索引¶ T0>
ndarrays can be indexed using the standard Python x[obj] syntax, where x is the array and obj the selection. 有三种可用的索引:字段访问,基本分片,高级索引。哪一个取决于obj。
注意
In Python, x[(exp1, exp2, ..., expN)] is equivalent to x[exp1, exp2, ..., expN]; the latter is just syntactic sugar for the former.
基本切片和索引¶
基本切片将Python的切片基本概念扩展到N维。当obj是slice对象时(由括号内的start:stop:step符号构造),整数或元组时,基本切片发生切片对象和整数。Ellipsis and newaxis objects can be interspersed with these as well. In order to remain backward compatible with a common usage in Numeric, basic slicing is also initiated if the selection object is any non-ndarray sequence (such as a list) containing slice objects, the Ellipsis object, or the newaxis object, but not for integer arrays or other embedded sequences.
使用N整数索引的最简单情况是返回表示相应项目的array scalar。As in Python, all indices are zero-based: for the i-th index 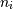 , the valid range is
, the valid range is 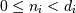 where
where 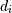 is the i-th element of the shape of the array. 负指数被解释为从数组末尾算起(即,如果
is the i-th element of the shape of the array. 负指数被解释为从数组末尾算起(即,如果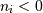 ,则表示
,则表示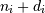 )。
)。
所有由基本切片生成的数组始终都是原始数组的views。
序列切片的标准规则适用于基于每个维度的基本切片(包括使用步骤索引)。一些有用的概念要记住包括:
The basic slice syntax is
i:j:kwhere i is the starting index, j is the stopping index, and k is the step (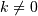 ). This selects the m elements (in the corresponding dimension) with index values i, i + k, ..., i + (m - 1) k where
). This selects the m elements (in the corresponding dimension) with index values i, i + k, ..., i + (m - 1) k where 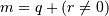 and q and r are the quotient and remainder obtained by dividing j - i by k: j - i = q k + r, so that i + (m - 1) k < j.
and q and r are the quotient and remainder obtained by dividing j - i by k: j - i = q k + r, so that i + (m - 1) k < j.例
>>> x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> x[1:7:2] array([1, 3, 5])
Negative i and j are interpreted as n + i and n + j where n is the number of elements in the corresponding dimension. 负值k使得逐步走向更小的指数。
例
>>> x[-2:10] array([8, 9]) >>> x[-3:3:-1] array([7, 6, 5, 4])
假设n是要切片的维度中的元素数目。那么,如果没有给出i,则它对于k>缺省为0. 对于k <0>和n-1 0。如果未给出j,那么对于k>,缺省为n 0和-1代表k < 0。如果没有给出k,它默认为1。请注意,
::与:相同,并且表示选择沿此轴的所有索引。例
>>> x[5:] array([5, 6, 7, 8, 9])
如果选择元组中的对象数小于N,则假定所有后续维都使用
:。例
>>> x = np.array([[[1],[2],[3]], [[4],[5],[6]]]) >>> x.shape (2, 3, 1) >>> x[1:2] array([[[4], [5], [6]]])
Ellipsisexpand to the number of:objects needed to make a selection tuple of the same length asx.ndim. 可能只有一个省略号存在。例
>>> x[...,0] array([[1, 2, 3], [4, 5, 6]])
选择元组中的每个
newaxis对象用于将结果选择的维度扩展一个单位长度维度。添加的维度是选择元组中newaxis对象的位置。例
>>> x[:,np.newaxis,:,:].shape (2, 1, 3, 1)
除之外,整数i返回与
i:i+1相同的值,返回对象的维度减少1。特别是,带有p -th元素的整数(和所有其他条目:)的选择元组返回维数N-1 < / T3>。如果N = 1那么返回的对象是一个数组标量。这些对象在Scalars中进行了解释。If the selection tuple has all entries
:except the p-th entry which is a slice objecti:j:k, then the returned array has dimension N formed by concatenating the sub-arrays returned by integer indexing of elements i, i+k, ..., i + (m - 1) k < j,在切片元组中使用多个非
:条目进行基本切片,就像使用单个非:条目重复应用切片一样,其中非:条目是连续进行的(所有其他非:条目由:替换)。因此,在基本切片下,x[ind1,...,ind2,:]的作用类似于x[ind1][...,ind2,:]。警告
对于高级索引,上面的不是真。
您可以使用切片来设置数组中的值,但是(不像列表),您永远无法增长数组。在
x [obj] = 值中设置的值的大小必须(可广播)形状与x[obj]相同。
注意
请记住,切片元组可以始终构造为obj并用于x[obj]表示法中。切片对象可以在结构中用来代替[start:stop:step]表示法。For example, x[1:10:5,::-1] can also be implemented as obj = (slice(1,10,5), slice(None,None,-1)); x[obj] . 这对于构造适用于任意维数组的泛型代码很有用。
高级索引¶
当选择对象obj是非元组序列对象,ndarray(数据类型为integer或bool)或一个元组时,触发高级索引一个序列对象或ndarray(数据类型为integer或bool)。高级索引有两种类型:整数和布尔值。
高级索引总是返回数据的副本(与基本切片相比,返回view)。
警告
高级索引的定义意味着x[(1,2,3),]与x[(1,2,3)]后者相当于x[1,2,3],它将触发基本选择,而前者将触发高级索引。一定要明白为什么会发生这种情况。
还认识到x[[1,2,3]]将触发高级索引,而x[[1,2,slice(None)]]将触发基本切片。
整数数组索引¶
整数数组索引允许根据它们的N维索引选择数组中的任意项。每个整数数组代表该维度中的许多索引。
纯整数数组索引¶
当索引由与被索引的数组一样多的整数数组组成时,索引是直截了当的,但与切片不同。
高级索引始终是broadcast并重复为一个:
result[i_1, ..., i_M] == x[ind_1[i_1, ..., i_M], ind_2[i_1, ..., i_M],
..., ind_N[i_1, ..., i_M]]
Note that the result shape is identical to the (broadcast) indexing array shapes ind_1, ..., ind_N.
例
从每一行中选择一个特定的元素。行索引只是[0, 1, 2],并且列索引指定要选择的元素相应的行,这里[0, 1, 0]。一起使用可以使用高级索引解决任务:
>>> x = np.array([[1, 2], [3, 4], [5, 6]])
>>> x[[0, 1, 2], [0, 1, 0]]
array([1, 4, 5])
为了达到类似于上述基本切片的行为,可以使用广播。功能ix_可以帮助进行这种广播。以一个例子来最好地理解这一点。
例
从4x3阵列角落元素应该选择使用先进的索引。因此,该列是[0, 2]之一的所有元素,并且该行是[0 , 3]需要选择。要使用高级索引,需要明确地选择所有元素。使用前面解释的方法可以写出:
>>> x = array([[ 0, 1, 2],
... [ 3, 4, 5],
... [ 6, 7, 8],
... [ 9, 10, 11]])
>>> rows = np.array([[0, 0],
... [3, 3]], dtype=np.intp)
>>> columns = np.array([[0, 2],
... [0, 2]], dtype=np.intp)
>>> x[rows, columns]
array([[ 0, 2],
[ 9, 11]])
然而,由于上面的索引数组只是重复它们自己,所以可以使用广播(比较行[:, np.newaxis] + < / t3> 列)来简化此操作:
>>> rows = np.array([0, 3], dtype=np.intp)
>>> columns = np.array([0, 2], dtype=np.intp)
>>> rows[:, np.newaxis]
array([[0],
[3]])
>>> x[rows[:, np.newaxis], columns]
array([[ 0, 2],
[ 9, 11]])
这种广播也可以通过使用ix_功能来实现:
>>> x[np.ix_(rows, columns)]
array([[ 0, 2],
[ 9, 11]])
请注意,如果没有np.ix_调用,只会选择对角线元素,如前面的示例中所用。这种差异是关于使用多个高级索引进行索引的最重要的事情。
结合高级和基本索引¶
当至少有一个切片(:)时,索引中的省略号(...)或np.newaxis更多的维度比高级索引更高),那么行为可能会更复杂。这就像连接每个高级索引元素的索引结果一样
在最简单的情况下,只有一个单个高级索引。例如,单个高级索引可以替换切片,并且结果数组将是相同的,但是,它是一个副本并且可能具有不同的内存布局。如果可能,切片是优选的。
例
>>> x[1:2, 1:3]
array([[4, 5]])
>>> x[1:2, [1, 2]]
array([[4, 5]])
了解情况的最简单方法可能是根据结果形状来思考。索引操作有两部分,由基本索引(不包括整数)定义的子空间和来自高级索引部分的子空间。需要区分两种指标组合:
- 高级索引由切片,省略号或新轴分开。例如
x [arr1, :, arr2]。 - 高级索引全部紧挨着。For example
x[..., arr1, arr2, :]but notx[arr1, :, 1]since1is an advanced index in this regard.
在第一种情况下,高级索引操作产生的维度在结果数组中首先出现,之后出现子空间维数。在第二种情况下,高级索引操作的维度将插入结果数组中与原始数组中相同的位置(后一种逻辑使得简单的高级索引行为就像分片一样)。
例
Suppose x.shape is (10,20,30) and ind is a (2,3,4)-shaped indexing intp array, then result = x[...,ind,:] has shape (10,2,3,4,30) because the (20,)-shaped subspace has been replaced with a (2,3,4)-shaped broadcasted indexing subspace. 如果我们让(2,3,4)形子空间上的i,j,k循环,那么result [...,i,j,k,:] / t2> = x [...,ind [i,j,k],:]。这个例子产生与x.take(ind, axis=-2)相同的结果。
例
假设x.shape为(10,20,30,40,50),假设ind_1和ind_2可以广播到形状(2 ,3,4)。那么x[:,ind_1,ind_2]具有形状(10,2,3,4,40,50),因为来自X的(20,30)形子空间已被替换为(2 ,3,4)来自指数的子空间。但是,由于在索引子空间中没有明确的地方放置,所以x[:,ind_1,:,ind_2]具有形状(2,3,4,10,30,50),因此它一开始就追上了。始终可以使用.transpose()在任何需要的位置移动子空间。请注意,此示例不能使用take进行复制。
布尔数组索引¶
当obj是布尔类型的数组对象时(例如可能从比较运算符返回),会发生此高级索引。一个布尔索引数组实际上与x[obj.nonzero()]相同,如上所述,obj.nonzero()返回一个元组(长度obj.ndim),它们显示obj的True元素。但是,当obj.shape == x.shape时,它会更快。
如果obj.ndim == x.ndim,x[obj]一个一维数组,填充有x元素,对应于obj的True值。搜索顺序将为row-major,C风格。如果obj在x边界之外的条目处具有True值,则会引发索引错误。如果obj小于x,则与用False填充它相同。
例
一个常见的用例就是过滤所需的元素值。例如,可能希望从数组中选择不是NaN的所有条目:
>>> x = np.array([[1., 2.], [np.nan, 3.], [np.nan, np.nan]])
>>> x[~np.isnan(x)]
array([ 1., 2., 3.])
或者希望为所有负面因素添加一个常数:
>>> x = np.array([1., -1., -2., 3])
>>> x[x < 0] += 20
>>> x
array([ 1., 19., 18., 3.])
通常,如果一个索引包含一个布尔数组,那么结果将与将obj.nonzero()插入到相同位置并使用上述整数数组索引机制相同。x[ind_1, boolean_array, ind_2] is equivalent to x[(ind_1,) + boolean_array.nonzero() + (ind_2,)].
如果只有一个布尔数组并且不存在整数索引数组,那么这很简单。只要注意确保布尔索引的恰好与它应该使用的维数一样多。
例
从一个数组中,选择总和小于或等于2的所有行:
>>> x = np.array([[0, 1], [1, 1], [2, 2]])
>>> rowsum = x.sum(-1)
>>> x[rowsum <= 2, :]
array([[0, 1],
[1, 1]])
但是如果rowsum也有两个维度:
>>> rowsum = x.sum(-1, keepdims=True)
>>> rowsum.shape
(3, 1)
>>> x[rowsum <= 2, :] # fails
IndexError: too many indices
>>> x[rowsum <= 2]
array([0, 1])
由于额外的维度,最后一个只给出第一个元素。比较rowsum.nonzero()来理解这个例子。
Combining multiple Boolean indexing arrays or a Boolean with an integer indexing array can best be understood with the obj.nonzero() analogy. 函数ix_也支持布尔数组,并且没有任何意外。
例
使用布尔索引来选择加起来为偶数的所有行。同时,应使用高级整数索引选择列0和2。使用ix_函数可以通过以下方法完成:
>>> x = array([[ 0, 1, 2],
... [ 3, 4, 5],
... [ 6, 7, 8],
... [ 9, 10, 11]])
>>> rows = (x.sum(-1) % 2) == 0
>>> rows
array([False, True, False, True], dtype=bool)
>>> columns = [0, 2]
>>> x[np.ix_(rows, columns)]
array([[ 3, 5],
[ 9, 11]])
没有np.ix_调用或仅选择对角线元素。
或者没有np.ix_(比较整数数组的例子):
>>> rows = rows.nonzero()[0]
>>> x[rows[:, np.newaxis], columns]
array([[ 3, 5],
[ 9, 11]])
详细说明¶
这些是一些详细的注释,这些注释对于日常索引来说并不重要(没有特定的顺序):
- 本机NumPy索引类型是
intp,并且可能与默认整数数组类型不同。intpis the smallest data type sufficient to safely index any array; for advanced indexing it may be faster than other types. - 对于高级作业,通常不能保证迭代次序。这意味着如果一个元素被多次设置,则不可能预测最终结果。
- 一个空的(元组)索引是一个零维数组的完整标量索引。
x[()]returns a scalar ifxis zero dimensional and a view otherwise. 另一方面,x[...]总是返回一个视图。 - 如果一个零维数组存在于索引和中,则它是一个完整整数索引,结果将是一个标量,而不是一个零维数组。(高级索引不会被触发。)
- 当存在省略号(
...)但没有大小(即替换零:)时,结果将始终是一个数组。查看是否存在高级索引,否则为副本。 - 布尔数组的
nonzero等价不适用于零维布尔数组。 - When the result of an advanced indexing operation has no elements but an individual index is out of bounds, whether or not an
IndexErroris raised is undefined (e.g.x[[], [123]]with123being out of bounds). - 在赋值期间发生铸造错误时(例如使用字符串序列更新数值数组),被分配给的数组可能以不可预知的部分更新状态结束。但是,如果发生任何其他错误(例如超出边界索引),则数组将保持不变。
- 高级索引结果的内存布局针对每个索引操作进行了优化,并且不能假定特定的内存顺序。
- When using a subclass (especially one which manipulates its shape), the default
ndarray.__setitem__behaviour will call__getitem__for basic indexing but not for advanced indexing. 对于这样的子类,最好在数据上用基类 ndarray视图调用ndarray.__setitem__。如果子类__getitem__没有返回视图,则必须完成。
字段访问¶
如果ndarray对象是结构化数组,则可以通过字符串索引数组来访问数组的字段,类似于字典。
索引x['field-name']将返回一个新的view给与x形状相同的数组(除了字段是一个子数组),但数据类型为x.dtype['field-name'],并且只包含指定字段中的部分数据。同样,record array标量可以用这种方式“索引”。
索引到结构化数组中也可以使用字段名列表,例如 x[['field-name1','field-name2']]。目前,这将返回一个新数组,其中包含列表中指定字段值的副本。从NumPy 1.7开始,返回一个副本已被弃用,以支持返回视图。现在将继续返回副本,但写入副本时会发出FutureWarning。如果你依赖当前的行为,那么我们建议显式复制返回的数组,即使用x [['field-name1','field-name2']] copy()。这将适用于NumPy的过去和未来版本。
如果被访问的字段是一个子数组,则子数组的维将被附加到结果的形状中。
例
>>> x = np.zeros((2,2), dtype=[('a', np.int32), ('b', np.float64, (3,3))])
>>> x['a'].shape
(2, 2)
>>> x['a'].dtype
dtype('int32')
>>> x['b'].shape
(2, 2, 3, 3)
>>> x['b'].dtype
dtype('float64')