记录集
8.0版中的新功能: 该页面记录了Odoo 8.0中添加的新API,它应该是未来的主要开发API。 它还提供了有关从版本7及更早版本的“旧API”移植或桥接的信息,但未明确记录该API。 请参阅旧文档。
与模型和记录的交互是通过记录集执行的,记录集是同一模型的有序记录集。
Warning
与名称所暗示的相反,目前记录集可能包含重复项。 这可能在将来发生变化。
在模型上定义的方法在记录集上执行,它们的self是记录集:
class AModel(models.Model):
_name = 'a.model'
def a_method(self):
# self 可以是数据库中0条到所有记录之间的任何位置
# database
self.do_operation()
迭代记录集将产生新的单个记录(“单例”),就像在Python字符串上迭代产生单个字符的字符串一样:
def do_operation(self):
print self # => a.model(1, 2, 3, 4, 5)
for record in self:
print record # => a.model(1), then a.model(2), then a.model(3), ...
字段访问
记录集提供“活动记录”界面:模型字段可以作为属性直接从记录中读取和写入,但仅限于单个记录(单记录记录集)。
字段值也可以像dict项一样访问,对于动态字段名称,它比getattr()更优雅,更安全。
设置字段的值会触发对数据库的更新:
>>> record.name
Example Name
>>> record.company_id.name
Company Name
>>> record.name = "Bob"
>>> field = "name"
>>> record[field]
Bob
尝试在多个记录上读取或写入字段会引发错误。
访问关系字段(Many2one,One2many,Many2many)总是返回一个记录集,如果该字段不是空的则为空集。
Danger
对字段的每个赋值都会触发数据库更新,当同时设置多个字段或在多个记录上设置字段(到相同的值)时,请使用write():
# 3 * len(records) database updates
for record in records:
record.a = 1
record.b = 2
record.c = 3
# len(records) database updates
for record in records:
record.write({'a': 1, 'b': 2, 'c': 3})
# 1 database update
records.write({'a': 1, 'b': 2, 'c': 3})
记录缓存和预读
Odoo维护记录字段的缓存,因此并非每个字段访问都会发出数据库请求,这对性能来说太糟糕了。 以下示例仅针对第一个语句查询数据库:
record.name # 第一次访问从数据库读取值
record.name # 第二次访问从缓存中获取值
为了避免一次在一条记录上读取一个字段,Odoo按照一些启发式方法预读记录和字段以获得良好的性能。 一旦必须在给定记录上读取字段,ORM实际上会在较大的记录集上读取该字段,并将返回的值存储在缓存中供以后使用。 预取记录集通常是记录集,记录来自迭代。 此外,所有简单的存储字段(布尔,整数,浮点数,字符,文本,日期,日期时间,选择,许多2)都被完全取出;它们对应于模型表的列,并在同一查询中有效获取。
请考虑以下示例,其中partners是1000条记录的记录集。 在没有预取的情况下,循环将对数据库进行2000次查询。
通过预取,只进行一个查询:
for partner in partners:
print partner.name # first pass prefetches 'name' and 'lang'
# (and other fields) on all 'partners'
print partner.lang
预取也适用于辅助记录:当读取关系字段时,会预订它们的值(即记录)以供将来预取。 访问其中一个辅助记录会预取同一模型中的所有辅助记录。 这使得以下示例仅生成两个查询,一个用于合作伙伴,一个用于国家/地区:
countries = set()
for partner in partners:
country = partner.country_id # first pass prefetches all partners
countries.add(country.name) # first pass prefetches all countries
设置操作
记录集是不可变的,但可以使用各种set操作组合相同模型的集合,返回新的记录集。 设置操作不保留顺序。
record in set返回set中是否存在record(必须是1维记录集)。record not in set是逆操作set1 <= set2和set1 < set2返回set1是否是set2的子集(resp. strict)set1 >= set2和set1 > set2返回set1是否是set2超集(resp. strict)set1 | set2返回两个记录集的并集,一个包含任一源中存在的所有记录的新记录集set1 & set2返回两个记录集的交集,一个新记录集仅包含两个源中存在的记录set1 - set2返回一个新记录集,其中只包含set1中 不 在set2中的记录
其他记录集操作
记录集是可迭代的,因此常用的Python工具可用于转换(map(),sorted(),ifilter(),...)但是这些返回list或iterator,删除了在结果上调用方法或使用set操作的能力。
因此,记录集提供这些操作返回记录集本身(如果可能):
filtered()返回仅包含满足提供的谓词函数的记录的记录集。 谓词也可以是一个字符串,按字段为true或false进行过滤:
# 只保留公司属于当前用户的记录 records.filtered(lambda r: r.company_id == user.company_id) # 只保留合作伙伴是公司的记录 records.filtered("partner_id.is_company")sorted()返回按提供的键函数排序的记录集。 如果未提供密钥,请使用模型的默认排序顺序:
# sort records by name records.sorted(key=lambda r: r.name)mapped()将提供的函数应用于记录集中的每个记录,如果结果是记录集,则返回记录集:
# 返回集合中每个记录的汇总两个字段的列表 records.mapped(lambda r: r.field1 + r.field2)提供的函数可以是一个字符串来获取字段值:
# 返回名称列表 records.mapped('name') # 返回合作伙伴的记录集 record.mapped('partner_id') # 返回所有合作银行的并集,删除重复项 record.mapped('partner_id.bank_ids')
环境
Environment存储ORM使用的各种上下文数据:数据库游标(用于数据库查询),当前用户(用于访问权限检查)和当前上下文(存储任意元数据)。 环境还存储缓存。
所有记录集都有一个不可变的环境,可以使用env访问,并允许访问当前用户(user),光标(cr)或上下文(context):
>>> records.env
<Environment object ...>
>>> records.env.user
res.user(3)
>>> records.env.cr
<Cursor object ...)
从其他记录集创建记录集时,将继承环境。 环境可用于在其他模型中获取空记录集,并查询该模型:
>>> self.env['res.partner']
res.partner
>>> self.env['res.partner'].search([['is_company', '=', True], ['customer', '=', True]])
res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74)
改变环境
可以从记录集中自定义环境。 这将使用更改的环境返回记录集的新版本。
sudo()使用提供的用户集创建新环境,如果未提供任何用户,则使用管理员(绕过安全上下文中的访问权限/规则),使用新环境返回调用它的记录集的副本:
# create partner object as administrator env['res.partner'].sudo().create({'name': "A Partner"}) # list partners visible by the "public" user public = env.ref('base.public_user') env['res.partner'].sudo(public).search([])with_context()- 可以采用单个位置参数,它替换当前环境的上下文
- 可以通过关键字获取任意数量的参数,这些参数被添加到当前环境的上下文或步骤1中设置的上下文中
# look for partner, or create one with specified timezone if none is # found env['res.partner'].with_context(tz=a_tz).find_or_create(email_address)with_env()- 完全取代现有环境
常见的ORM方法
search()采用搜索域,返回匹配记录的记录集。 可以返回匹配记录的子集(
offset和limit参数)并进行排序(order参数):>>> # searches the current model >>> self.search([('is_company', '=', True), ('customer', '=', True)]) res.partner(7, 18, 12, 14, 17, 19, 8, 31, 26, 16, 13, 20, 30, 22, 29, 15, 23, 28, 74) >>> self.search([('is_company', '=', True)], limit=1).name 'Agrolait'Tip
要检查是否有任何记录与域匹配,或者计算记录的数量,请使用
search_count()create()获取许多字段值,并返回包含创建的记录的记录集:
>>> self.create({'name': "New Name"}) res.partner(78)write()获取许多字段值,将它们写入其记录集中的所有记录。 不归还任何东西:
self.write({'name': "Newer Name"})browse()获取数据库ID或id列表并返回记录集,当从外部Odoo获取记录ID(例如,通过外部系统往返)或在旧API中调用方法时时非常有用:
>>> self.browse([7, 18, 12]) res.partner(7, 18, 12)exists()返回仅包含数据库中存在的记录的新记录集。 可用于检查记录(例如从外部获得)是否仍然存在:
if not record.exists(): raise Exception("The record has been deleted")
或者在调用可能删除了一些记录的方法之后:
records.may_remove_some() # only keep records which were not deleted records = records.exists()ref()环境方法返回与提供的外部id匹配的记录:
>>> env.ref('base.group_public') res.groups(2)ensure_one()检查记录集是否为单例(仅包含单个记录),否则会引发错误:
records.ensure_one() # is equivalent to but clearer than: assert len(records) == 1, "Expected singleton"
创建模型
模型字段定义为模型本身的属性:
from odoo import models, fields
class AModel(models.Model):
_name = 'a.model.name'
field1 = fields.Char()
Warning
这意味着您无法定义具有相同名称的字段和方法,它们会发生冲突
默认情况下,字段的标签(用户可见名称)是字段名称的大写版本,可以使用string参数覆盖:
field2 = fields.Integer(string="an other field")
有关各种字段类型和参数,请参见字段引用。
默认值定义为字段上的参数,值为:
a_field = fields.Char(default="a value")
或者一个被调用来计算默认值的函数,它应返回该值:
def compute_default_value(self):
return self.get_value()
a_field = fields.Char(default=compute_default_value)
计算字段
可以使用compute参数计算字段(而不是直接从数据库中读取)。 必须将计算值分配给字段。 如果它使用其他字段的值,则应使用depends()指定这些字段:
from odoo import api
total = fields.Float(compute='_compute_total')
@api.depends('value', 'tax')
def _compute_total(self):
for record in self:
record.total = record.value + record.value * record.tax
使用子字段时,依赖关系可以是虚线路径:
@api.depends('line_ids.value') def _compute_total(self): for record in self: record.total = sum(line.value for line in record.line_ids)
- 默认情况下不会存储计算字段,它们会在请求时计算并返回。 设置
store = True会将它们存储在数据库中并自动启用搜索 也可以通过设置
search参数来启用在计算字段上搜索。 该值是返回Domains的方法名称:upper_name = field.Char(compute='_compute_upper', search='_search_upper') def _search_upper(self, operator, value): if operator == 'like': operator = 'ilike' return [('name', operator, value)]
要在计算字段上设置设置值,请使用
inverse参数。 它是反转计算和设置相关字段的函数的名称:document = fields.Char(compute='_get_document', inverse='_set_document') def _get_document(self): for record in self: with open(record.get_document_path) as f: record.document = f.read() def _set_document(self): for record in self: if not record.document: continue with open(record.get_document_path()) as f: f.write(record.document)
可以通过相同的方法同时计算多个字段,只需在所有字段上使用相同的方法并设置所有字段:
discount_value = fields.Float(compute='_apply_discount') total = fields.Float(compute='_apply_discount') @depends('value', 'discount') def _apply_discount(self): for record in self: # compute actual discount from discount percentage discount = record.value * record.discount record.discount_value = discount record.total = record.value - discount
onchange:动态更新UI
当用户更改表单中的字段值(但尚未保存表单)时,根据该值自动更新其他字段会很有用。更改税额或添加新发票行时更新最终总计。
- 计算字段会自动检查并重新计算,它们不需要
onchange 对于非计算字段,
onchange()装饰器用于提供新的字段值:@api.onchange('field1', 'field2') # 如果这些字段被更改,将会调用方法 def check_change(self): if self.field1 < self.field2: self.field3 = True
然后,在方法期间执行的更改将发送到客户端程序并对用户可见
- 客户端自动调用计算字段和new-API onchanges,而无需在视图中添加它们
通过在视图中添加
on_change =“0”,可以抑制来自特定字段的触发器:<field name="name" on_change="0"/>当用户编辑字段时,即使有功能字段或显式onchange取决于该字段,也不会触发任何接口更新。
Note
onchange方法工作虚拟记录对这些记录的分配没有写入数据库,只是用来知道要发送回客户端的值
底层SQL
环境中的cr属性是当前数据库事务的游标,并允许直接执行SQL,对于难以使用ORM表达的查询(例如复杂连接)或出于性能原因:
self.env.cr.execute("some_sql", param1, param2, param3)
因为模型使用相同的游标并且Environment包含各种缓存,所以当在原始SQL中更改数据库时,这些缓存必须无效,否则模型的进一步使用可能会变得不连贯。 在SQL中使用CREATE,UPDATE或DELETE时,必须清除缓存,而不是SELECT(这只是读取数据库)。
可以使用Environment对象的invalidate_all()方法执行清除缓存。
新API和旧API之间的兼容性
Odoo目前正在从较旧(较不常规)的API转换,可能需要手动从一个API手动桥接到另一个:
- RPC层(XML-RPC和JSON-RPC)都是用旧API表示的,纯粹在新API中表示的方法不能通过RPC获得
- 可以从仍旧用旧API样式编写的旧代码片段调用可覆盖的方法
旧API和新API之间的巨大差异是:
Environment(游标,用户ID和上下文)的值将显式传递给方法- 记录数据(
ids)显式传递给方法,可能根本不传递 - 方法往往适用于ID列表而不是记录集
默认情况下,假定方法使用新的API样式,并且不能从旧的API样式调用。
Tip
从新API到旧API的调用被桥接
使用新的API样式时,使用旧API定义的方法的调用会自动转换,不需要做任何特殊的事情:
>>> # method in the old API style
>>> def old_method(self, cr, uid, ids, context=None):
... print ids
>>> # method in the new API style
>>> def new_method(self):
... # system automatically infers how to call the old-style
... # method from the new-style method
... self.old_method()
>>> env[model].browse([1, 2, 3, 4]).new_method()
[1, 2, 3, 4]
两个装饰器可以向旧API公开新式方法:
model()该方法暴露为不使用id,其记录集通常为空。 它的“旧API”签名是
cr,uid,* arguments,context:@api.model def some_method(self, a_value): pass # can be called as old_style_model.some_method(cr, uid, a_value, context=context)
multi()该方法公开为获取id列表(可能为空),其“旧API”签名为
cr,uid,ids,* arguments,context:@api.multi def some_method(self, a_value): pass # can be called as old_style_model.some_method(cr, uid, [id1, id2], a_value, context=context)
因为新式API倾向于返回记录集,而旧式API倾向于返回id列表,所以还有一个装饰器管理这个:
returns()假定函数返回记录集,第一个参数应该是记录集模型的名称或
self(对于当前模型)。如果在新API样式中调用该方法,但在从旧API样式调用时将记录集转换为id列表,则无效:
>>> @api.multi ... @api.returns('self') ... def some_method(self): ... return self >>> new_style_model = env['a.model'].browse(1, 2, 3) >>> new_style_model.some_method() a.model(1, 2, 3) >>> old_style_model = pool['a.model'] >>> old_style_model.some_method(cr, uid, [1, 2, 3], context=context) [1, 2, 3]
模型参考
class odoo.models.Model(pool, cr)[source]
常规数据库持久性Odoo模型的主要超类。
Odoo模型是通过继承这个类创建的:
class user(Model):
...
系统稍后将为每个数据库(安装了类'模块)实例化一次类。
结构属性
_name
业务对象名称,以点表示法(在模块命名空间中)
_rec_name
用作名称的替代字段,由osv的name_get()使用(默认值:'name')
_inherit
请参阅继承和扩展。
_order
在没有指定排序的情况下搜索时的排序字段(默认值:'id')
_auto
是否应创建数据库表(默认值:
True)如果设置为
False,则覆盖init()以创建数据库表
Tip
要创建没有任何表的模型,请继承自odoo.models.AbstractModel
_table
支持_auto时创建的模型的表的名称,默认情况下自动生成。
_inherits
将父业务对象的_name映射到要使用的相应外键字段的名称的字典:
_inherits = {
'a.model': 'a_field_id',
'b.model': 'b_field_id'
}
实现基于组合的继承:新模型公开_inherits -ed模型的所有字段,但不存储它们:值本身仍保存在链接记录中。
Warning
如果在多个_inherits -ed上定义了相同的字段
_constraints
定义Python约束的(constraint_function,message,fields)列表。 字段列表是指示性的
自8.0版以来已弃用: use constrains()
_sql_constraints
列表(name,sql_definition,message)三元组定义生成支持表时要执行的SQL约束
_parent_store
除了parent_left和parent_right之外,还设置
嵌套集以对当前模型的记录启用快速分层查询
(默认值:False)
CRUD
create(vals) → record[source]
为模型创建新记录。
使用vals中的值初始化新记录,必要时使用default_get()中的值。
browse([ids]) → records[source]
返回当前环境中作为参数提供的ID的记录集。
可以不使用ids,单个ID或一系列ID。
unlink()[source]
删除当前集的记录
- AccessError --
- 如果用户对请求的对象没有取消链接权限
- 如果用户试图绕过请求对象上取消链接的访问规则
- UserError - 如果记录是其他记录的默认属性
write(vals)[source]
使用提供的值更新当前集中的所有记录。
dict) -- 要更新的字段和要设置的值,例如:
{'foo': 1, 'bar': "Qux"}
将字段foo设置为1并将字段bar设置为“Qux”如果这些是有效的(否则它会触发错误)。
- AccessError --
- 如果用户对请求的对象没有写权限
- 如果用户试图绕过访问规则以写入所请求的对象
- ValidateError - 如果用户尝试为未选择的字段输入无效值
- UserError - 如果在对象层次结构中创建循环操作的结果(例如将对象设置为其自己的父对象)
- 对于数字字段(
整数,Float),该值应为相应类型 - 对于
Boolean,该值应为bool - 对于
选择,该值应与选择值匹配(通常str,有时int) - 对于
Many2one,该值应该是要设置的记录的数据库标识符 其他非关系字段使用字符串作为值
One2many和Many2many使用特殊的“命令”格式来操纵存储在字段中/与字段相关联的记录集。此格式是按顺序执行的三元组列表,其中每个三元组是在记录集上执行的命令。 并非所有命令都适用于所有情况。 可能的命令是:
(0, _, values)- 添加从提供的
valuedict创建的新记录。 (1, id, values)- 使用
values中的值更新idid的现有记录。 不能在create()中使用。 (2, id, _)- 从集合中删除id
id的记录,然后将其删除(从数据库中删除)。 不能在create()中使用。 (3, id, _)- 从集合中删除id
id的记录,但不删除它。 不能用于One2many。 不能在create()中使用。 (4, id, _)- 将id
id的现有记录添加到集合中。 不能用于One2many。 (5, _, _)- 从集合中删除所有记录,相当于在每条记录上明确使用命令
3。 不能用于One2many。 不能在create()中使用。 (6, _, ids)- 替换
ids列表中集合中的所有现有记录,相当于使用命令5,然后为每个id使用命令在4ids中。
Note
上面列表中标记为
_的值将被忽略,可以是任何值,通常为0或False。
read([fields])[source]
读取self,低级/ RPC方法中记录的请求字段。 在Python代码中,首选browse()。
read_group(domain, fields, groupby, offset=0, limit=None, orderby=False, lazy=True)[source]
获取按给定groupby字段分组的列表视图中的记录列表
- domain - 指定搜索条件的列表[['field_name','operator','value'],...]
- fields(
list) - 在对象上指定的列表视图中显示的字段列表 - groupby(
list) - 记录将被分组的groupby描述列表。 groupby描述是字段(然后它将按该字段分组)或字符串'field:groupby_function'。 目前,支持的唯一功能是“日”,“周”,“月”,“季度”或“年”,它们只适用于日期/日期时间字段。 - offset(
int) - 要跳过的可选记录数 - limit(
int) - 可选的最大返回记录数 - orderby (
list) -可选的order by规格,用于覆盖组的自然排序顺序,另请参见search()(目前仅支持多个字段) - lazy(
bool) - 如果为true,则结果仅按第一个groupby分组,其余的groupbys放在__context键中。 如果为false,则所有groupbys都在一次调用中完成。
字典列表(每个记录一个字典)包含:
- 按
groupby参数中的字段分组的字段值 - __domain:指定搜索条件的元组列表
- __context:带有
groupby等参数的字典
- 如果用户对请求的对象没有读取权限
- 如果用户试图绕过访问规则以读取请求的对象
Searching
search(args[, offset=0][, limit=None][, order=None][, count=False])[source]
根据args 搜索域搜索记录。
search_count(args) → int[source]
返回当前模型中与提供的域匹配的记录数。
name_search(name='', args=None, operator='ilike', limit=100) → records[source]
与给定的运算符进行比较时,搜索具有与给定名称模式匹配的显示名称的记录,同时还匹配可选搜索域(args )。
这用于例如基于关系字段的部分值来提供建议。 有时被视为name_get()的反函数,但不能保证。
此方法等效于使用基于display_name的搜索域调用search(),然后对搜索结果调用name_get()。
记录集操作
ids
此记录集中的实际记录ID列表(忽略要创建的记录的占位符ID)
ensure_one()[source]
验证当前的recorset是否包含单个记录。 否则会引发异常。
exists() → records[source]
返回存在的self中的记录子集,并在缓存中标记已删除的记录。 它可以用作记录的测试:
if record.exists():
...
按照惯例,新记录将作为现有记录返回。
filtered(func)[source]
选择self中的记录,使func(rec)为真,并将它们作为记录集返回。
sorted(key=None, reverse=False)[source]
返回由key排序的记录集self。
- key - 返回每个记录的比较键的一个参数的函数,或字段名称,或
None,在这种情况下,记录按照默认模型排序订购 - reverse - 如果
True,则以相反的顺序返回结果
mapped(func)[source]
对self中的所有记录应用func,并将结果作为列表或记录集返回(如果func返回记录集)。 在后一种情况下,返回的记录集的顺序是任意的。
self环境交换
sudo([user=SUPERUSER])[source]
返回附加到提供的用户的此记录集的新版本。
默认情况下,它返回SUPERUSER记录集,其中绕过访问控制和记录规则。
Note
使用sudo可能导致数据访问跨越记录规则的边界,可能混合要隔离的记录(例如,来自多公司环境中的不同公司的记录)。
这可能会导致在多种方法中选择一条记录的方法产生不直观的结果 - 例如获取默认公司或选择物料清单。
Note
由于必须重新评估记录规则和访问控制,因此新记录集不会从当前环境的数据高速缓存中受益,因此以后的数据访问可能会在从数据库重新获取时产生额外的延迟。
返回的记录集与self具有相同的预取对象。
with_context([context][, **overrides]) → records[source]
返回附加到扩展上下文的此记录集的新版本。
扩展上下文是提供的上下文,其中覆盖被合并,或当前上下文,其中覆盖被合并例如:
# current context is {'key1': True}
r2 = records.with_context({}, key2=True)
# -> r2._context is {'key2': True}
r2 = records.with_context(key2=True)
# -> r2._context is {'key1': True, 'key2': True}
with_env(env)[source]
返回附加到提供的环境的此记录集的新版本
Warning
新环境不会受益于当前环境的数据缓存,因此以后的数据访问可能会在从数据库重新获取时产生额外的延迟。
返回的记录集与self具有相同的预取对象。
字段和视图查询
fields_get([fields][, attributes])[source]
返回每个字段的定义。
返回的值是字典的字典(由字段名称指示)。 _inherits'd字段包括在内。 字符串,帮助和选择(如果存在)属性已翻译。
- allfields - 要记录的字段列表,所有字段都为空或未提供
- attributes - 为每个字段返回的描述属性列表,如果为空或未提供则全部
fields_view_get([view_id | view_type='form'])[source]
获取所请求视图的详细组成,如字段,模型,视图体系结构
- view_id - 视图的ID或None
- view_type - 如果view_id为None('form','tree',...)则返回的视图类型
- toolbar - 如果包含上下文操作,则为true
- submenu - 已弃用
- AttributeError --
- 如果继承的视图具有未知的位置,可以使用“之前”,“之后”,“内部”,“替换”以外的其他视图
- 如果在父视图中找到“position”以外的某些标记
- 无效的ArchitectureError - 如果在结构上定义了除表单,树,日历,搜索等之外的视图类型
方法杂项
default_get(fields) → default_values[source]
返回fields_list中字段的默认值。 默认值由上下文,用户默认值和模型本身确定。
copy(default=None)[source]
重复记录self使用默认值更新它
dict) - 要复制的记录的原始值中的字段值字典,例如:{'field_name':overridden_value,... } name_get() → [(id, name), ...][source]
返回self中记录的文本表示形式。
默认情况下,这是display_name字段的值。
(id,text_repr)的列表name_create(name) → record[source]
通过调用create()创建一个新记录,只提供一个值:新记录的显示名称。
新记录将使用适用于此模型的任何默认值进行初始化,或通过上下文提供。 create()的通常行为适用。
自动字段
id
Identifier field
_log_access
是否应生成日志访问字段(create_date,write_uid,...)(默认值:True)
create_date
创建记录的日期
Datetimecreate_uid
创建记录的用户的关系字段
res.userswrite_date
上次修改记录的日期
Datetimewrite_uid
修改记录的最后一个用户的关系字段
res.users保留字段名称
一些字段名称保留用于超出自动字段的预定义行为。 当需要相关行为时,应在模型上定义它们:
name
_rec_name的默认值,用于在需要代表“命名”的上下文中显示记录。
active
切换记录的全局可见性,如果活动设置为False该记录在大多数搜索和列表中不可见
sequence
可更改的排序标准允许在列表视图中对模型进行拖放重新排序
state
对象的生命周期阶段,由字段上的状态属性使用
parent_id
用于在树结构中对记录进行排序,并在域中启用child_of运算符
parent_left
与_parent_store一起使用,允许更快的树结构访问
parent_right
方法装饰器
该模块提供了用于管理两种不同API样式的元素,即“传统”和“记录”样式。
在“传统”样式中,参数如数据库游标,用户ID,上下文字典和记录ID(通常表示为cr,uid,context ,ids)显式传递给所有方法。 在“记录”样式中,这些参数隐藏在模型实例中,这使其具有更加面向对象的感觉。
例如,声明:
model = self.pool.get(MODEL)
ids = model.search(cr, uid, DOMAIN, context=context)
for rec in model.browse(cr, uid, ids, context=context):
print rec.name
model.write(cr, uid, ids, VALUES, context=context)
也可以写成:
env = Environment(cr, uid, context) # cr, uid, context wrapped in env
model = env[MODEL] # retrieve an instance of MODEL
recs = model.search(DOMAIN) # search returns a recordset
for rec in recs: # iterate over the records
print rec.name
recs.write(VALUES) # update all records in recs
以基于参数名称的一些启发式方法自动修饰以“传统”样式编写的方法。
odoo.api.multi(method)[source]
装饰一个记录样式的方法,其中self是一个记录集。 该方法通常定义对记录的操作。 这样的方法:
@api.multi
def method(self, args):
...
可以在记录和传统样式中调用,例如:
# recs = model.browse(cr, uid, ids, context)
recs.method(args)
model.method(cr, uid, ids, args, context=context)
odoo.api.model(method)[source]
装饰一个记录样式的方法,其中self是一个记录集,但其内容不相关,只有模型。 这样的方法:
@api.model
def method(self, args):
...
可以在记录和传统样式中调用,例如:
# recs = model.browse(cr, uid, ids, context)
recs.method(args)
model.method(cr, uid, args, context=context)
请注意,没有ids以传统方式传递给方法。
odoo.api.depends(*args)[source]
返回一个装饰器,它指定“compute”方法的字段依赖关系(对于新式函数字段)。 每个参数必须是一个字符串,该字符串由以点分隔的字段名称序列组成:
pname = fields.Char(compute='_compute_pname')
@api.one
@api.depends('partner_id.name', 'partner_id.is_company')
def _compute_pname(self):
if self.partner_id.is_company:
self.pname = (self.partner_id.name or "").upper()
else:
self.pname = self.partner_id.name
也可以将单个函数作为参数传递。 在这种情况下,通过使用字段的模型调用函数来给出依赖关系。
odoo.api.constrains(*args)[source]
装饰约束检查器。 每个参数必须是检查中使用的字段名称:
@api.one
@api.constrains('name', 'description')
def _check_description(self):
if self.name == self.description:
raise ValidationError("Fields name and description must be different")
在已修改其中一个命名字段的记录上调用。
如果验证失败,应该引发ValidationError。
Warning
@constrains仅支持简单字段名称,点名称(关系字段的字段,例如partner_id.customer)不受支持且将被忽略
仅当装饰方法中的声明字段包含在create或write调用中时,才会触发@constrains。
这意味着视图中不存在的字段在创建记录期间不会触发调用。 必须覆盖create以确保始终触发约束(例如,测试缺少值)。
odoo.api.onchange(*args)[source]
返回装饰器以装饰给定字段的onchange方法。 每个参数必须是字段名称:
@api.onchange('partner_id')
def _onchange_partner(self):
self.message = "Dear %s" % (self.partner_id.name or "")
在显示该字段的表单视图中,将在修改其中一个给定字段时调用该方法。 在包含表单中存在的值的伪记录上调用该方法。 该记录上的字段分配会自动发送回客户端。
该方法可能会返回字典以更改字段域并弹出警告消息,就像在旧API中一样:
return {
'domain': {'other_id': [('partner_id', '=', partner_id)]},
'warning': {'title': "Warning", 'message': "What is this?"},
}
Warning
@onchange仅支持简单字段名称,点名称(关系字段的字段,例如partner_id.tz)不受支持,将被忽略
odoo.api.returns(model, downgrade=None, upgrade=None)[source]
返回返回model实例的方法的装饰器。
- model - 模型名称,或当前模型的
'self' - downgrade - 函数
downgrade(self,value,* args,** kwargs)将记录样式的值转换为传统的 - 风格输出 - upgrade - 一个函数
upgrade(self,value,* args,** kwargs),将传统风格的值转换为记录 - 风格输出
参数self,* args和**kwargs是以记录样式传递给方法的参数。
装饰器将方法输出调整为api样式:传统样式的id,ids或False,以及记录样式的记录集:
@model
@returns('res.partner')
def find_partner(self, arg):
... # return some record
# 输出取决于调用风格:传统与记录风格
partner_id = model.find_partner(cr, uid, arg, context=context)
# recs = model.browse(cr, uid, ids, context)
partner_record = recs.find_partner(arg)
请注意,修饰方法必须满足该约定。
那些装饰器会自动继承:覆盖装饰的现有方法的方法将使用相同的@returns(model)进行修饰。
odoo.api.one(method)[source]
装饰一个记录样式的方法,其中self应该是一个单例实例。 修饰后的方法会自动循环记录,并生成包含结果的列表。 如果方法用returns()进行修饰,它会连接生成的实例。 这样的方法:
@api.one
def method(self, args):
return self.name
可以在记录和传统样式中调用,例如:
# recs = model.browse(cr, uid, ids, context)
names = recs.method(args)
names = model.method(cr, uid, ids, args, context=context)
自9.0版开始不推荐使用: one()经常使代码不那么清晰,并且行为方式与开发人员和读者可能不会期望的方式相同。
强烈建议使用multi()并迭代self记录集或确保记录集是ensure_one()的单个记录。
odoo.api.v7(method_v7)[source]
装饰一个只支持旧式api的方法。 可以通过重新定义具有相同名称并用v8()装饰的方法来提供新式api:
@api.v7
def foo(self, cr, uid, ids, context=None):
...
@api.v8
def foo(self):
...
如果一个方法调用另一个方法,则必须特别小心,因为该方法可能被覆盖! 在这种情况下,应该从当前类调用该方法(例如MyClass),例如:
@api.v7
def foo(self, cr, uid, ids, context=None):
# Beware: records.foo() may call an overriding of foo()
records = self.browse(cr, uid, ids, context)
return MyClass.foo(records)
请注意,包装器方法使用第一种方法的docstring。
odoo.api.v8(method_v8)[source]
装饰一个仅支持新式api的方法。 可以通过重新定义具有相同名称的方法并使用v7()进行修饰来提供旧式api:
@api.v8
def foo(self):
...
@api.v7
def foo(self, cr, uid, ids, context=None):
...
请注意,包装器方法使用第一种方法的docstring。
字段
基础关键字
class odoo.fields.Field(string=<object object>, **kwargs)[source]
字段描述符包含字段定义,并管理记录上相应字段的访问和分配。 在实例化字段时可能会提供以下属性:
- string - 用户看到的字段标签(字符串);如果未设置,ORM将获取类中的字段名称(大写)。
- help - 用户看到的字段的工具提示(字符串)
- readonly - 该字段是否为readonly(布尔值,默认为
False) - required - 是否需要字段的值(布尔值,默认为
False) - index - 字段是否在数据库中索引(布尔值,默认情况下
False) - default - 字段的默认值;这可以是静态值,也可以是记录集并返回值的函数;使用
default = None放弃该字段的默认值 - states - 将状态值映射到UI属性 - 值对列表的字典;可能的属性是:'readonly','required','invisible'。
注意:任何基于状态的条件都要求客户端UI上的
state字段值可用。 这通常通过将其包括在相关视图中来完成,如果与最终用户不相关,则可能使其不可见。 - groups - 以逗号分隔的组xml ids列表(字符串);这限制了仅对给定组的用户的字段访问
- copy(
bool) - 是否应在复制记录时复制字段值(对于普通字段,默认值为True,对于one2many和计算字段,包括属性字段和相关字段默认False) - oldname(
string) - 此字段的先前名称,以便ORM可以在迁移时自动重命名
计算字段
可以定义一个字段,其值是计算的,而不是简单地从数据库中读取。 下面给出了特定于计算字段的属性。 要定义这样的字段,只需为属性compute提供一个值。
- compute - 计算字段的方法的名称
- inverse - 反转字段的方法的名称(可选)
- search - 在字段上实现搜索的方法的名称(可选)
- store - 字段是否存储在数据库中(布尔值,默认
False在计算字段上) - compute_sudo - 是否应将该字段重新计算为超级用户以绕过访问权限(布尔值,默认为
False)
为compute,inverse和search给出的方法是模型方法。 它们的签名如下例所示:
upper = fields.Char(compute='_compute_upper',
inverse='_inverse_upper',
search='_search_upper')
@api.depends('name')
def _compute_upper(self):
for rec in self:
rec.upper = rec.name.upper() if rec.name else False
def _inverse_upper(self):
for rec in self:
rec.name = rec.upper.lower() if rec.upper else False
def _search_upper(self, operator, value):
if operator == 'like':
operator = 'ilike'
return [('name', operator, value)]
compute方法必须在调用的记录集的所有记录上分配字段。 必须在compute方法上应用装饰器odoo.api.depends()以指定字段依赖性;这些依赖关系用于确定何时重新计算字段;重新计算是自动的,并保证缓存/数据库的一致性。 请注意,相同的方法可用于多个字段,您只需分配方法中的所有给定字段;对于所有这些字段,将调用该方法一次。
默认情况下,计算字段不会存储到数据库中,而是即时计算。 添加属性store = True会将字段的值存储在数据库中。 存储字段的优点是在该字段上搜索由数据库本身完成。 缺点是在必须重新计算字段时需要数据库更新。
正如其名称所示,反向方法执行计算方法的反转:调用的记录具有字段的值,您必须对字段依赖项应用必要的更改,以便计算给出预期值。 请注意,默认情况下,只读取没有逆方法的计算字段。
在对模型进行实际搜索之前处理域时会调用搜索方法。 它必须返回等同于条件的域:字段运算符值。
关系字段
通过遵循一系列关系字段并读取到达模型上的字段来给出相关字段的值。 要遍历的完整字段序列由属性指定
如果未重新定义某些字段属性,则会自动从源字段复制这些属性:string, help, readonly, required (仅当序列中的所有字段都需要时),groups, digits, size, translate, sanitize, selection, comodel_name, domain, context。 从源字段复制所有无语义属性。
默认情况下,相关字段的值不会存储到数据库中。
添加属性store = True以使其存储,就像计算字段一样。 修改其依赖项后,将自动重新计算相关字段。
公司依赖的领域
以前称为“财产”字段,这些字段的价值取决于公司。 换句话说,属于不同公司的用户可能在给定记录上看到该字段的不同值。
稀疏的字段
稀疏字段非空的概率非常小。 因此,许多这样的字段可以紧凑地序列化到公共位置,后者是所谓的“序列化”字段。
增量定义
字段在模型类上定义为类属性。 如果扩展模型(参见Model),还可以通过在子类上重新定义具有相同名称和相同类型的字段来扩展字段定义。 在这种情况下,字段的属性取自父类,并由子类中给出的属性覆盖。
例如,下面的第二个类仅在字段state上添加工具提示:
class First(models.Model):
_name = 'foo'
state = fields.Selection([...], required=True)
class Second(models.Model):
_inherit = 'foo'
state = fields.Selection(help="Blah blah blah")
class odoo.fields.Char(string=<object object>, **kwargs)[source]
基础:odoo.fields._String
基本字符串字段,可以是长度限制的,通常在客户端中显示为单行字符串。
- size(
int) - 为该字段存储的最大值 - translate - 启用字段值的转换;使用
translate = True将字段值作为一个整体进行转换;translate也可以是可调用的,使得translate(callback, value)通过callback(term)转换value检索术语的转换。
class odoo.fields.Boolean(string=<object object>, **kwargs)[source]
class odoo.fields.Integer(string=<object object>, **kwargs)[source]
class odoo.fields.Float(string=<object object>, digits=<object object>, **kwargs)[source]
精度数字由属性给出
class odoo.fields.Text(string=<object object>, **kwargs)[source]
基础:odoo.fields._String
与Char非常相似,但用于较长的内容,没有大小,通常显示为多行文本框。
translate = True将字段值作为一个整体进行转换; translate也可以是可调用的,使得translate(callback, value)通过callback(term) 转换value 检索术语的转换。class odoo.fields.Selection(selection=<object object>, string=<object object>, **kwargs)[source]
- selection - 指定此字段的可能值。
它以对的列表(
value,string)或模型方法或方法名称的形式给出。 - selection_add - 在重写字段的情况下提供选择的扩展。 它是成对列表(
值,字符串)。
class odoo.fields.Html(string=<object object>, **kwargs)[source]
基础:odoo.fields._String
class odoo.fields.Date(string=<object object>, **kwargs)[source]
static context_today(record, timestamp=None)[source]
以适合日期字段的格式返回客户端时区中显示的当前日期。 此方法可用于计算默认值。
static from_string(value)[source]
将ORM 值转换为date值。
static to_string(value)[source]
将date值转换为ORM预期的格式。
static today(*args)[source]
以ORM预期的格式返回当天。 此函数可用于计算默认值。
class odoo.fields.Datetime(string=<object object>, **kwargs)[source]
static context_timestamp(record, timestamp)[source]
返回转换为客户端时区的给定时间戳。
此方法不意味着用作默认初始化程序,因为datetime字段在客户端显示时自动转换。 对于默认值,应使用fields.datetime.now()。
static from_string(value)[source]
将ORM value转换为datetime值。
static now(*args)[source]
以ORM预期的格式返回当前日期和时间。 此函数可用于计算默认值。
static to_string(value)[source]
将datetime值转换为ORM期望的格式。
关系字段
class odoo.fields.Many2one(comodel_name=<object object>, string=<object object>, **kwargs)[source]
基础:odoo.fields._Relational
这样一个字段的值是大小为0(无记录)或1(单个记录)的记录集。
- comodel_name - 目标模型的名称(字符串)
- domain - 在客户端(域或字符串)上设置候选值的可选域
- context - 处理该字段时在客户端使用的可选上下文(字典)
- ondelete - 删除引用记录时该怎么办;可能的值有:
'set null','restrict','cascade' - auto_join - 是否在搜索该字段时生成JOIN(布尔值,默认为
False) - delegate - 它设置为
True使目标模型的字段从当前模型访问的(对应于_inherits)
除相关字段或字段扩展名外,属性comodel_name是必需的。
class odoo.fields.One2many(comodel_name=<object object>, inverse_name=<object object>, string=<object object>, **kwargs)[source]
基础:odoo.fields._RelationalMulti
One2many字段;此字段的值是comodel_name中所有记录的记录集,使得字段inverse_name等于当前记录。
- comodel_name - 目标模型的名称(字符串)
- inverse_name -
comodel_name(字符串)的逆Many2one字段的名称 - domain - 在客户端(域或字符串)上设置候选值的可选域
- context - 处理该字段时在客户端使用的可选上下文(字典)
- auto_join - 是否在搜索该字段时生成JOIN(布尔值,默认为
False) - limit - 读取时使用的可选限制(整数)
除相关字段或字段扩展名外,属性comodel_name和inverse_name是必需的。
class odoo.fields.Many2many(comodel_name=<object object>, relation=<object object>, column1=<object object>, column2=<object object>, string=<object object>, **kwargs)[source]
基础:odoo.fields._RelationalMulti
Many2many场;这样一个字段的值是记录集。
除相关字段或字段扩展名外,属性comodel_name是必需的。
- relation - 在数据库中存储关系的表的可选名称(字符串)
- column1 - 引用表
relation中的“这些”记录的列的可选名称(字符串) - column2 - 引用表
relation中的“那些”记录的列的可选名称(字符串)
属性relation,column1和column2是可选的。 如果没有给出,名称将自动从型号名称生成,前提是model_name和comodel_name不同!
- domain - 在客户端(域或字符串)上设置候选值的可选域
- context - 处理该字段时在客户端使用的可选上下文(字典)
- limit - 读取时使用的可选限制(整数)
class odoo.fields.Reference(selection=<object object>, string=<object object>, **kwargs)[source]
继承和扩展
Odoo提供了三种不同的机制来以模块化方式扩展模型:
- 从现有模型创建新模型,向副本添加新信息,但保留原始模块的原样
- 扩展其他模块中定义的模型,替换以前的版本
- 将一些模型的字段委托给它包含的记录
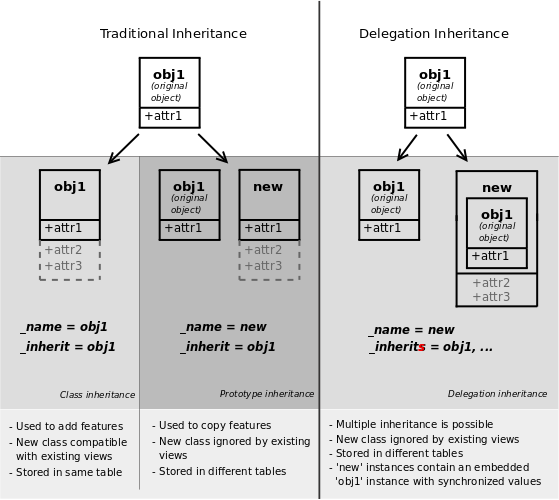
经典继承
当同时使用_inherit和_name属性时,Odoo使用现有属性(通过_inherit提供)作为基础创建新模型。 新模型从它的父类中获取所有字段,方法和元信息(defaults & al)
class Inheritance0(models.Model):
_name = 'inheritance.0'
name = fields.Char()
def call(self):
return self.check("model 0")
def check(self, s):
return "This is {} record {}".format(s, self.name)
class Inheritance1(models.Model):
_name = 'inheritance.1'
_inherit = 'inheritance.0'
def call(self):
return self.check("model 1")
并使用它们:
a = env['inheritance.0'].create({'name': 'A'})
b = env['inheritance.1'].create({'name': 'B'})
a.call()
b.call()
会产生:
"This is model 0 record A"
"This is model 1 record B"
第二个模型继承自第一个模型的check方法及其name字段,但覆盖了call方法,就像使用标准Python继承时一样。
扩展
当使用_inherit但忽略_name时,新模型将替换现有模型,实际上就地扩展它。 这对于向现有模型添加新字段或方法(在其他模块中创建)或自定义或重新配置它们(例如更改其默认排序顺序)非常有用:
_name = 'extension.0'
name = fields.Char(default="A")
class Extension1(models.Model):
_inherit = 'extension.0'
description = fields.Char(default="Extended")
record = env['extension.0'].create({})
record.read()[0]
会产生:
{'name': "A", 'description': "Extended"}
Note
它还会产生各种自动字段,除非它们已被禁用
委托
第三种继承机制提供了更大的灵活性(可以在运行时更改)但功耗更低:使用_inherits模型delegates查找当前模型中找不到的任何字段到“儿童”模型。 通过在父模型上自动设置的Reference字段执行委派:
class Child0(models.Model):
_name = 'delegation.child0'
field_0 = fields.Integer()
class Child1(models.Model):
_name = 'delegation.child1'
field_1 = fields.Integer()
class Delegating(models.Model):
_name = 'delegation.parent'
_inherits = {
'delegation.child0': 'child0_id',
'delegation.child1': 'child1_id',
}
child0_id = fields.Many2one('delegation.child0', required=True, ondelete='cascade')
child1_id = fields.Many2one('delegation.child1', required=True, ondelete='cascade')
record = env['delegation.parent'].create({
'child0_id': env['delegation.child0'].create({'field_0': 0}).id,
'child1_id': env['delegation.child1'].create({'field_1': 1}).id,
})
record.field_0
record.field_1
将导致:
0
1
并且可以直接在委托字段上书写:
record.write({'field_1': 4})
Warning
使用委托继承时,方法不继承,只有字段
域
域是一个标准列表,每个标准是的三元组(哪里:列表或元组)(field_name,operator,value)
field_name(str)- 当前模型的字段名称,或使用点符号遍历
Many2one的关系,例如'street'或'partner_id.country' operator(str)用于将
field_name与值进行比较的运算符。 有效的操作符是:=- 等于
!=- 不等于
>- 比...更多
>=- 大于或等于
<- 少于
<=- 小于或等于
=?- unset或equals to(如果
value为None或False,则返回true,否则表现为=) =like- 将
field_name与value模式匹配。 模式中的下划线_代表(匹配)任何单个字符;百分号%匹配零个或多个字符的任何字符串。 like- 将
field_name与%value%模式匹配。 与=like类似,但在匹配前用'%' 包装value not like- 与
%value%的匹配类型不匹配 ilike- 不区分大小写的
like not ilike- 不区分大小写
not like =ilike- 不区分大小写
=like in- 等于
value中的任何项目,value应该是项目列表 not in- 与
value中的所有项目不相等 child_of是
value记录的子(后代)。考虑模型的语义(即遵循由
_parent_name命名的关系字段)。
value- 变量类型,必须与命名字段匹配(通过
运算符)
可以使用前缀形式的逻辑运算符组合域标准:
'&'- 逻辑AND,默认操作将标准相互组合。 二元运算符(使用接下来的2个标准或组合)。
'|'- 逻辑OR,二元运算符。
'!'逻辑NOT,一元运算符。
Tip
主要是否定标准的组合
个人标准通常具有否定形式(e.g.
=->!=,<->>=) ,其比否定正面更简单。
Example
要搜索来自比利时或德国的名为ABC的合作伙伴,其语言不是英语:
[('name','=','ABC'),
('language.code','!=','en_US'),
'|',('country_id.code','=','be'),
('country_id.code','=','de')]
该域名解释为:
(name is 'ABC')
AND (language is NOT english)
AND (country is Belgium OR Germany)
从旧API移植到新API
- 在新的API中应避免使用裸列表,而是使用记录集
- 仍旧在旧API中编写的方法应由ORM自动桥接,无需切换到旧API,只需将它们称为新的API方法即可。 有关更多详细信息,请参阅旧API方法的自动桥接。
search()返回一个记录集,例如浏览其结果- 使用带有
related =或compute =的普通字段类型替换fields.related和fields.function参数 依赖()oncompute =方法必须完整,它必须列出所有字段和子字段计算方法使用。 最好有太多的依赖项(将在不需要的情况下重新计算字段)比不够(将忘记重新计算字段然后值将不正确)- remove计算字段上的所有
onchange方法。 当其中一个依赖项发生更改时,计算字段会自动重新计算,并且用于通过客户端自动生成onchange - 从旧的API上下文调用时
model()andmulti()装饰器用于桥接 ,对于内部或纯粹的新api (e.g. compute)他们没作用 - 删除
_default,替换为相应字段的default =参数 如果字段的
string =是字段名称的标题版本:name = fields.Char(string="Name")它没用,应该删除
multi =参数在新API字段上没有执行任何操作在相同结果的所有相关字段上使用相同的compute =方法- 按名称提供
compute =,inverse =和search =方法(作为字符串),这使得它们可以覆盖(不需要中间体) “蹦床”功能) - 仔细检查所有字段和方法是否有不同的名称,碰撞时没有警告(因为Python在Odoo看到任何东西之前处理它)
- 正常的new-api导入是
from odoo import fields, models. 如果需要兼容性修饰符,请使用from odoo import api, fields, models - 避免使用
one()装饰器,它可能没有达到预期效果 - 删除
create_uid,create_date,write_uid和write_date字段的显式定义:它们现在被创建为常规“合法”字段,可以像开箱即用的任何其他字段一样进行读写 当直接转换不可能(语义无法桥接)或“旧API”版本不可取并且可以针对新API进行改进时,可以使用完全不同的“旧API”和“新API”实现使用
v7()和v8()的相同方法名称。 首先应使用旧的API样式定义该方法,并使用v7()进行修饰,然后应使用完全相同的名称重新定义该方法,但应使用新的API样式并使用进行修饰V8()。 来自旧API上下文的调用将被分派到第一个实现,并且来自新API上下文的调用将被分派到第二个实现。 一个实现可以通过切换上下文来调用(并经常)调用另一个实现。Danger
使用这些装饰器使得方法极难覆盖并且难以理解和记录
_columns或_all_columns的使用应替换为_fields,它提供对新式odoo.fields.Field实例的访问。实例(而不是旧式odoo.osv.fields._column)。使用新API样式创建的非存储计算字段在
_columns中不,并且只能通过_fields进行检查- 在方法中重新分配
self可能是不必要的,可能会破坏翻译内省 Environment对象依赖于某些threadlocal状态,必须在使用它们之前设置它们。 当尝试在尚未设置的上下文中使用新API时,必须使用odoo.api.Environment.manage()上下文管理器执行此操作,例如新线程或Python交互式环境:>>> from odoo import api, modules >>> r = modules.registry.RegistryManager.get('test') >>> cr = r.cursor() >>> env = api.Environment(cr, 1, {}) Traceback (most recent call last): ... AttributeError: environments >>> with api.Environment.manage(): ... env = api.Environment(cr, 1, {}) ... print env['res.partner'].browse(1) ... res.partner(1,)
自动桥接旧的API方法
初始化模型时,如果它们看起来像旧API样式中声明的模型,则会自动扫描和桥接所有方法。 这种桥接使它们可以从新的API风格方法中透明地调用。
如果第二个位置参数(在self之后)被调用cr或cursor,则方法被匹配为“旧API样式”。 系统还识别第三个位置参数被称为uid或用户,第四个被称为id或ids。 它还识别出存在任何名为context的参数。
When calling such methods from a new API context, the system will
automatically fill matched parameters from the current
Environment (for cr,
user and
context) or the current recordset (for id
and ids).
In the rare cases where it is necessary, the bridging can be customized by decorating the old-style method:
- disabling it entirely, by decorating a method with
noguess()there will be no bridging and methods will be called the exact same way from the new and old API styles defining the bridge explicitly, this is mostly for methods which are matched incorrectly (because parameters are named in unexpected ways):
cr()- will automatically prepend the current cursor to explicitly provided parameters, positionally
cr_uid()- will automatically prepend the current cursor and user's id to explictly provided parameters
cr_uid_ids()- will automatically prepend the current cursor, user's id and recordset's ids to explicitly provided parameters
cr_uid_id()will loop over the current recordset and call the method once for each record, prepending the current cursor, user's id and record's id to explicitly provided parameters.
Danger
the result of this wrapper is always a list when calling from a new-API context
All of these methods have a
_context-suffixed version (e.g.cr_uid_context()) which also passes the current context by keyword.- dual implementations using
v7()andv8()will be ignored as they provide their own "bridging"