保留 ImageNet 中的所有图像作为监督数据。 然后,我们使用领域相关的数据过滤方法(有关详细信息,请参见附录B)从 JFT 中过滤出 130 万张图片(Hinton 等人,2015;Chollet,2017)。 因此,未标记的集合不一定是域内的。
结果总结在表5中。 在10%的数据设置和完整的数据设置中,UDA始终比监督基准带来可观的收益。 这表明 UDA 不仅可扩展,而且还可以利用领域外未标记的示例来改善模型性能。 与我们的工作并行的 S4L(Zhai 等人,2019b)和 CPC(Hénaff 等人,2019)也展示了对 ImageNet 的显着改进。
3.5 TSA的消融研究
最后,我们研究 TSA 对具有大量未标记数据的两个任务的影响:(a)Yelp-5,其中我们只有 2.5k 个带有标签的示例和 6m 个未带标签的示例。 (b)CIFAR-10,其中有 4k 个带标签的示例和 50k 个无标签的示例。 对于 Yelp-5,我们在本研究中使用随机初始化的 transformer 来排除预训练表示的因素。
如表 6 所示,在Yelp-5上,未标记数据比标记数据要多得多,与没有 TSA 的基准相比,TSA 将错误率从 50.81 降低到 41.35 。 更具体地说,当我们选择将监督的训练信号在训练结束延迟发布时达到最佳效果,即 exp-scheduled 可以达到最佳效果。 另一方面,就释放监督训练信号的速度而言,linear-schedule 是 CIFAR-10 的最佳选择,其未标记数据的数量与监督数据的数量相当。
4 相关工作
一致性训练中的现有工作确实利用了数据增强(Laine&Aila,2016;Sajjadi 等人,2016);但是,它们仅应用弱增强方法,例如随机转换和裁剪。 与我们的工作并行的 ICT(Verma 等人,2019)和 MixMatch(Berthelot 等人,2019)也显示了半监督学习方面的改进。 这些方法在诸如翻转和裁剪之类的简单增强方法的基础上,采用混合方法(Zhang 等人,2017);相反,UDA 强调使用最新的数据增强功能,从而在 CIFAR-10 和 SVHN上 获得明显更好的结果。 此外,UDA 还适用于语言领域,还可以很好地扩展到更具挑战性的视觉数据集,例如 ImageNet。
一致性训练家族中的其他工作在噪声的定义上有很大不同:Pseudo-ensemble(Bachman 等人,2014)直接应用高斯噪声和 Dropout 噪声;VAT (Miyato 等人,2018;2016)通过近似模型最敏感的输入空间的变化方向来定义噪声;Cross-view 训练(Clark 等人,2018)屏蔽部分输入数据。 除了在输入示例和隐藏的表示形式上强制一致性之外,另一研究领域在模型参数空间上强制了一致性。 在这个类别的工作包括 Mean Teacher (Tarvainen & Valpola, 2017)、fast-Stochastic Weight Averaging (Athiwaratkun 等人,2018) 和 Smooth Neighbors on Teacher Graphs (Luo 等人,2018)。 有关相关工作的完整版本,请参见附录D。
5 结论
在本论文中,我们表明数据增强和半监督学习之间有着很好的联系:更好的数据增强可以带来明显更好的半监督学习。 我们的方法 UDA 利用在监督学习中发现的最先进的数据增强技术来生成多样和逼真的噪声,并使模型对这些噪声维持一致性。 对于文本,UDA 与表示学习(如 BERT)结合得很好,在低数据体系下非常有效,在 IMDb 上只用 20 个示例就能达到最先进的性能。 在视觉方面,UDA 的表现明显优于之前的工作,几乎与在完整标注集上训练的完全监督模型的性能相匹配,而完全监督模型的性能要大一个数量级。 最后,在我们拥有大量监督数据的 ImageNet 上,UDA 可以有效地利用领域外非标记数据,实现性能的提升。 我们希望 UDA 能够鼓励未来的研究将先进的监督增强转移到不同任务的半监督环境中。
致谢
我们要感谢Hieu Pham,Adams Wei Yu,Yilin Yang和Ekin Dogus Cubuk在项目不同阶段对作者的不懈帮助,并感谢Colin Raffel指出了我们的工作与以前的工作之间的联系。 我们还要感谢Olga Wichrowska,Barret Zoph,Jiateng Xie,Guokun Lai,Yulun Du,David Berthelot,Avital Oliver,Trieu Trinh,Ran Zhao,Ola Spyra,Brandon Yang,Daiyi Peng,Andrew Dai,Samy Bengio,Jeff Dean和Google Brain团队进行深入的讨论并为这项工作提供支持。 最后,我们感谢匿名审稿人的宝贵反馈。
参考
Ben Athiwaratkun, Marc Finzi, Pavel Izmailov, and Andrew Gordon Wilson. There are many consistent explanations of unlabeled data: Why you should average. 2018.
Philip Bachman, Ouais Alsharif, and Doina Precup. Learning with pseudo-ensembles. In Advances in Neural Information Processing Systems, pp. 3365–3373, 2014.
David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin Raffel. Mixmatch: A holistic approach to semi-supervised learning. arXiv preprint arXiv:1905.02249, 2019.
Yair Carmon, Aditi Raghunathan, Ludwig Schmidt, Percy Liang, and John C Duchi. Unlabeled data improves adversarial robustness. arXiv preprint arXiv:1905.13736, 2019.
Olivier Chapelle, Bernhard Scholkopf, and Alexander Zien. Semi-supervised learning (chapelle, o. et al., eds.; 2006)[book reviews]. IEEE Transactions on Neural Networks, 20(3):542–542, 2009.
François Chollet. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1251–1258, 2017.
Kevin Clark, Minh-Thang Luong, Christopher D Manning, and Quoc V Le. Semi-supervised sequence modeling with cross-view training. arXiv preprint arXiv:1809.08370, 2018.
Ronan Collobert and Jason Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, pp. 160–167. ACM, 2008.
Ekin D Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V Le. Autoaugment: Learning augmentation policies from data. arXiv preprint arXiv:1805.09501, 2018.
Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical data augmentation with no separate search. arXiv preprint, 2019.
Andrew M Dai and Quoc V Le. Semi-supervised sequence learning. In Advances in neural information processing systems, pp. 3079–3087, 2015.
Zihang Dai, Zhilin Yang, Fan Yang, William W Cohen, and Ruslan R Salakhutdinov. Good semi-supervised learning that requires a bad gan. In Advances in Neural Information Processing Systems, pp. 6510–6520, 2017.
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pp. 248–255. Ieee, 2009.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
Sergey Edunov, Myle Ott, Michael Auli, and David Grangier. Understanding back-translation at scale. arXiv preprint arXiv:1808.09381, 2018.
Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Advances in neural information processing systems, pp. 529–536, 2005.
Awni Hannun, Carl Case, Jared Casper, Bryan Catanzaro, Greg Diamos, Erich Elsen, Ryan Prenger, Sanjeev Satheesh, Shubho Sengupta, Adam Coates, et al. Deep speech: Scaling up end-to-end speech recognition. arXiv preprint arXiv:1412.5567, 2014.
Ryuichiro Hataya and Hideki Nakayama. Unifying semi-supervised and robust learning by mixup. ICLR The 2nd Learning from Limited Labeled Data (LLD) Workshop, 2019.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
Xuanli He, Gholamreza Haffari, and Mohammad Norouzi. Sequence to sequence mixture model for diverse machine translation. arXiv preprint arXiv:1810.07391, 2018.
Olivier J Hénaff, Ali Razavi, Carl Doersch, SM Eslami, and Aaron van den Oord. Data-efficient image recognition with contrastive predictive coding. arXiv preprint arXiv:1905.09272, 2019.
Alex Hernández-García and Peter König. Data augmentation instead of explicit regularization. arXiv preprint arXiv:1806.03852, 2018.
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pp. 328–339, 2018.
Weihua Hu, Takeru Miyato, Seiya Tokui, Eiichi Matsumoto, and Masashi Sugiyama. Learning discrete representations via information maximizing self-augmented training. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1558–1567. JMLR. org, 2017.
Jacob Jackson and John Schulman. Semi-supervised learning by label gradient alignment. arXiv preprint arXiv:1902.02336, 2019.
Rie Johnson and Tong Zhang. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pp. 562–570, 2017.
Durk P Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi-supervised learning with deep generative models. In Advances in neural information processing systems, pp. 3581–3589, 2014.
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
Wouter Kool, Herke van Hoof, and Max Welling. Stochastic beams and where to find them: The gumbel-top-k trick for sampling sequences without replacement. arXiv preprint arXiv:1903.06059, 2019.
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, Citeseer, 2009.
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pp. 1097–1105, 2012.
Samuli Laine and Timo Aila. Temporal ensembling for semi-supervised learning. arXiv preprint arXiv:1610.02242, 2016.
Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on Challenges in Representation Learning, ICML, volume 3, pp. 2, 2013.
Davis Liang, Zhiheng Huang, and Zachary C Lipton. Learning noise-invariant representations for robust speech recognition. In 2018 IEEE Spoken Language Technology Workshop (SLT), pp. 56–63. IEEE, 2018.
Yucen Luo, Jun Zhu, Mengxi Li, Yong Ren, and Bo Zhang. Smooth neighbors on teacher graphs for semi-supervised learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8896–8905, 2018.
Lars Maaløe, Casper Kaae Sønderby, Søren Kaae Sønderby, and Ole Winther. Auxiliary deep generative models. arXiv preprint arXiv:1602.05473, 2016.
Andrew L Maas, Raymond E Daly, Peter T Pham, Dan Huang, Andrew Y Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th annual meeting of the association for computational linguistics: Human language technologies-volume 1, pp. 142–150. Association for Computational Linguistics, 2011.
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 43–52. ACM, 2015.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119, 2013.
Takeru Miyato, Andrew M Dai, and Ian Goodfellow. Adversarial training methods for semi-supervised text classification. arXiv preprint arXiv:1605.07725, 2016.
Takeru Miyato, Shin-ichi Maeda, Shin Ishii, and Masanori Koyama. Virtual adversarial training: a regularization method for supervised and semi-supervised learning. IEEE transactions on pattern analysis and machine intelligence, 2018.
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011.
Avital Oliver, Augustus Odena, Colin A Raffel, Ekin Dogus Cubuk, and Ian Goodfellow. Realistic evaluation of deep semi-supervised learning algorithms. In Advances in Neural Information Processing Systems, pp. 3235–3246, 2018.
Daniel S Park, William Chan, Yu Zhang, Chung-Cheng Chiu, Barret Zoph, Ekin D Cubuk, and Quoc V Le. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv preprint arXiv:1904.08779, 2019.
Sungrae Park, JunKeon Park, Su-Jin Shin, and Il-Chul Moon. Adversarial dropout for supervised and semi-supervised learning. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp. 1532–1543, 2014.
Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. arXiv preprint arXiv:1802.05365, 2018.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. URL https://s3-us-west-2. amazonaws. com/openai-assets/research-covers/languageunsupervised/language understanding paper. pdf, 2018.
Antti Rasmus, Mathias Berglund, Mikko Honkala, Harri Valpola, and Tapani Raiko. Semi-supervised learning with ladder networks. In Advances in neural information processing systems, pp. 3546–3554, 2015.
Devendra Singh Sachan, Manzil Zaheer, and Ruslan Salakhutdinov. Revisiting lstm networks for semi-supervised text classification via mixed objective function. 2018.
Mehdi Sajjadi, Mehran Javanmardi, and Tolga Tasdizen. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. In Advances in Neural Information Processing Systems, pp. 1163–1171, 2016.
Julian Salazar, Davis Liang, Zhiheng Huang, and Zachary C Lipton. Invariant representation learning for robust deep networks. In Workshop on Integration of Deep Learning Theories, NeurIPS, 2018.
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Advances in neural information processing systems, pp. 2234–2242, 2016.
Rico Sennrich, Barry Haddow, and Alexandra Birch. Improving neural machine translation models with monolingual data. arXiv preprint arXiv:1511.06709, 2015.
Tianxiao Shen, Myle Ott, Michael Auli, and Marc’Aurelio Ranzato. Mixture models for diverse machine translation: Tricks of the trade. arXiv preprint arXiv:1902.07816, 2019.
Patrice Y Simard, Yann A LeCun, John S Denker, and Bernard Victorri. Transformation invariance in pattern recognition—tangent distance and tangent propagation. In Neural networks: tricks of the trade, pp. 239–274. Springer, 1998.
Robert Stanforth, Alhussein Fawzi, Pushmeet Kohli, et al. Are labels required for improving adversarial robustness? arXiv preprint arXiv:1905.13725, 2019.
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in neural information processing systems, pp. 1195–1204, 2017.
Trieu H Trinh, Minh-Thang Luong, and Quoc V Le. Selfie: Self-supervised pretraining for image embedding. arXiv preprint arXiv:1906.02940, 2019.
Vikas Verma, Alex Lamb, Juho Kannala, Yoshua Bengio, and David Lopez-Paz. Interpolation consistency training for semi-supervised learning. arXiv preprint arXiv:1903.03825, 2019.
Xinyi Wang, Hieu Pham, Zihang Dai, and Graham Neubig. Switchout: an efficient data augmentation algorithm for neural machine translation. arXiv preprint arXiv:1808.07512, 2018.
Jason Weston, Frédéric Ratle, Hossein Mobahi, and Ronan Collobert. Deep learning via semi-supervised embedding. In Neural Networks: Tricks of the Trade, pp. 639–655. Springer, 2012.
Zhilin Yang, William W Cohen, and Ruslan Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. arXiv preprint arXiv:1603.08861, 2016.
Zhilin Yang, Junjie Hu, Ruslan Salakhutdinov, and William W Cohen. Semi-supervised qa with generative domain-adaptive nets. arXiv preprint arXiv:1702.02206, 2017.
Mang Ye, Xu Zhang, Pong C Yuen, and Shih-Fu Chang. Unsupervised embedding learning via invariant and spreading instance feature. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6210–6219, 2019.
Adams Wei Yu, David Dohan, Minh-Thang Luong, Rui Zhao, Kai Chen, Mohammad Norouzi, and Quoc V Le. Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv preprint arXiv:1804.09541, 2018.
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
Runtian Zhai, Tianle Cai, Di He, Chen Dan, Kun He, John Hopcroft, and Liwei Wang. Adversarially robust generalization just requires more unlabeled data. arXiv preprint arXiv:1906.00555, 2019a.
Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. S
4l : Self−supervisedsemi−supervisedlearning.InProceedings of the IEEE international conference on computer vision,2019b.
Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification. In Advances in neural information processing systems, pp. 649–657, 2015.
Xiaojin Zhu, Zoubin Ghahramani, and John D Lafferty. Semi-supervised learning using gaussian fields and harmonic functions. In Proceedings of the 20th International conference on Machine learning (ICML-03), pp. 912–919, 2003.
A 更多实验
A.1 RandAugment 的消融研究
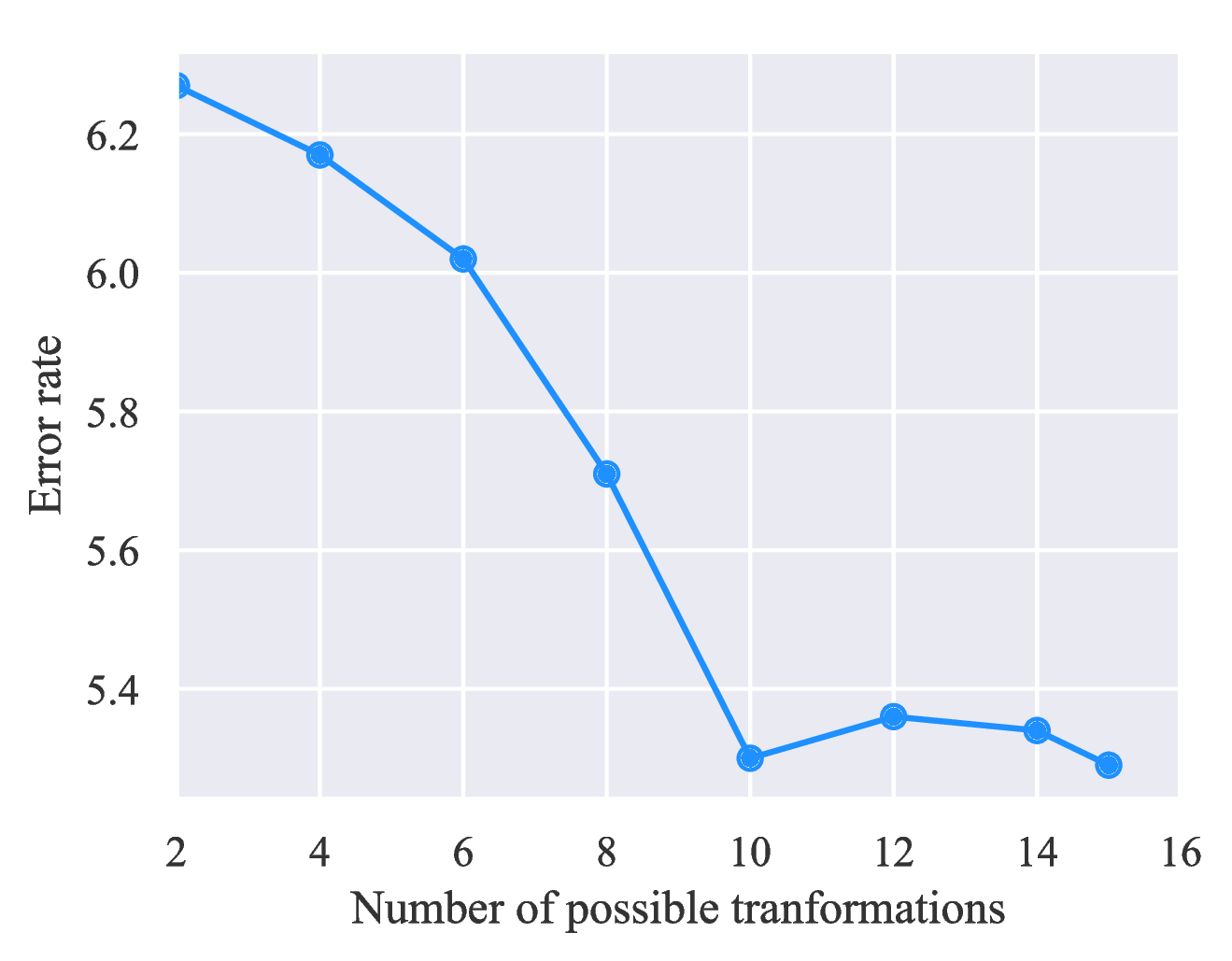
我们假设RandAugment的成功应该归功于扩增变换的多样性,因为RandAugment对于多个不同的数据集都非常有效,而RandAugment不需要搜索算法来找出最有效的策略。 为了验证这一假设,我们在限制RandAugment中使用的可能转换数量时测试UDA的性能。 如图6所示,随着我们使用更多的增强变换,性能逐渐提高。
A.2 在CIFAR-10和SVHN上具有不同标签集大小的结果
CIFAR-10在表7中,我们显示了图4a t4的比较方法的结果>和伪标签(Lee,2013),Π-模型(Laine&Aila,2016),平均教师( Tarvainen&Valpola,2017)。 在有或没有RandAugment的情况下,使用50,000个示例进行的完全监督学习的错误率分别为5.36和4.23。 MixMatch报告了基准模型的性能(Berthelot等人,2019)。
为确保MixMatch报告的性能与我们的结果可比,我们在代码库中重新实现MixMatch,发现原始论文中的结果具有可比性,但比我们的重新实现稍好,这使得UDA的竞争更具竞争力。 例如,我们对MixMatch的重新实现实现了4,000和2,000个示例的错误率分别为7.00 ± 0.59和7.39 ± 0.11。 MixMatch使用不同的模型实现,并在模型参数上采用指数移动平均值(EMA),而我们的实现不使用EMA。
| Methods / # Sup | 250 | 500 | 1,000 | 2,000 | 4,000 |
| Pseudo-Label | 49.98 ± 1.17 | 40.55 ± 1.70 | 30.91 ± 1.73 | 21.96 ± 0.42 | 16.21 ± 0.11 |
| Π-Model | 53.02 ± 2.05 | 41.82 ± 1.52 | 31.53 ± 0.98 | 23.07 ± 0.66 | 17.41 ± 0.37 |
| Mean Teacher | 47.32 ± 4.71 | 42.01 ± 5.86 | 17.32 ± 4.00 | 12.17 ± 0.22 | 10.36 ± 0.25 |
| VAT | 36.03 ± 2.82 | 26.11 ± 1.52 | 18.68 ± 0.40 | 14.40 ± 0.15 | 11.05 ± 0.31 |
| MixMatch | 11.08 ± 0.87 | 9.65 ± 0.94 | 7.75 ± 0.32 | 7.03 ± 0.15 | 6.24 ± 0.06 |
| UDA (RandAugment) | 8.76 ±0.90 | 6.68 ±0.24 | 5.87 ±0.13 | 5.51 ±0.21 | 5.29 ±0.25 |
SVHN在表8中,我们类似地显示了图4b的比较方法的结果。和上述方法的结果。 在使用或不使用RandAugment的情况下,使用73,257个示例进行的完全监督学习可实现2.84和2.28的错误率。 MixMatch报告了基准模型的性能(Berthelot等人,2019)。 我们对MixMatch的重新实现也导致了与报告的错误率相当但更高的错误率。
| Methods / # Sup | 250 | 500 | 1,000 | 2,000 | 4,000 |
| Pseudo-Label | 21.16 ± 0.88 | 14.35 ± 0.37 | 10.19 ± 0.41 | 7.54 ± 0.27 | 5.71 ± 0.07 |
| Π-Model | 17.65 ± 0.27 | 11.44 ± 0.39 | 8.60 ± 0.18 | 6.94 ± 0.27 | 5.57 ± 0.14 |
| Mean Teacher | 6.45 ± 2.43 | 3.82 ± 0.17 | 3.75 ± 0.10 | 3.51 ± 0.09 | 3.39 ± 0.11 |
| VAT | 8.41 ± 1.01 | 7.44 ± 0.79 | 5.98 ± 0.21 | 4.85 ± 0.23 | 4.20 ± 0.15 |
| MixMatch | 3.78 ± 0.26 | 3.64 ± 0.46 | 3.27 ± 0.31 | 3.04 ± 0.13 | 2.89 ± 0.06 |
| UDA (RandAugment) | 2.76 ±0.17 | 2.70 ±0.09 | 2.55 ±0.09 | 2.57 ±0.09 | 2.47 ±0.15 |
B 其它训练技术
虽然 UDA 通常效果很好,但是如果不仔细处理,一致性训练中会遇到一些实际问题,这些问题可能会削弱性能提升。 本节介绍针对一些常见问题的其他技术。
锐化预测。 熵最小化(Grandvalet&Bengio,2005)已被证明在诸如 VAT 的半监督学习方法中有效(Miyato 等人,2018)。 要在我们的方法中应用熵最小化,我们只需向目标添加一个损失项,以对未标记示例的预测分布进行正则化以使其具有较低的熵。 另外,当标记示例的数量极少时,我们发现将当前模型不确定的示例屏蔽起来,并在计算未标记示例的目标分布时使用较低的 Softmax 温度会有所帮助。 具体而言,在每个 minibatch 中,仅对分类类别中最高概率大于阈值的示例计算一致性损失项。
领域相关数据过滤。 理想情况下,我们希望利用领域外未标记的数据,因为通常它更容易收集,但是领域外数据的类分布与领域内数据的类分布不匹配,这可能导致如果直接使用会降低性能(Oliver 等人,2018)。 为了获得与当前任务领域相关的数据,我们采用了一种常见的检测领域外数据的技术。 我们使用在领域内数据上训练的基线模型来推断领域外大型数据集中的数据标签,并选择该模型最有信心的示例。 具体来说,对于每个类别,我们基于该类别中的分类概率对所有示例进行排序,然后选择概率最高的示例。
C 不同任务的进一步增强策略
数据增强的多样性和有效性之间的权衡。 尽管如 2.2 所述,最先进的数据增强方法可以生成各种有效的增强示例,但多样性和有效性之间还是需要权衡的,因为多样性是通过更改原始示例的某个部分来实现的容,这自然会导致更改真实标签的风险。 我们发现调整数据增强方法的多样性和有效性之间的权衡是有益的。 对于文本分类,我们调整随机采样的温度。 一方面,当我们使用温度 0 时,通过随机采样进行解码会退化为贪婪解码,并生成完全有效但完全相同的转述。 另一方面,当我们使用 1 的温度时,随机采样会生成非常多样化但几乎不可读的转述。 我们发现将 Softmax 温度设置为 0.7、0.8 或 0.9 可获得最佳性能。
RandAugment详细信息。 在我们的RandAugment的实现中,每个子策略都由两个操作组成,其中每个操作由特定于该操作的转换名称,概率和大小表示。 例如,子策略可以是 [(Sharpness, 0.6, 2), (Posterize, 0.3, 9)]。
对于每个操作,我们从 15 个可能的转换中随机采样一个转换,幅值为 [1,10) 并将概率固定为 0.5。 具体来说,我们从以下 15 转换中进行采样:Invert, Cutout, Sharpness, AutoContrast, Posterize, ShearX, TranslateX, TranslateY, ShearY, Rotate, Equalize, Contrast, Color, Solarize, Brightness。 我们发现此设置在我们的首次尝试中效果很好,并且没有调整幅度范围和概率。 调整这些超参数可能会导致精度进一步提高。
基于TF-IDF的单词替换详的细信息。 理想情况下,我们希望增强方法能够生成多样且有效的示例。 因此,增强设计成保留关键词,用其他无信息的词代替无信息的词。 我们使用 BERT 的单词 tokenizer,因为 BERT 首先将句子标记为单词序列,然后将单词标记为子单词,尽管该模型使用子单词作为输入。
具体来说,假设 IDF(w) 是单词 w 在整个语料上计算出的 IDF 分数,TF(w) 是单词 w 在句子中的 TF 分数。 我们计算 TF-IDF 分数为 TFIDF(w) = TF(w)IDF(w)。 假设一个句子 x 中最大的 TF-IDF 值是 C= maxiTFIDF(xi)。 为了使替换单词的概率与其 TF-IDF 分数负相关,我们将概率设置为 min(p(C− TFIDF(xi)) ∕ Z,1),其中 p 是控制参数幅度的超参数,Z= ∑i(C− TFIDF(xi)) ∕ |x| 是平均分数。 对于在DBPedia上进行的实验,p设置为0.7。
当一个单词被替换时,我们从整个词汇表中抽取另一个单词进行替换。 直观地讲,采样单词不应作为关键字,以防止更改句子的正确标签。 为了衡量一个单词是否是关键词,我们计算整个语料库中每个单词的分数。 具体来说,我们将得分计算为 S(w) = freq(w)IDF(w) ,其中 freq(w) 是单词 w 在整个语料库上的频率。 我们设置单词 w 的采样频率为 (maxw′S(w′)−S(w)) ∕ Z′,其中 Z′= ∑wmaxw′S(w′)−S(w) 是一个正则化项。
D 相关工作的扩展
半监督学习。 由于半监督学习(SSL)的悠久历史,我们建议读者参考(Chapelle 等人,2009)进行一般回顾。 近来,许多人努力将经典思想翻新为深度神经网络方式。 例如,基于图的标签传播(Zhu 等人,2003)已通过图嵌入(Weston 等人,2012;Yang 等人,2016)和后来的图卷积(Kipf&Welling,2016)扩展到神经网络方法。 同样,借助变分自动编码框架和强化算法,基于具有潜在目标变量的经典图模型的 SSL 方法也可以利用深度架构(Kingma 等人,2014; Maaløe 等人,2016;Yang 等人,2017)。 除了直接扩展之外,还发现训练神经网络分类器将领域外示例分类为其他类别(Salimans 等人,2016)在实践中非常有效。 后来, Dai 等人 (2017)表明,这可以看作是低密度分离的实例。
除了在噪杂的输入示例和隐藏的表示形式上加强一致性之外,另一研究领域在不同的模型参数下增强了一致性,这是对我们方法的补充。 例如,Mean Teacher(Tarvainen&Valpola,2017)维护了一个教师模型,其参数是学生模型参数的集合,并强制了这两个模型的预测之间的一致性。 最近, Athiwaratkun等。 (2018)提出了快速SWA,它通过鼓励模型探索一组合理的参数来改善平均教师。 除了参数级一致性外,SNTG(Luo et al。,2018)还通过在未标记示例之间构建相似度图来增强输入级一致性。
数据增强。 与我们的工作还相关的是数据增强研究领域。 除了 2.1节 中提到的传统方法和两种数据增强方法外,最近的一种方法 MixUp(Zhang 等人,2017)不仅限于从单个数据点进行数据增强,而是执行数据对的插值来实现增强。 最近,Hernández-García&König(2018)表明,数据增强可以被视为类似于 Dropout 的一种显式正则化方法。
多样的反向翻译。 在我们的文本分类实验中,由反向翻译产生的多样化转述是性能显著提升的关键因素。 我们使用随机采样代替 beam search 来进行解码,类似于 Edunov 等人 (2018)。 最近也有关于生成多种翻译(He 等人,2018;Shen 等人,2019;Kool 等人,2019)用作数据增强时可能会导致进一步改进的工作。
无监督的表示学习。 除了半监督学习之外,无监督表示学习还提供了另一种利用无监督数据的方法。 Collobert&Weston(2008)证明,语言建模学习的词嵌入可以显着提高语义角色标记的性能。 后来,在 Word2Vec (Mikolov 等人,2013)和 Glove (Pennington 等人,2014)中,对词嵌入的预训练进行了简化和大幅度的扩展。 最近,Dai&Le(2015); Peters 等人 (2018); Radford 等人 (2018); Howard&Ruder(2018); Devlin 等人 (2018)表明,使用语言建模和去噪自动编码的预训练可以显着改善语言领域中的许多任务。 人们对视觉的自我监督学习也越来越感兴趣(Zhai 等人,2019b;Hénaff 等人,2019;Trinh 等人,2019)。
其他领域的一致性训练。 一致性训练的类似想法也已应用于其他领域。 例如,最近,在无监督数据上加强对抗一致性也被证明有助于对抗鲁棒性(Stanforth等人,2019; Zhai等人,2019a; Carmon等人,2019)。 事实证明,强制数据增强的一致性对于表示学习非常有效(Hu 等人,2017; Ye 等人,2019)。 不变表示学习(Liang等人,2018; Salazar等人,2018)不仅将一致性损失应用于预测分布,而且还将其应用于表示,并且已经证明语音识别方面的重大改进。
E 实验详细信息
E.1 文本分类
数据集。 在我们的半监督设置中,有标注的示例从完整的监督集合中随机采样 4 ,并对每个类别使用相同数量的示例。 对于无标注的数据,DBPedia 使用的是整个训练集,IMDb 使用训练集和未标记数据集的组合,Yelp-2、Yelp-5、Amazon-2 和 Amazon-5 使用外部数据(McAuley 等人,2015)5。 请注意,对基于 Yelp 和 Amazon 的数据集,未标记数据集的标签分布可能与标记数据集的标签分布不匹配,因为不同类别中的示例数量不同。 不过,我们发现使用所有未标记的数据效果很好。
预处理。 我们发现序列长度是获得良好性能的重要因素。 对于所有文本分类数据集,由于 BERT 的最大序列长度为 512,因此我们将输入截断为 512 个子词。 此外,当示例的长度大于 512 时,我们保留最后 512 个子词而不是前 512 个子词,因为保留句子的后半部分会导致 IMDb 上的性能更好。
在领域内无监督数据上微调 BERT。 我们使用 BERT 发布的代码在领域内非监督数据上微调 BERT 模型。 我们尝试 2e-5、5e-5 和 1e-4 的学习率,32、64 和 128 的批次大小以及 30k、100k 和 300k 的训练步数。 我们根据 held-out 集上的 BERT 损失而不是下游任务上的性能来选择经过微调的模型。
随机初始化的 Transformer。 在随机初始化 Transformer 的实验中,除了只使用 6 个隐藏层和 8 个注意头外,我们采用了 BERT 基础的超参数。 我们还将注意力和隐藏状态的丢失率提高到 0.2。 当我们使用随机初始化的架构训练 UDA 时,我们在拥有大量未标记数据的 Amazon-5 和 Yelp-5 上以 500k 或 1M 步训练 UDA。
BERT 超参数。 按照常见的 BERT 微调过程,我们将丢弃率保持为 0.1,并尝试将学习率设为 1e-5、2e-5 和 5e-5,并将批次大小设为 32 和 128。 我们还针对不同的数据大小调整了 30 到 100k 的步数。
UDA 超参数。 在所有实验中,我们将无监督目标 λ 的权重设置为1。 由于 32 是 v3-32 Cloud TPU Pod 上最小的批次大小,因此我们将 32 的批次大小用于受监控的目标。 当使用 BERT 初始化Transformer时,我们将 224 的批次大小用于无监督目标,以便可以在更多未标记的数据上训练模型。 我们发现,对于BERT FINETUNE,为每个未标记的示例生成一个增强示例就足够了。
本部分中的所有实验均在v3-32 Cloud TPU Pod上执行。
E.2 半监督学习基准CIFAR-10和SVHN
Wide-ResNet-28-2的超参数。 对于超参数调整,我们遵循 Oliver 等人 (2018),并且仅针对我们的无监督目标调整学习率和超参数。 其他超参数遵循已发布的AutoAugment代码的参数。 由于未标记的示例比标记的示例更多,因此我们将较大的批次大小用于无监督的目标。 例如,在我们对TPU进行的CIFAR-10实验中,对于有监督的损失,我们使用批处理大小为32,对于无监督的损失,我们使用批处理大小为960。 我们训练模型10万步,将无监督目标λ的权重设置为1。 在GPU上,我们发现将批处理大小分别为64和320分别用于有监督的损失和无监督的损失并训练40万步是很好的。 为了减少培训时间,我们在培训之前生成了增强的示例并将其转储到磁盘中。 对于CIFAR-10,我们为每个未标记的示例生成100个增强示例。 请注意,以在线方式生成增强示例总是更好或与使用转储的增强示例一样好,因为该模型可以在不同时期看到不同的增强示例,从而导致样本更加多样化。 我们报告10次运行的平均性能和标准偏差。
Shake-Shake和PyramidNet的超参数。 对于使用Shake-Shake进行的实验,我们训练了30万步UDA,将批量大小为128的对象作为受监视的目标,而批量大小为512的对象为非监督的目标。 对于使用PyramidNet + ShakeDrop进行的实验,我们训练UDA进行700k步长,对于受监控的目标使用64的批量大小,对于无监督的目标使用128的批量大小。 对于这两种模型,我们都使用0.03的学习率,并在AutoAugment之后的一个退火周期内使用余弦学习衰减。
本部分中的所有实验均在v3-32 Cloud TPU v3 Pod上执行。
E.3 ImageNet
10% 标注集设置。 除非另有说明,否则我们将遵循ResNet的开源实现中使用的标准超参数。6 对于10%标记的设置,我们将批量大小为512受监管的目标,无监管目标的批量大小为15,360。 我们使用0.3的基本学习速率,将其衰减10倍四次,并将无监督目标λ的权重设置为20。 我们屏蔽掉所有类别中最高概率小于0.5的未标记示例,并将Softmax温度设置为0.4。 该模型训练了40k步。 本部分中的实验是在v3-64 Cloud TPU v3 Pod上执行的。
完整标注集设置。 对于在完整ImageNet上进行的实验,我们对受监管的物镜使用8192的批次大小,对于无监督的物镜使用16384的批次大小。 在无监督目标λ上的权重设置为1。 我们使用熵最小化来增强预测。 我们使用1.6的基本学习率,然后将其衰减10倍四次。 本部分中的实验是在v3-128 Cloud TPU v3 Pod上执行的。