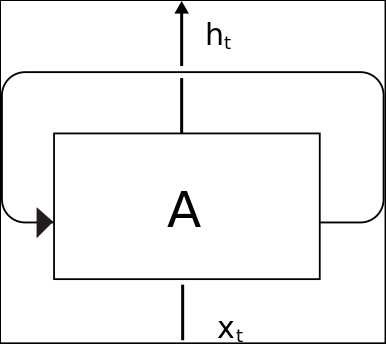
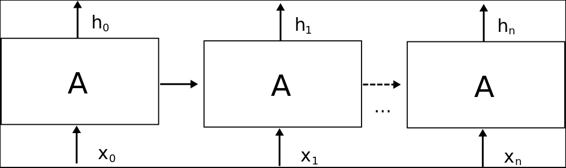
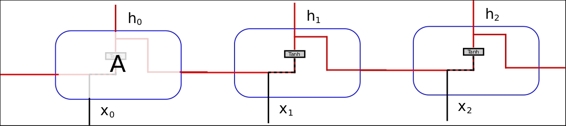
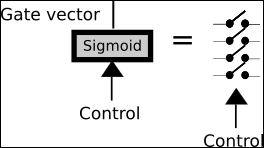
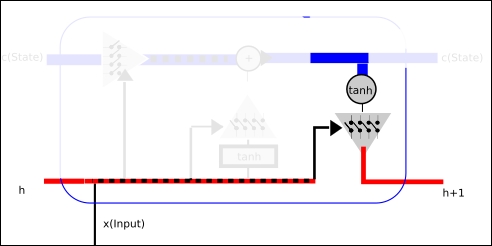
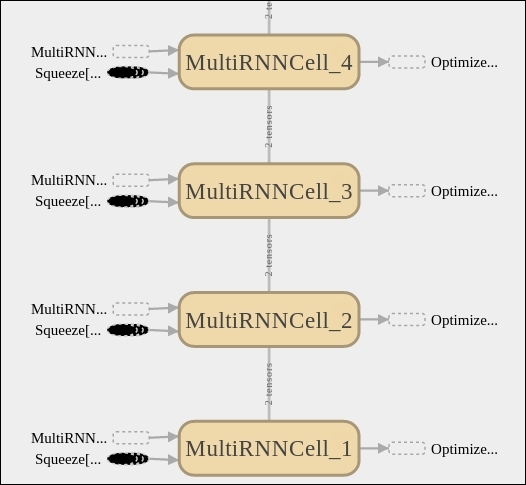
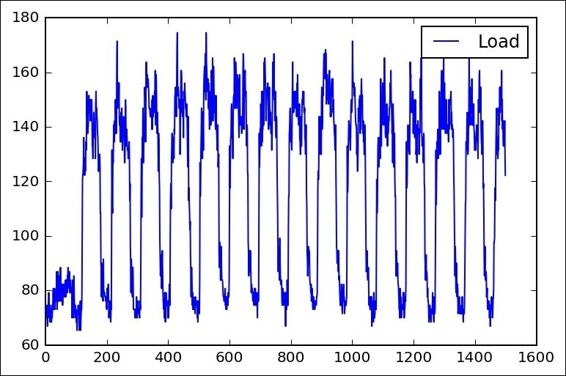
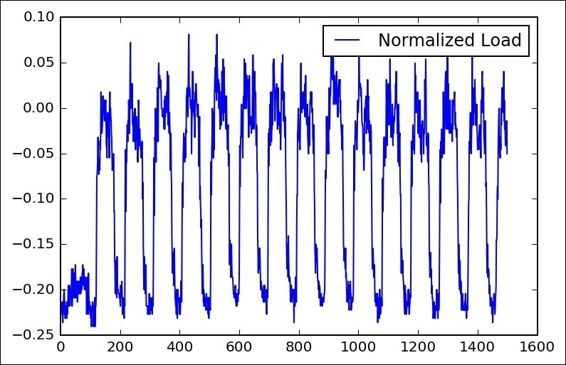
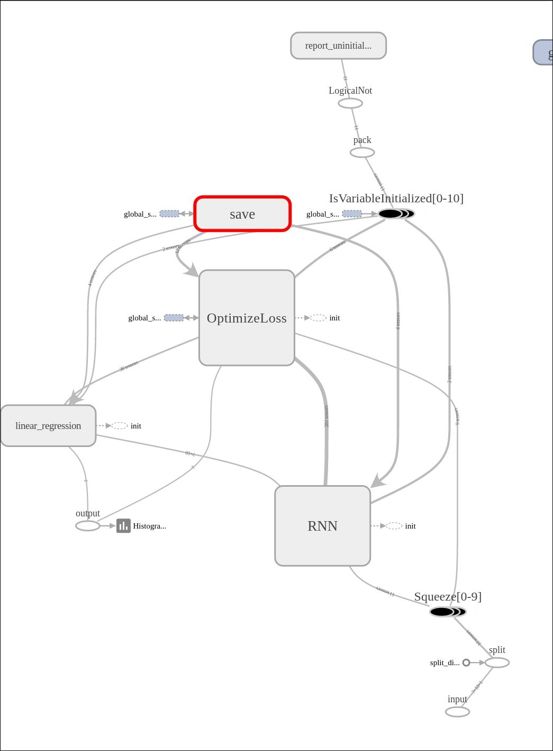
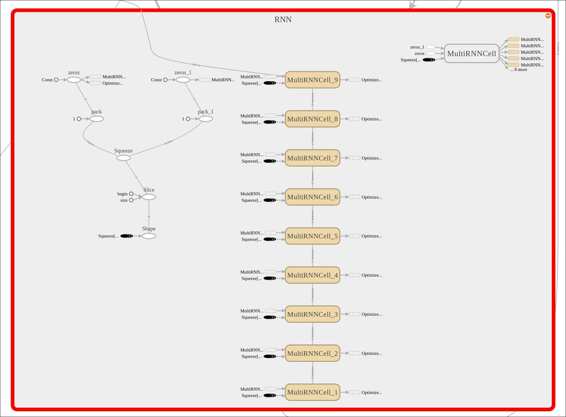
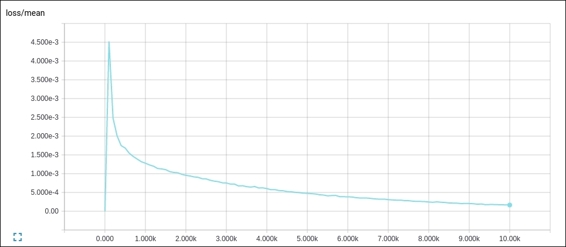
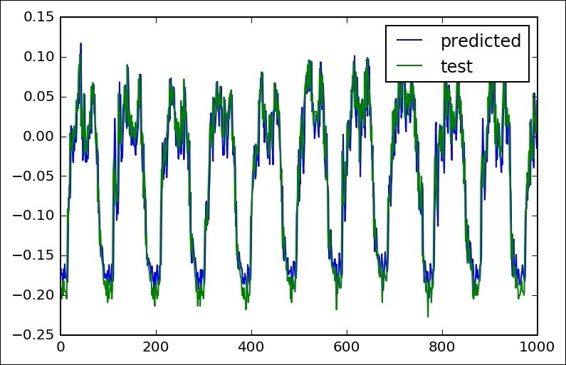
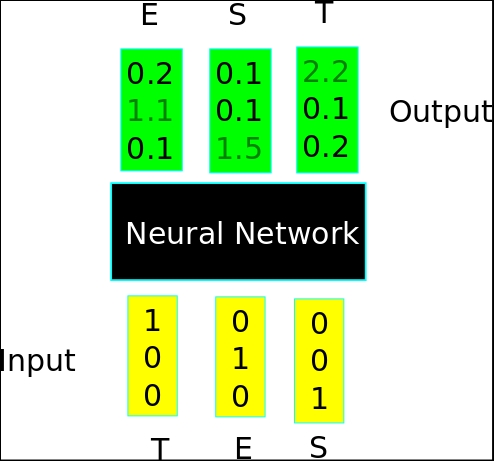
The following is the complete source code(train.py):
from __future__ import print_function
import numpy as np
import tensorflow as tf
import argparse
import time
import os
from six.moves import cPickle
from utils import TextLoader
from model import Model
class arguments:
def __init__(self):
return
def main():
args = arguments()
train(args)
def train(args):
args.data_dir='data/'; args.save_dir='save'; args.rnn_size =64;
args.num_layers=1; args.batch_size=50;args.seq_length=50
args.num_epochs=5;args.save_every=1000; args.grad_clip=5.
args.learning_rate=0.002; args.decay_rate=0.97
data_loader = TextLoader(args.data_dir, args.batch_size, args.seq_length)
args.vocab_size = data_loader.vocab_size
with open(os.path.join(args.save_dir, 'config.pkl'), 'wb') as f:
cPickle.dump(args, f)
with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'wb') as f:
cPickle.dump((data_loader.chars, data_loader.vocab), f)
model = Model(args)
with tf.Session() as sess:
tf.initialize_all_variables().run()
saver = tf.train.Saver(tf.all_variables())
for e in range(args.num_epochs):
sess.run(tf.assign(model.lr, args.learning_rate * (args.decay_rate ** e)))
data_loader.reset_batch_pointer()
state = sess.run(model.initial_state)
for b in range(data_loader.num_batches):
start = time.time()
x, y = data_loader.next_batch()
feed = {model.input_data: x, model.targets: y}
for i, (c, h) in enumerate(model.initial_state):
feed[c] = state[i].c
feed[h] = state[i].h
train_loss, state, _ = sess.run([model.cost, model.final_state, model.train_op], feed)
end = time.time()
print("{}/{} (epoch {}), train_loss = {:.3f}, time/batch = {:.3f}" \
.format(e * data_loader.num_batches + b,
args.num_epochs * data_loader.num_batches,
e, train_loss, end - start))
if (e==args.num_epochs-1 and b == data_loader.num_batches-1): # save for the last result
checkpoint_path = os.path.join(args.save_dir, 'model.ckpt')
saver.save(sess, checkpoint_path, global_step = e * data_loader.num_batches + b)
print("model saved to {}".format(checkpoint_path))
if __name__ == '__main__':
main()
The following is the complete source code (model.py):
import tensorflow as tf
from tensorflow.python.ops import rnn_cell
from tensorflow.python.ops import seq2seq
import numpy as np
class Model():
def __init__(self, args, infer=False):
self.args = args
if infer: #When we sample, the batch and sequence lenght are = 1
args.batch_size = 1
args.seq_length = 1
cell_fn = rnn_cell.BasicLSTMCell #Define the internal cell structure
cell = cell_fn(args.rnn_size, state_is_tuple=True)
self.cell = cell = rnn_cell.MultiRNNCell([cell] * args.num_layers, state_is_tuple=True)
#Build the inputs and outputs placeholders, and start with a zero internal values
self.input_data = tf.placeholder(tf.int32, [args.batch_size, args.seq_length])
self.targets = tf.placeholder(tf.int32, [args.batch_size, args.seq_length])
self.initial_state = cell.zero_state(args.batch_size, tf.float32)
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w", [args.rnn_size, args.vocab_size]) #Final w
softmax_b = tf.get_variable("softmax_b", [args.vocab_size]) #Final bias
with tf.device("/cpu:0"):
embedding = tf.get_variable("embedding", [args.vocab_size, args.rnn_size])
inputs = tf.split(1, args.seq_length, tf.nn.embedding_lookup(embedding, self.input_data))
inputs = [tf.squeeze(input_, [1]) for input_ in inputs]
def loop(prev, _):
prev = tf.matmul(prev, softmax_w) + softmax_b
prev_symbol = tf.stop_gradient(tf.argmax(prev, 1))
return tf.nn.embedding_lookup(embedding, prev_symbol)
outputs, last_state = seq2seq.rnn_decoder(inputs, self.initial_state, cell, loop_function=loop if infer else None, scope='rnnlm')
output = tf.reshape(tf.concat(1, outputs), [-1, args.rnn_size])
self.logits = tf.matmul(output, softmax_w) + softmax_b
self.probs = tf.nn.softmax(self.logits)
loss = seq2seq.sequence_loss_by_example([self.logits],
[tf.reshape(self.targets, [-1])],
[tf.ones([args.batch_size * args.seq_length])],
args.vocab_size)
self.cost = tf.reduce_sum(loss) / args.batch_size / args.seq_length
self.final_state = last_state
self.lr = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars),
args.grad_clip)
optimizer = tf.train.AdamOptimizer(self.lr)
self.train_op = optimizer.apply_gradients(zip(grads, tvars))
def sample(self, sess, chars, vocab, num=200, prime='START', sampling_type=1):
state = sess.run(self.cell.zero_state(1, tf.float32))
for char in prime[:-1]:
x = np.zeros((1, 1))
x[0, 0] = vocab[char]
feed = {self.input_data: x, self.initial_state:state}
[state] = sess.run([self.final_state], feed)
def weighted_pick(weights):
t = np.cumsum(weights)
s = np.sum(weights)
return(int(np.searchsorted(t, np.random.rand(1)*s)))
ret = prime
char = prime[-1]
for n in range(num):
x = np.zeros((1, 1))
x[0, 0] = vocab[char]
feed = {self.input_data: x, self.initial_state:state}
[probs, state] = sess.run([self.probs, self.final_state], feed)
p = probs[0]
sample = weighted_pick(p)
pred = chars[sample]
ret += pred
char = pred
return ret
The following is the complete source code(sample.py):
from __future__ import print_function
import numpy as np
import tensorflow as tf
import time
import os
from six.moves import cPickle
from utils import TextLoader
from model import Model
from six import text_type
class arguments: #Generate the arguments class
save_dir= 'save'
n=1000
prime='x:1\n'
sample=1
def main():
args = arguments()
sample(args) #Pass the argument object
def sample(args):
with open(os.path.join(args.save_dir, 'config.pkl'), 'rb') as f:
saved_args = cPickle.load(f) #Load the config from the standard file
with open(os.path.join(args.save_dir, 'chars_vocab.pkl'), 'rb') as f:
chars, vocab = cPickle.load(f) #Load the vocabulary
model = Model(saved_args, True) #Rebuild the model
with tf.Session() as sess:
tf.initialize_all_variables().run()
saver = tf.train.Saver(tf.all_variables())
ckpt = tf.train.get_checkpoint_state(args.save_dir) #Retrieve the chkpoint
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path) #Restore the model
print(model.sample(sess, chars, vocab, args.n, args.prime, args.sample))
#Execute the model, generating a n char sequence
#starting with the prime sequence
if __name__ == '__main__':
main()
The following is the complete source code(utils.py):
import codecs
import os
import collections
from six.moves import cPickle
import numpy as np
class TextLoader():
def __init__(self, data_dir, batch_size, seq_length, encoding='utf-8'):
self.data_dir = data_dir
self.batch_size = batch_size
self.seq_length = seq_length
self.encoding = encoding
input_file = os.path.join(data_dir, "input.txt")
vocab_file = os.path.join(data_dir, "vocab.pkl")
tensor_file = os.path.join(data_dir, "data.npy")
if not (os.path.exists(vocab_file) and os.path.exists(tensor_file)):
print("reading text file")
self.preprocess(input_file, vocab_file, tensor_file)
else:
print("loading preprocessed files")
self.load_preprocessed(vocab_file, tensor_file)
self.create_batches()
self.reset_batch_pointer()
def preprocess(self, input_file, vocab_file, tensor_file):
with codecs.open(input_file, "r", encoding=self.encoding) as f:
data = f.read()
counter = collections.Counter(data)
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
self.chars, _ = zip(*count_pairs)
self.vocab_size = len(self.chars)
self.vocab = dict(zip(self.chars, range(len(self.chars))))
with open(vocab_file, 'wb') as f:
cPickle.dump(self.chars, f)
self.tensor = np.array(list(map(self.vocab.get, data)))
np.save(tensor_file, self.tensor)
def load_preprocessed(self, vocab_file, tensor_file):
with open(vocab_file, 'rb') as f:
self.chars = cPickle.load(f)
self.vocab_size = len(self.chars)
self.vocab = dict(zip(self.chars, range(len(self.chars))))
self.tensor = np.load(tensor_file)
self.num_batches = int(self.tensor.size / (self.batch_size *
self.seq_length))
def create_batches(self):
self.num_batches = int(self.tensor.size / (self.batch_size *
self.seq_length))
self.tensor = self.tensor[:self.num_batches * self.batch_size * self.seq_length]
xdata = self.tensor
ydata = np.copy(self.tensor)
ydata[:-1] = xdata[1:]
ydata[-1] = xdata[0]
self.x_batches = np.split(xdata.reshape(self.batch_size, -1), self.num_batches, 1)
self.y_batches = np.split(ydata.reshape(self.batch_size, -1), self.num_batches, 1)
def next_batch(self):
x, y = self.x_batches[self.pointer], self.y_batches[self.pointer]
self.pointer += 1
return x, y
def reset_batch_pointer(self):
self.pointer = 0