带有词嵌入的循环神经网络¶
摘要¶
在本教程中,你将学到如何:
- 学习词嵌入
- using Recurrent Neural Networks architectures
- 和上下文窗口
以进行语义分析/Slot-Filling(口语理解)
代码 — 引文 — 联系方式¶
论文¶
如果你使用本教程,请引用以下文章:
- [pdf] Grégoire Mesnil, Xiaodong He, Li Deng and Yoshua Bengio.Investigation of Recurrent-Neural-Network Architectures and Learning Methods for Spoken Language Understanding.Interspeech, 2013.
- [pdf] Gokhan Tur, Dilek Hakkani-Tur and Larry Heck.What is left to be understood in ATIS?
- [pdf] Christian Raymond and Giuseppe Riccardi.Generative and discriminative algorithms for spoken language understanding.Interspeech, 2007.
- [pdf] Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Bergstra, James, Goodfellow, Ian, Bergeron, Arnaud, Bouchard, Nicolas, and Bengio, Yoshua.Theano: new features and speed improvements.NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2012.
- [pdf] Bergstra, James, Breuleux, Olivier, Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Desjardins, Guillaume, Turian, Joseph, Warde-Farley, David, and Bengio, Yoshua.Theano: a CPU and GPU math expression compiler.In Proceedings of the Python for Scientific Computing Conference (SciPy), June 2010.
Thank you!
联系方式¶
如果想报告或反馈任何问题,请发送电子邮件至Grégoire Mesnil (first-add-a-dot-last-add-at-gmail-add-a-dot-com)。我们很高兴收到你的来信。
任务¶
Slot-Filling(口语理解)在于根据给定的一个句子,给每个单词赋予一个标签。It’s a classification task.
数据集¶
这项任务的基准是DARPA收集的ATIS(Airline Travel Information System)数据集,这个数据集有点老而且不大。这里是使用Inside Outside Beginning(IOB)表示的一个示例句子(或话语)。
| 输入(词) | show | flights | from | Boston | to | New | York | today |
| Output (labels) | O | O | O | B-dept | O | B-arr | I-arr | B-date |
ATIS官方的划分在训练/测试集中包含4,978/893个句子,总共有56,590/9,198个词(平均句子长度为15)。类别(不同的槽)的数量是128,包括O标签(NULL)。
作为微软研究人员,对于测试集中未见过的词的处理方式,我们将训练集中仅有一次出现的词标记为<UNK>,然后用这个符号表示测试集中的未见过的词。如 Ronan Collobert and colleagues, 我们将数字的顺序替换了成字符串DIGIT 比如 1984 我们替换成DIGITDIGITDIGITDIGIT.
我们将训练数据集分成训练和却准数据集, 其中训练句比例分别为80%和20%。 由于数据集的数据较少,在95%水平的F1测量中,显著的性能改进差异必须大于0.6%。For evaluation purpose, experiments have to report the following metrics:
我们会使用 conlleval 的PERL 脚本来测量我们模式的性能。
循环神经网络模型¶
原始输入编码¶
一个词符对应于一个单词。ATIS词汇表中的每个词符都关联一个索引。每个句子是一个索引数组(int32)。(train, valid, test)中的每个数据集是一个索引数组组成的列表。定义一个python字典用于将索引空间映射到单词空间。
>>> sentence
array([383, 189, 13, 193, 208, 307, 195, 502, 260, 539,
7, 60, 72, 8, 350, 384], dtype=int32)
>>> map(lambda x: index2word[x], sentence)
['please', 'find', 'a', 'flight', 'from', 'miami', 'florida',
'to', 'las', 'vegas', '<UNK>', 'arriving', 'before', 'DIGIT', "o'clock", 'pm']
Same thing for labels corresponding to this particular sentence.
>>> labels
array([126, 126, 126, 126, 126, 48, 50, 126, 78, 123, 81, 126, 15,
14, 89, 89], dtype=int32)
>>> map(lambda x: index2label[x], labels)
['O', 'O', 'O', 'O', 'O', 'B-fromloc.city_name', 'B-fromloc.state_name',
'O', 'B-toloc.city_name', 'I-toloc.city_name', 'B-toloc.state_name',
'O', 'B-arrive_time.time_relative', 'B-arrive_time.time',
'I-arrive_time.time', 'I-arrive_time.time']
上下文窗口¶
给定一个句子(索引数组)和窗口大小(1,3,5,...),我们需要将句子中的每个单词转换为围绕该特定单词的上下文窗口。In details, we have:
def contextwin(l, win):
'''
win :: int corresponding to the size of the window
given a list of indexes composing a sentence
l :: array containing the word indexes
it will return a list of list of indexes corresponding
to context windows surrounding each word in the sentence
'''
assert (win % 2) == 1
assert win >= 1
l = list(l)
lpadded = win // 2 * [-1] + l + win // 2 * [-1]
out = [lpadded[i:(i + win)] for i in range(len(l))]
assert len(out) == len(l)
return out
The index -1 corresponds to the PADDING index we insert at the beginning/end of the sentence.
Here is a sample:
>>> x
array([0, 1, 2, 3, 4], dtype=int32)
>>> contextwin(x, 3)
[[-1, 0, 1],
[ 0, 1, 2],
[ 1, 2, 3],
[ 2, 3, 4],
[ 3, 4,-1]]
>>> contextwin(x, 7)
[[-1, -1, -1, 0, 1, 2, 3],
[-1, -1, 0, 1, 2, 3, 4],
[-1, 0, 1, 2, 3, 4,-1],
[ 0, 1, 2, 3, 4,-1,-1],
[ 1, 2, 3, 4,-1,-1,-1]]
To summarize, we started with an array of indexes and ended with a matrix of indexes. Each line corresponds to the context window surrounding this word.
词嵌入¶
Once we have the sentence converted to context windows i.e. a matrix of indexes, we have to associate these indexes to the embeddings (real-valued vector associated to each word). Using Theano, it gives:
import theano, numpy
from theano import tensor as T
# nv :: size of our vocabulary
# de :: dimension of the embedding space
# cs :: context window size
nv, de, cs = 1000, 50, 5
embeddings = theano.shared(0.2 * numpy.random.uniform(-1.0, 1.0, \
(nv+1, de)).astype(theano.config.floatX)) # add one for PADDING at the end
idxs = T.imatrix() # as many columns as words in the context window and as many lines as words in the sentence
x = self.emb[idxs].reshape((idxs.shape[0], de*cs))
x符号变量对应于形状矩阵(句子中的词数,嵌入空间的维度 X 上下文窗口大小)。
Let’s compile a theano function to do so
>>> sample
array([0, 1, 2, 3, 4], dtype=int32)
>>> csample = contextwin(sample, 7)
[[-1, -1, -1, 0, 1, 2, 3],
[-1, -1, 0, 1, 2, 3, 4],
[-1, 0, 1, 2, 3, 4,-1],
[ 0, 1, 2, 3, 4,-1,-1],
[ 1, 2, 3, 4,-1,-1,-1]]
>>> f = theano.function(inputs=[idxs], outputs=x)
>>> f(csample)
array([[-0.08088442, 0.08458307, 0.05064092, ..., 0.06876887,
-0.06648078, -0.15192257],
[-0.08088442, 0.08458307, 0.05064092, ..., 0.11192625,
0.08745284, 0.04381778],
[-0.08088442, 0.08458307, 0.05064092, ..., -0.00937143,
0.10804889, 0.1247109 ],
[ 0.11038255, -0.10563177, -0.18760249, ..., -0.00937143,
0.10804889, 0.1247109 ],
[ 0.18738101, 0.14727569, -0.069544 , ..., -0.00937143,
0.10804889, 0.1247109 ]], dtype=float32)
>>> f(csample).shape
(5, 350)
我们现在具有上下文窗口词嵌入的序列(长度为5,对应于句子的长度),其易于馈送到简单的循环神经网络进行迭代。
Elman循环神经网络¶
下面的(Elman)循环神经网络(E-RNN)将当前输入(时间t)和先前的隐藏状态(时间t-1)作为输入。然后它进行迭代。
在上一节中,我们处理过输入以适应这种顺序/时间结构。It consists in a matrix where the row 0 corresponds to the time step t=0, the row 1 corresponds to the time step t=1, etc.
The parameters of the E-RNN to be learned are:
- the word embeddings (real-valued matrix)
- the initial hidden state (real-value vector)
- two matrices for the linear projection of the input
tand the previous hidden layer statet-1 - (optional) bias. Recommendation: don’t use it.
- softmax classification layer on top
The hyperparameters define the whole architecture:
- dimension of the word embedding
- size of the vocabulary
- number of hidden units
- number of classes
- random seed + way to initialize the model
It gives the following code:
class RNNSLU(object):
''' elman neural net model '''
def __init__(self, nh, nc, ne, de, cs):
'''
nh :: dimension of the hidden layer
nc :: number of classes
ne :: number of word embeddings in the vocabulary
de :: dimension of the word embeddings
cs :: word window context size
'''
# parameters of the model
self.emb = theano.shared(name='embeddings',
value=0.2 * numpy.random.uniform(-1.0, 1.0,
(ne+1, de))
# add one for padding at the end
.astype(theano.config.floatX))
self.wx = theano.shared(name='wx',
value=0.2 * numpy.random.uniform(-1.0, 1.0,
(de * cs, nh))
.astype(theano.config.floatX))
self.wh = theano.shared(name='wh',
value=0.2 * numpy.random.uniform(-1.0, 1.0,
(nh, nh))
.astype(theano.config.floatX))
self.w = theano.shared(name='w',
value=0.2 * numpy.random.uniform(-1.0, 1.0,
(nh, nc))
.astype(theano.config.floatX))
self.bh = theano.shared(name='bh',
value=numpy.zeros(nh,
dtype=theano.config.floatX))
self.b = theano.shared(name='b',
value=numpy.zeros(nc,
dtype=theano.config.floatX))
self.h0 = theano.shared(name='h0',
value=numpy.zeros(nh,
dtype=theano.config.floatX))
# bundle
self.params = [self.emb, self.wx, self.wh, self.w,
self.bh, self.b, self.h0]
Then we integrate the way to build the input from the embedding matrix:
idxs = T.imatrix()
x = self.emb[idxs].reshape((idxs.shape[0], de*cs))
y_sentence = T.ivector('y_sentence') # labels
We use the scan operator to construct the recursion, works like a charm:
def recurrence(x_t, h_tm1):
h_t = T.nnet.sigmoid(T.dot(x_t, self.wx)
+ T.dot(h_tm1, self.wh) + self.bh)
s_t = T.nnet.softmax(T.dot(h_t, self.w) + self.b)
return [h_t, s_t]
[h, s], _ = theano.scan(fn=recurrence,
sequences=x,
outputs_info=[self.h0, None],
n_steps=x.shape[0])
p_y_given_x_sentence = s[:, 0, :]
y_pred = T.argmax(p_y_given_x_sentence, axis=1)
Theano will then compute all the gradients automatically to maximize the log-likelihood:
lr = T.scalar('lr')
sentence_nll = -T.mean(T.log(p_y_given_x_sentence)
[T.arange(x.shape[0]), y_sentence])
sentence_gradients = T.grad(sentence_nll, self.params)
sentence_updates = OrderedDict((p, p - lr*g)
for p, g in
zip(self.params, sentence_gradients))
Next compile those functions:
self.classify = theano.function(inputs=[idxs], outputs=y_pred)
self.sentence_train = theano.function(inputs=[idxs, y_sentence, lr],
outputs=sentence_nll,
updates=sentence_updates)
We keep the word embeddings on the unit sphere by normalizing them after each update:
self.normalize = theano.function(inputs=[],
updates={self.emb:
self.emb /
T.sqrt((self.emb**2)
.sum(axis=1))
.dimshuffle(0, 'x')})
And that’s it!
Evaluation¶
With the previous defined functions, you can compare the predicted labels with the true labels and compute some metrics. In this repo, we build a wrapper around the conlleval PERL script. It’s not trivial to compute those metrics due to the Inside Outside Beginning (IOB) representation i.e. a prediction is considered correct if the word-beginning and the word-inside and the word-outside predictions are all correct. Note that the extension is 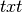 and you will have to change it to
and you will have to change it to 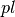 .
.
训练¶
Updates¶
For stochastic gradient descent (SGD) update, we consider the whole sentence as a mini-batch and perform one update per sentence. It is possible to perform a pure SGD (contrary to mini-batch) where the update is done on only one single word at a time.
After each iteration/update, we normalize the word embeddings to keep them on a unit sphere.
停止条件¶
Early-stopping on a validation set is our regularization technique: the training is run for a given number of epochs (a single pass through the whole dataset) and keep the best model along with respect to the F1 score computed on the validation set after each epoch.
超参数选择¶
Although there is interesting research/code on the topic of automatic hyper-parameter selection, we use the KISS random search.
The following intervals can give you some starting point:
- learning rate : uniform([0.05,0.01])
- window size : random value from {3,...,19}
- number of hidden units : random value from {100,200}
- embedding dimension : random value from {50,100}
运行代码¶
After downloading the data using 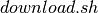 , the user can then run the code by calling:
, the user can then run the code by calling:
python code/rnnslu.py
('NEW BEST: epoch', 25, 'valid F1', 96.84, 'best test F1', 93.79)
[learning] epoch 26 >> 100.00% completed in 28.76 (sec) <<
[learning] epoch 27 >> 100.00% completed in 28.76 (sec) <<
...
('BEST RESULT: epoch', 57, 'valid F1', 97.23, 'best test F1', 94.2, 'with the model', 'rnnslu')
计时¶
Running experiments on ATIS using this repository will run one epoch in less than 40 seconds on i7 CPU 950 @ 3.07GHz using less than 200 Mo of RAM:
[learning] epoch 0 >> 100.00% completed in 34.48 (sec) <<
After a few epochs, you obtain decent performance 94.48 % of F1 score. :
NEW BEST: epoch 28 valid F1 96.61 best test F1 94.19
NEW BEST: epoch 29 valid F1 96.63 best test F1 94.42
[learning] epoch 30 >> 100.00% completed in 35.04 (sec) <<
[learning] epoch 31 >> 100.00% completed in 34.80 (sec) <<
[...]
NEW BEST: epoch 40 valid F1 97.25 best test F1 94.34
[learning] epoch 41 >> 100.00% completed in 35.18 (sec) <<
NEW BEST: epoch 42 valid F1 97.33 best test F1 94.48
[learning] epoch 43 >> 100.00% completed in 35.39 (sec) <<
[learning] epoch 44 >> 100.00% completed in 35.31 (sec) <<
[...]
Word Embedding Nearest Neighbors¶
We can check the k-nearest neighbors of the learned embeddings. L2 and cosine distance gave the same results so we plot them for the cosine distance.
| atlanta | back | ap80 | but | aircraft | business | a | august | actually | cheap |
|---|---|---|---|---|---|---|---|---|---|
| phoenix | live | ap57 | if | plane | coach | people | september | provide | weekday |
| denver | lives | ap | up | service | first | do | january | prices | weekdays |
| tacoma | both | connections | a | airplane | fourth | but | june | stop | am |
| columbus | how | tomorrow | now | seating | thrift | numbers | december | number | early |
| seattle | me | before | amount | stand | tenth | abbreviation | november | flight | sfo |
| minneapolis | out | earliest | more | that | second | if | april | there | milwaukee |
| pittsburgh | other | connect | abbreviation | on | fifth | up | july | serving | jfk |
| ontario | plane | thrift | restrictions | turboprop | third | serve | jfk | thank | shortest |
| montreal | service | coach | mean | mean | twelfth | database | october | ticket | bwi |
| philadelphia | fare | today | interested | amount | sixth | passengers | may | are | lastest |
As you can judge, the limited size of the vocabulary (about 500 words) gives us mitigated performance. According to human judgement: some are good, some are bad.