3 处理原始文本
文本的最重要来源无疑是网络。探索现成的文本集合,如我们在前面章节中看到的语料库,是很方便的。然而,在你心中可能有你自己的文本来源,需要学习如何访问它们。
本章的目的是要回答下列问题:
- 我们怎样才能编写程序访问本地和网络上的文件,从而获得无限的语言材料?
- 我们如何把文档分割成单独的词和标点符号,这样我们就可以开始像前面章节中在文本语料上做的那样的分析?
- 我们怎样编程程序产生格式化的输出,并把结果保存在一个文件中?
为了解决这些问题,我们将讲述NLP中的关键概念,包括分词和词干提取。在此过程中,你会巩固你的Python知识并且了解关于字符串、文件和正则表达式知识。既然这些网络上的文本都是HTML格式的,我们也将看到如何去除HTML标记。
注意
重点: 从本章开始往后我们的例子程序将假设你以下面的导入语句开始你的交互式会话或程序:
|
3.1 从网络和硬盘访问文本
电子书
NLTK 语料库集合中有古腾堡项目的一小部分样例文本。然而,你可能对分析古腾堡项目的其它文本感兴趣。你可以在http://www.gutenberg.org/catalog/上浏览25,000 本免费在线书籍的目录,获得ASCII 码文本文件的URL。虽然90%的古腾堡项目的文本是英语的,它还包括超过50 种语言的材料,包括加泰罗尼亚语、中文、荷兰语、芬兰语、法语、德语、意大利语、葡萄牙语和西班牙语(每种语言都有超过100 个文本)。
编号2554 的文本是《罪与罚》的英文翻译,我们可以如下方式访问它。
|
注意
read()过程将需要几秒钟来下载这本大书。如果你使用的Internet代理Python不能正确检测出来,你可能需要在使用urlopen之前用下面的方法手动指定代理:
|
变量raw包含一个有1,176,893个字符的字符串。(我们使用type(raw)可以看到它是一个字符串。)这是这本书原始的内容,包括很多我们不感兴趣的细节,如空格、换行符和空行。请注意,文件中行尾的\r和\n,这是Python 用来显示特殊的回车和换行字符的方式(这个文件一定是在Windows 机器上创建的)。对于语言处理,我们要将字符串分解为词和标点符号,正如我们在1.中所看到的。这一步被称为分词,它产生我们所熟悉的结构,一个词汇和标点符号的列表。
|
请注意,分词需要NLTK,但所有前面的打开一个URL以及读入一个字符串的任务都不需要。如果我们现在采取进一步的步骤从这个列表创建一个NLTK 文本,我们可以进行我们在1.中看到的所有的其他语言的处理,也包括常规的列表操作例如切片:
|
请注意,Project Gutenberg以一个搭配出现。这是因为从古腾堡项目下载的每个文本都包含一个首部,里面有文本的名称、作者、扫描和校对文本的人的名字、许可证等信息。有时这些信息出现在文件末尾页脚处。我们不能可靠地检测出文本内容的开始和结束,因此在从原始文本中挑出正确内容且没有其它内容之前,我们需要手工检查文件以发现标记内容开始和结尾的独特的字符串:
|
方法find()和rfind()(反向的find)帮助我们得到字符串切片需要用到的正确的索引值![[1]](./static/callout1.gif) 。我们用这个切片重新给raw赋值,所以现在它以“PART I”开始一直到(但不包括)标记内容结尾的句子。
。我们用这个切片重新给raw赋值,所以现在它以“PART I”开始一直到(但不包括)标记内容结尾的句子。
这是我们第一次接触到网络的实际内容:在网络上找到的文本可能含有不必要的内容,并没有一个自动的方法来去除它。但只需要少量的额外工作,我们就可以提取出我们需要的材料。
处理HTML
网络上的文本大部分是HTML文件的形式。你可以使用网络浏览器将网页作为文本保存为本地文件,然后按照下面关于文件的小节描述的那样来访问它。不过,如果你要经常这样做,最简单的办法是直接让Python来做这份工作。第一步是像以前一样使用urlopen。为了好玩,我们将挑选一个被称为Blondes to die out in 200 years的BBC新闻故事,一个都市传奇被BBC作为确立的科学事实流传下来:
|
你可以输入print(html)来查看HTML的全部内容,包括meta 元标签、图像标签、map 标签、JavaScript、表单和表格。
要得到HTML的文本,我们将使用一个名为 BeautifulSoup的Python库,可从 http://www.crummy.com/software/BeautifulSoup/ 访问︰
|
它仍然含有不需要的内容,包括网站导航及有关报道等。通过一些尝试和出错你可以找到内容索引的开始和结尾,并选择你感兴趣的词符,按照前面讲的那样初始化一个文本。
|
处理搜索引擎的结果
网络可以被看作未经标注的巨大的语料库。网络搜索引擎提供了一个有效的手段,搜索大量文本作为有关的语言学的例子。搜索引擎的主要优势是规模:因为你正在寻找这样庞大的一个文件集,会更容易找到你感兴趣语言模式。而且,你可以使用非常具体的模式,仅仅在较小的范围匹配一两个例子,但在网络上可能匹配成千上万的例子。网络搜索引擎的第二个优势是非常容易使用。因此,它是一个非常方便的工具,可以快速检查一个理论是否合理。
表 3.1:
搭配的谷歌命中次数:absolutely或definitely后面跟着adore, love, like或prefer的搭配的命中次数。(Liberman, in LanguageLog, 2005)。
| Google命中次数 | adore | love | like | prefer |
|---|---|---|---|---|
| absolutely | 289,000 | 905,000 | 16,200 | 644 |
| definitely | 1,460 | 51,000 | 158,000 | 62,600 |
| 比率 | 198:1 | 18:1 | 1:10 | 1:97 |
不幸的是,搜索引擎有一些显著的缺点。首先,允许的搜索方式的范围受到严格限制。不同于本地驱动器中的语料库,你可以编写程序来搜索任意复杂的模式,搜索引擎一般只允许你搜索单个词或词串,有时也允许使用通配符。其次,搜索引擎给出的结果不一致,并且在不同的时间或在不同的地理区域会给出非常不同的结果。当内容在多个站点重复时,搜索结果会增加。最后,搜索引擎返回的结果中的标记可能会不可预料的改变,基于模式的方法定位特定的内容将无法使用(通过使用搜索引擎API可以改善这个问题)。
注意
轮到你来: 在网络中搜索"the of" (放在引号中)。基于巨大的数据,我们是否可以得出the of是英语中常用搭配的结论呢?
处理RSS订阅
博客圈是文本的重要来源,无论是正式的还是非正式的。在一个叫做Universal Feed Parser,可从https://pypi.python.org/pypi/feedparser访问,的第三方Python库帮助下,我们可以访问一个博客的内容,如下所示:
|
伴随着一些更深入的工作,我们可以编写程序创建一个博客帖子的小语料库,并以此作为我们NLP的工作基础。
读取本地文件
为了读取本地文件,我们需要使用Python内置的open()函数,然后是read()方法。假设你有一个文件document.txt,你可以像这样加载它的内容:
|
注意
轮到你来: 使用文本编辑器创建一个名为document.txt的文件,然后输入几行文字,保存为纯文本。如果你使用IDLE,在File菜单中选择New Window命令,在新窗口中输入所需的文本,然后在IDLE 提供的弹出式对话框中的文件夹内保存文件为document.txt。然后在Python 解释器中使用f = open('document.txt')打开这个文件,并使用print(f.read())检查其内容。
当你尝试这样做时可能会出各种各样的错误。如果解释器无法找到你的文件,你会看到类似这样的错误:
|
要检查你正试图打开的文件是否在正确的目录中,使用IDLE File菜单上的Open命令;另一种方法是在Python 中检查当前目录:
|
另一个你在访问一个文本文件时可能遇到的问题是换行的约定,这个约定因操作系统不同而不同。内置的open()函数的第二个参数用于控制如何打开文件:open('document.txt', 'rU') —— 'r'意味着以只读方式打开文件(默认),'U'表示“通用”,它让我们忽略不同的换行约定。
假设你已经打开了该文件,有几种方法可以阅读此文件。read()方法创建了一个包含整个文件内容的字符串:
|
回想一'\n'字符是换行符;这相当于按键盘上的Enter开始一个新行。
我们也可以使用一个for循环一次读文件中的一行:
|
在这里,我们使用strip()方法删除输入行结尾的换行符。
NLTK 中的语料库文件也可以使用这些方法来访问。我们只需使用nltk.data.find()来获取语料库项目的文件名。然后就可以使用我们刚才讲的方式打开和阅读它:
|
从PDF、MS Word 及其他二进制格式中提取文本
ASCII 码文本和HTML 文本是人可读的格式。文字常常以二进制格式出现,如PDF 和MSWord,只能使用专门的软件打开。第三方函数库如pypdf和pywin32提供了对这些格式的访问。从多列文档中提取文本是特别具有挑战性的。一次性转换几个文件,会比较简单些,用一个合适的应用程序打开文件,以文本格式保存到本地驱动器,然后以如下所述的方式访问它。如果该文档已经在网络上,你可以在Google 的搜索框输入它的URL。搜索结果通常包括这个文档的HTML 版本的链接,你可以将它保存为文本。
捕获用户输入
有时我们想捕捉用户与我们的程序交互时输入的文本。调用Python 函数input()提示用户输入一行数据。保存用户输入到一个变量后,我们可以像其他字符串那样操纵它。
|
NLP 的流程
3.1 总结了我们在本节涵盖的内容,包括我们在 1. 中所看到的建立一个词汇表的过程。(其中一个步骤,规范化,将在 3.6 讨论。)

图 3.1:处理流程:打开一个URL,读里面HTML 格式的内容,去除标记,并选择字符的切片;然后分词,是否转换为nltk.Text对象是可选择的;我们也可以将所有词汇小写并提取词汇表。
在这条流程后面还有很多操作。要正确理解它,这样有助于明确其中提到的每个变量的类型。使用type(x)我们可以找出任一Python 对象x的类型,如type(1)是<int>因为1是一个整数。
当我们载入一个URL 或文件的内容时,或者当我们去掉HTML 标记时,我们正在处理字符串,也就是Python 的<str>数据类型。(在3.2节,我们将学习更多有关字符串的内容):
|
当我们将一个字符串分词,会产生一个(词的)列表,这是Python 的<list>类型。规范化和排序列表产生其它列表:
|
一个对象的类型决定了它可以执行哪些操作。比如我们可以追加一个链表,但不能追加一个字符串:
|
同样的,我们可以连接字符串与字符串,列表与列表,但我们不能连接字符串与列表:
|
3.2 字符串:最底层的文本处理
现在是时候研究一个之前我们一直故意避开的基本数据类型了。在前面的章节中,我们侧重于将文本作为一个词列表。我们并没有细致的探讨词汇以及它们是如何在编程语言中被处理的。通过使用NLTK 中的语料库接口,我们可以忽略这些文本所在的文件。一个词的内容,一个文件的内容在编程语言中是由一个叫做字符串的基本数据类型来表示的。在本节中,我们将详细探讨字符串,并展示字符串与词汇、文本和文件之间的联系。
字符串的基本操作
可以使用单引号或双引号![[2]](./static/callout2.gif) 来指定字符串,如下面的例子代码所示。如果一个字符串中包含一个单引号,我们必须在单引号前加反斜杠
来指定字符串,如下面的例子代码所示。如果一个字符串中包含一个单引号,我们必须在单引号前加反斜杠![[3]](./static/callout3.gif) 让Python 知道这是字符串中的单引号,或者也可以将这个字符串放入双引号中。否则,字符串内的单引号
让Python 知道这是字符串中的单引号,或者也可以将这个字符串放入双引号中。否则,字符串内的单引号![[4]](./static/callout4.gif) 将被解释为字符串结束标志,Python 解释器会报告一个语法错误:
将被解释为字符串结束标志,Python 解释器会报告一个语法错误:
|
有时字符串跨好几行。Python 提供了多种方式表示它们。在下面的例子中,一个包含两个字符串的序列被连接为一个字符串。我们需要使用反斜杠或者括号,这样解释器就知道第一行的表达式不完整。
|
不幸的是,这些方法并没有展现给我们十四行诗的两行之间的换行。为此,我们可以使用如下所示的三重引号的字符串:
|
现在我们可以定义字符串,也可以在上面尝试一些简单的操作。首先,让我们来看看+操作,被称为连接 。此操作产生一个新字符串,它是两个原始字符串首尾相连粘贴在一起而成。请注意,连接不会做一些比较聪明的事,例如在词汇之间插入空格。我们甚至可以对字符串用乘法:
|
注意
轮到你来: 试运行下面的代码,然后尝试使用你对字符串+和*操作的理解,弄清楚它是如何运作的。要小心区分字符串' ',这是一个空格符,和字符串'',这是一个空字符串。
|
我们已经看到加法和乘法运算不仅仅适用于数字也适用于字符串。但是,请注意,我们不能对字符串用减法或除法:
|
这些错误消息是Python 的另一个例子,告诉我们的数据类型混乱。第一种情况告诉我们减法操作(即-) 不能适用于str(字符串)对象类型,而第二种情况告诉我们除法的两个操作数不能分别为str和int。
输出字符串
到目前为止,当我们想看看变量的内容或想看到计算的结果,我们就把变量的名称输入到解释器。我们还可以使用print语句来看一个变量的内容:
|
请注意这次是没有引号的。当我们通过输入变量的名字到解释器中来检查它时,解释器输出Python 中的变量的值。因为它是一个字符串,结果被引用。然而,当我们告诉解释器print这个变量时,我们没有看到引号字符,因为字符串的内容里面没有引号。
print语句可以多种方式将多个元素显示在一行,就像这样:
|
访问单个字符
正如我们在2看到的列表,字符串也是被索引的,从零开始。当我们索引一个字符串时,我们得到它的一个字符(或字母)。一个单独的字符并没有什么特别,它只是一个长度为1的字符串。
|
与列表一样,如果我们尝试访问一个超出字符串范围的索引时,会得到了一个错误:
|
也与列表一样,我们可以使用字符串的负数索引,其中-1是最后一个字符的索引。正数和负数的索引给我们两种方式指示一个字符串中的任何位置。在这种情况下,当一个字符串长度为12 时,索引5和-7都指示相同的字符(一个空格)。(请注意,5 = len(monty) - 7。)
|
我们可以写一个for循环,遍历字符串中的字符。print函数包含可选的end=' '参数,这是为了告诉Python 不要在行尾输出换行符。
|
我们也可以计数单个字符。通过将所有字符小写来忽略大小写的区分,并过滤掉非字母字符。
|
| [sb] | 在什么地方解释过这个元组拆分? |
这段代码按照出现频率最高排在最先的顺序显示出英文字母(这是一个相当复杂的过程,我们会在以后更仔细地解释)你可能想用fdist.plot()可视化这个分布。一个文本相关的字母频率特征可以用在文本语言自动识别中。
访问子字符串
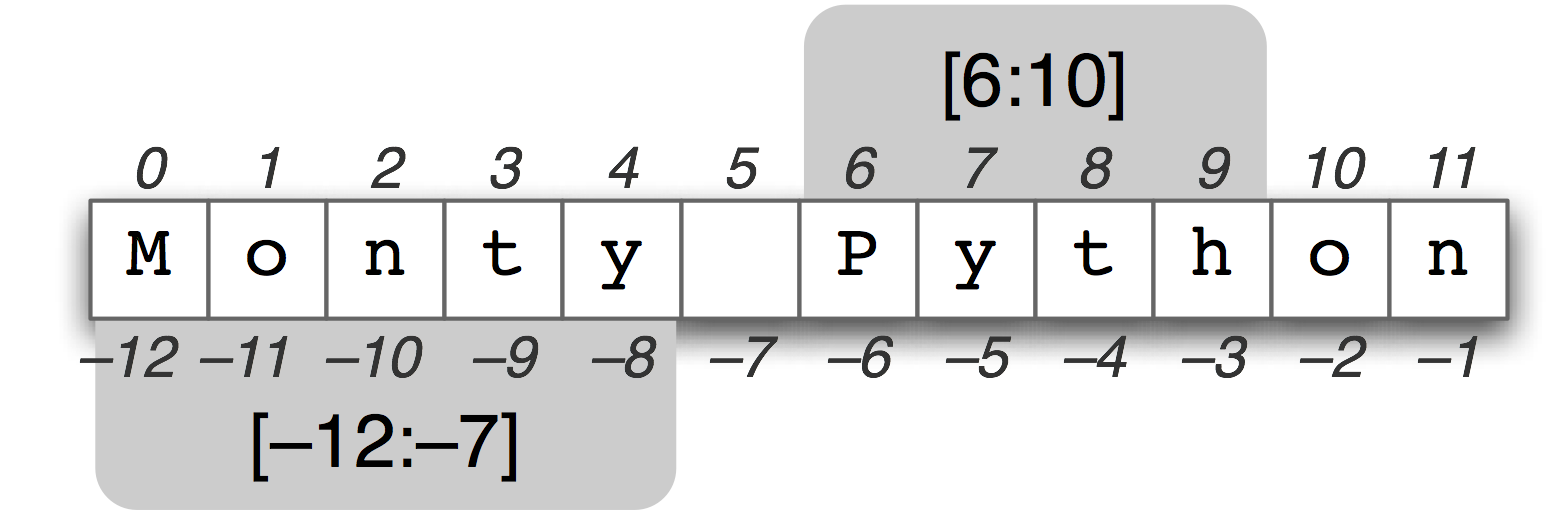
图 3.2:字符串切片:伴随字符串Monty Python显示它的正数和负数索引;两个子字符串都选择使用“切片”符号。切片[m,n]包含从位置m到n-1.中的字符。
一个子字符串是我们为进一步处理而从一个字符串中取出的任意连续片段。我们可以很容易地访问子字符串就像我们对链表进行切片一样(见3.2))。例如:下面的代码访问从索引6到索引10(但不包括)的子字符串:
|
在这里,我们看到的字符是'P', 'y', 't'和'h',它们分别对应于monty[6] ... monty[9]而不包括monty[10]。这是因为切片开始于第一个索引,但结束于最后一个索引的前一个。
我们也可以使用负数索引切片——也是同样的规则,从第一个索引开始到最后一个索引的前一个结束;在这里是在空格字符前结束。
|
与列表切片一样,如果我们省略了第一个值,子字符串将从字符串的开头开始。如果我们省略了第二个值,则子字符串直到字符串的结尾结束:
|
我们使用in操作符测试一个字符串是否包含一个特定的子字符串,如下所示:
|
我们也可以使用find()找到一个子字符串在字符串内的位置:
|
注意
轮到你来: 造一句话,将它分配给一个变量, 例如,sent = 'my sentence...'。写切片表达式抽取个别词。(这显然不是一种方便的方式来处理文本中的词!)
更多的字符串操作
Python 对处理字符串的支持很全面。3.2.所示是一个总结,其中包括一些我们还没有看到的操作。关于字符串的更多信息,可在Python 提示符下输入help(str)。
表 3.2:
有用的字符串方法:4.2中字符串测试之外的字符串上的操作;所有的方法都产生一个新的字符串或列表
| 方法 | 功能 |
|---|---|
| s.find(t) | 字符串s中包含t的第一个索引(没找到返回(-1) |
| s.rfind(t) | 字符串s中包含t的最后一个索引(没找到返回-1) |
| s.index(t) | 与s.find(t)功能类似,但没找到时引起ValueError |
| s.rindex(t) | 与s.rfind(t)功能类似,但没找到时引起ValueError |
| s.join(text) | 使用s连接text中的文本为一个字符串 |
| s.split(t) | 在所有找到t的位置将s分割成列表(默认为空白符) |
| s.splitlines() | 将s按行分割成字符串列表 |
| s.lower() | 小写版本的字符串s |
| s.upper() | 大写版本的字符串s |
| s.title() | 首字母大写版本的字符串s |
| s.strip() | s不带前导或尾随空格的副本 |
| s.replace(t, u) | 用u替换s中的t |
列表与字符串的差异
字符串和列表都是一种序列。我们可以通过索引抽取它们中的一部分,可以给它们切片,可以使用连接将它们合并在一起。但是,字符串和列表之间不能连接:
|
当我们在一个Python 程序中打开并读入一个文件,我们得到一个对应整个文件内容的字符串。如果我们使用一个for循环来处理这个字符串元素,所有我们可以挑选出的只是单个的字符——我们不选择粒度。相比之下,列表中的元素可以很大也可以很小,只要我们喜欢:例如,它们可能是段落、句子、短语、单词、字符。所以,列表的优势是我们可以灵活的决定它包含的元素,相应的后续的处理也变得灵活。因此,我们在一段NLP 代码中可能做的第一件事情就是将一个字符串分词放入一个字符串列表中(3.7)。相反,当我们要将结果写入到一个文件或终端,我们通常会将它们格式化为一个字符串(3.9)。
列表与字符串没有完全相同的功能。列表具有增强的能力使你可以改变其中的元素:
|
另一方面,如果我们尝试在一个字符串上这么做——将query的第0个字符修改为'F'——我们得到:
|
这是因为字符串是不可变的:一旦你创建了一个字符串,就不能改变它。然而,列表是可变的,其内容可以随时修改。作为一个结论,列表支持修改原始值的操作,而不是产生一个新的值。
注意
轮到你来: 通过尝试本章结尾的一些练习,巩固你的字符串知识。
3.3 使用Unicode 进行文字处理
我们的程序经常需要处理不同的语言和不同的字符集。“纯文本”的概念是虚构的。如果你住在讲英语国家,你可能在使用ASCII 码而没有意识到这一点。如果你住在欧洲,你可能使用一种扩展拉丁字符集,包含丹麦语和挪威语中的“ø”,匈牙利语中的“ő”,西班牙和布列塔尼语中的“ñ”,捷克语和斯洛伐克语中的“ň”。在本节中,我们将概述如何使用Unicode 处理使用非ASCII 字符集的文本。
什么是Unicode?
Unicode 支持超过一百万种字符。每个字符分配一个编号,称为编码点。在Python 中,编码点写作\uXXXX的形式,其中XXXX是四位十六进制形式数。
在一个程序中,我们可以像普通字符串那样操纵Unicode 字符串。然而,当Unicode 字符被存储在文件或在终端上显示,它们必须被编码为字节流。一些编码(如ASCII 和Latin-2)中每个编码点使用单字节,所以它们可以只支持Unicode 的一个小的子集,足够单个语言使用了。其它的编码(如UTF-8)使用多个字节,可以表示全部的Unicode 字符。
文件中的文本都是有特定编码的,所以我们需要一些机制来将文本翻译成Unicode——翻译成Unicode叫做解码。相对的,要将Unicode 写入一个文件或终端,我们首先需要将Unicode 转化为合适的编码——这种将Unicode 转化为其它编码的过程叫做编码,如3.3所示。
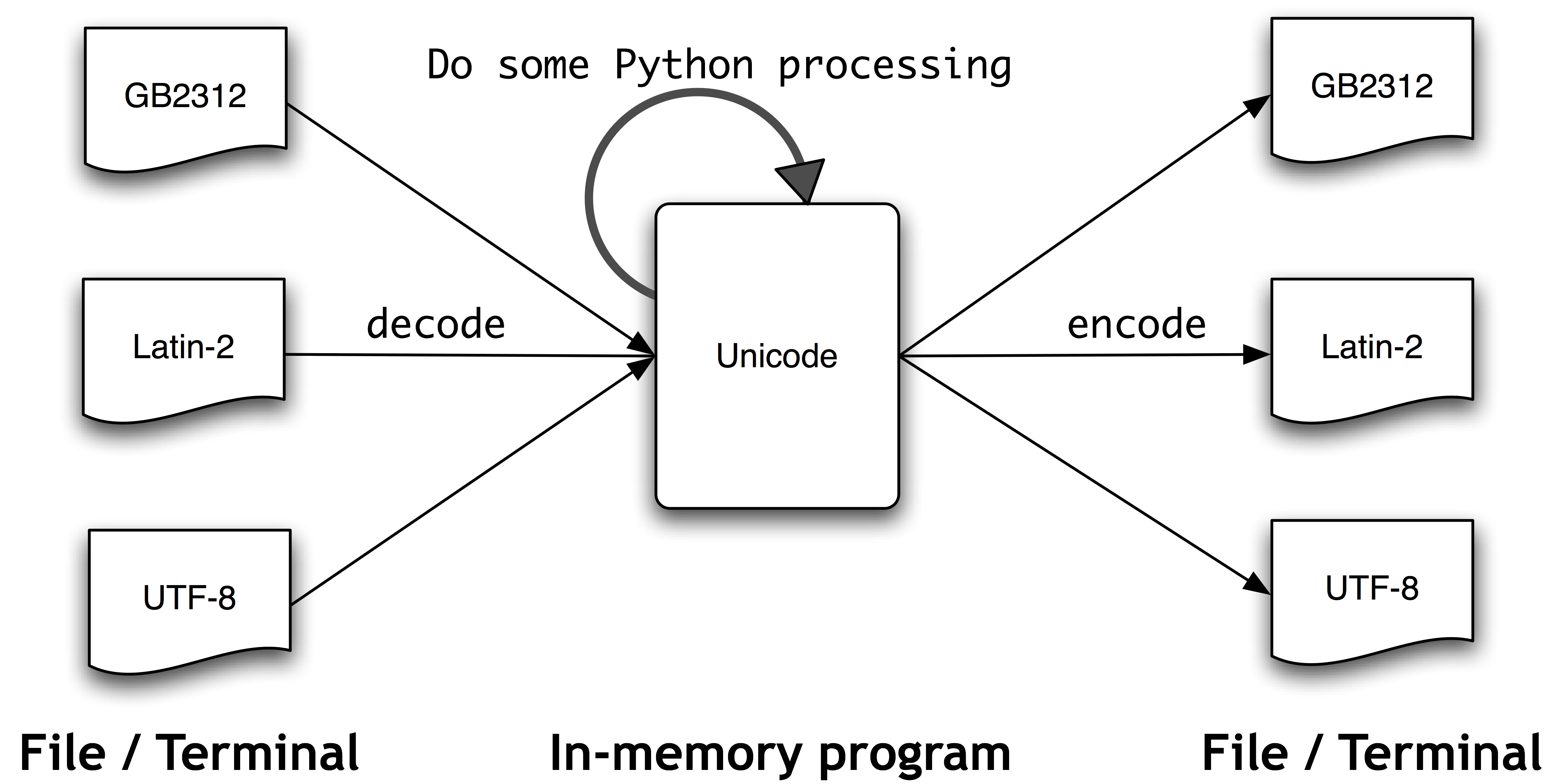
图 3.3:Unicode 解码和编码
从Unicode 的角度来看,字符是可以实现一个或多个字形的抽象的实体。只有字形可以出现在屏幕上或被打印在纸上。一个字体是一个字符到字形映射。
从文件中提取已编码文本
假设我们有一个小的文本文件,我们知道它是如何编码的。例如,polish-lat2.txt顾名思义是波兰语的文本片段(来源波兰语Wikipedia;可以在http://pl.wikipedia.org/wiki/Biblioteka_Pruska中看到)。此文件是Latin-2 编码的,也称为ISO-8859-2。nltk.data.find()函数为我们定位文件。
|
Python的open()函数可以读取编码的数据为Unicode字符串,并写出Unicode字符串的编码形式。它采用一个参数来指定正在读取或写入的文件的编码。因此,让我们使用编码 'latin2'打开我们波兰语文件,并检查该文件的内容︰
|
如果这不能在你的终端正确显示,或者我们想要看到字符的底层数值(或"代码点"),那么我们可以将所有的非 ASCII 字符转换成它们两位数\xXX 和四位数 \uXXXX表示法︰
|
上面输出的第一行有一个以\u转义字符串开始的Unicode转义字符串,即\u0144。相关的Unicode字符在屏幕上将显示为字形ń。在前面例子中的第三行中,我们看到\xf3,对应字形为ó,在128-255 的范围内。
在Python 3中,源代码默认使用UTF-8编码,如果你使用的IDLE或另一个支持Unicode的程序编辑器,你可以在字符串中包含Unicode字符。可以使用\uXXXX转义序列包含任意的Unicode字符。我们使用ord()找到一个字符的整数序数。例如︰
|
324的4位十六进制数字的形式是0144(输入 hex(324) 可以发现这点),我们可以定义一个具有适当转义序列的字符串。
|
注意
决定屏幕上显示的字形的因素很多。如果你确定你的编码正确但你的Python 代码仍然未能显示出你预期的字形,你应该检查你的系统上是否安装了所需的字体。可能需要配置你的区域设置来渲染UTF-8编码的字符,然后使用print(nacute.encode('utf8'))才能在你的终端看到ń显示。
我们还可以看到这个字符在一个文本文件内是如何表示为字节序列的︰
|
unicodedata模块使我们可以检查Unicode字符的属性。在下面的例子中,我们选择超出ASCII范围的波兰语文本的第三行中的所有字符,输出它们的UTF-8 转义值,然后是使用标准Unicode约定的它们的编码点整数(即以U+为前缀的十六进制数字),随后是它们的Unicode名称。
|
如果你使用c替换掉中的c.encode('utf8'),如果你的系统支持UTF-8,你应该看到类似下面的输出:
另外,根据你的系统的具体情况,你可能需要用'latin2'替换示例中的编码'utf8'。
下一个例子展示Python字符串函数和re模块是如何能够与Unicode字符一起工作的。(我们会在下面一节中仔细看看re 模块。\w匹配一个"单词字符",参见3.4)。
|
NLTK分词器允许Unicode字符串作为输入,并输出相应地Unicode字符串。
|
在Python中使用本地编码
如果你习惯了使用特定的本地编码字符,你可能希望能够在一个Python文件中使用你的字符串输入及编辑的标准方法。为了做到这一点,你需要在你的文件的第一行或第二行中包含字符串:'# -*- coding: <coding> -*-'。请注意<coding>必须是像'latin-1', 'big5'或'utf-8'这样的字符串 (见 3.4)。
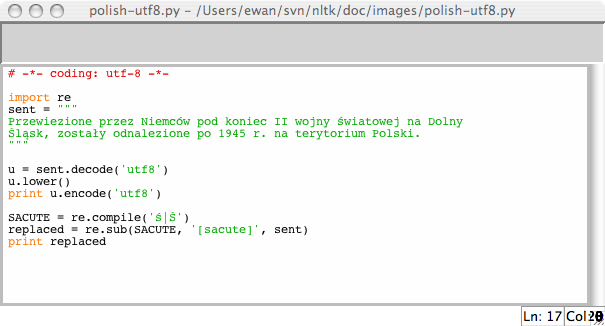
图 3.4:Unicode 与IDLE:IDLE编辑器中UTF-8编码的字符串字面值;这需要在IDLE属性中设置了相应的字体;这里我们选择Courier CE。
上面的例子还说明了正规表达式是如何可以使用编码的字符串的。
3.4 使用正则表达式检测词组搭配
许多语言处理任务都涉及模式匹配。例如:我们可以使用endswith('ed')找到以ed结尾的词。在4.2中我们看到过各种这样的“词测试”。正则表达式给我们一个更加强大和灵活的方法描述我们感兴趣的字符模式。
注意
介绍正则表达式的其他出版物有很多,它们围绕正则表达式的语法组织,应用于搜索文本文件。我们不再赘述这些,只专注于在语言处理的不同阶段如何使用正则表达式。像往常一样,我们将采用基于问题的方式,只在解决实际问题需要时才介绍新特性。在我们的讨论中,我们将使用箭头来表示正则表达式,就像这样:«patt»。
在Python中使用正则表达式,需要使用import re导入re库。我们还需要一个用于搜索的词汇列表;我们再次使用词汇语料库(4)。我们将对它进行预处理消除某些名称。
|
使用基本的元字符
让我们使用正则表达式«ed$»查找以ed结尾的词汇。我们将使用函数re.search(p, s)检查字符串s中是否有模式p。我们需要指定感兴趣的字符,然后使用美元符号,它是正则表达式中有特殊用途的符号,用来匹配单词的末尾:
|
.通配符匹配任何单个字符。假设我们有一个8 个字母组成的词的字谜室,j是其第三个字母,t是其第六个字母。空白单元格中的每个地方,我们用一个句点:
|
注意
轮到你来: 驼字符^匹配字符串的开始,就像$符号匹配字符串的结尾。如果我们不用这两个符号而使用«..j..t..»搜索,刚才例子中我们会得到什么样的结果?
最后,?符合表示前面的字符是可选的。因此«^e-?mail$» 将匹配email和e-mail。我们可以使用sum(1 for w in text if re.search('^e-?mail$', w))计数一个文本中这个词(任一拼写形式)出现的总次数。
范围与闭包
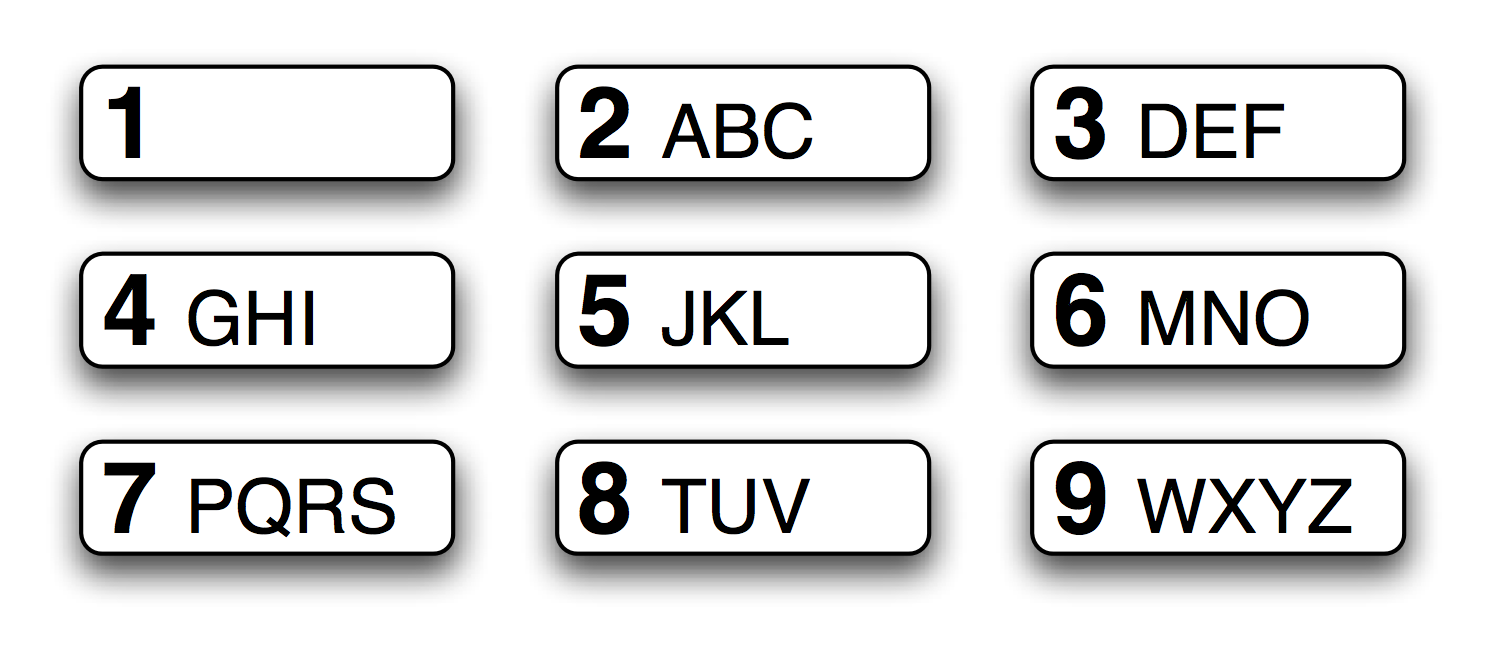
图 3.5:T9:9个键上的文本
T9系统用于在手机上输入文本(见3.5))。两个或两个以上以相同击键顺序输入的词汇,叫做textonyms。例如,hole和golf都是通过序列4653输入。还有哪些其它词汇由相同的序列产生?这里我们使用正则表达式«^[ghi][mno][jlk][def]$»:
|
表达式的第一部分«^[ghi]»匹配以g, h或i开始的词。表达式的下一部分,«[mno]»限制了第二个字符是m, n或o。第三部分和第四部分同样被限制。只有4个单词满足这些限制。注意,方括号内的字符的顺序是没有关系的,所以我们可以写成«^[hig][nom][ljk][fed]$» 并匹配同样的词汇。
注意
轮到你来: 来看一些“手指绕口令”,只用一部分数字键盘搜索词汇。例如«^[ghijklmno]+$»或更为简洁的«^[g-o]+$»,将匹配只使用中间行的4、5、6 键的词汇«^[a-fj-o]+$»将匹配使用右上角2、3、5、6 键的词汇。-和+表示什么意思?
让我们进一步探索+符号。请注意,它可以适用于单个字母或括号内的字母集:
|
很显然,+简单地表示“前面的项目的一个或多个实例”,它可以是单独的字母如m,可以是一个集合如[fed]或者一个范围如[d-f]。现在让我们用*替换+,它表示“前面的项目的零个或多个实例”。正则表达式«^m*i*n*e*$»将匹配所有我们用«^m+i+n+e+$»找到的,同时包括其中一些字母不出现的词汇,例如,me, min和mmmmm。请注意+和*符号有时被称为的Kleene闭包,或者干脆闭包。
运算符^当它出现在方括号内的第一个字符位置时有另外的功能。例如,«[^aeiouAEIOU]»匹配除元音字母之外的所有字母。我们可以搜索NPS 聊天语料库中完全由非元音字母组成的词汇,使用«^[^aeiouAEIOU]+$» 查找诸如:):):), grrr, cyb3r和zzzzzzzz这样的词。请注意其中包含非字母字符。
下面是另外一些正则表达式的例子,用来寻找匹配特定模式的词符,这些例子演示如何使用一些新的符号:\, {}, ()和|。
|
注意
轮到你来: 研究前面的例子,在你继续阅读之前尝试弄清楚\, {}, ()和| 这些符号的功能。
你可能已经知道反斜杠表示其后面的字母不再有特殊的含义而是按照字面的表示匹配词中特定的字符。因此,虽然.很特别,但是\.只匹配一个句号。大括号表达式,如{3,5}, 表示前面的项目重复指定次数。管道字符表示从其左边的内容和右边的内容中选择一个。圆括号表示一个操作符的范围,它们可以与管道(或叫析取)符号一起使用,如«w(i|e|ai|oo)t»,匹配wit, wet, wait和woot。你可以省略这个例子里的最后一个表达式中的括号,使用«ed|ing$»搜索看看会发生什么,这是很有益处的。
我们已经看到的元字符总结在3.3中:
表 3.3:
正则表达式基本元字符,其中包括通配符,范围和闭包
| 操作符 | 行为 |
|---|---|
| . | 通配符,匹配所有字符 |
| ^abc | 匹配以abc开始的字符串 |
| abc$ | 匹配以abc结尾的字符串 |
| [abc] | 匹配字符集合中的一个 |
| [A-Z0-9] | 匹配字符范围中的一个 |
| ed|ing|s | 匹配指定的一个字符串(析取) |
| * | 前面的项目零个或多个,例如a*, [a-z]*(也叫Kleene 闭包) |
| + | 前面的项目1 个或多个,例如a+, [a-z]+ |
| ? | 前面的项目零个或1 个(即可选),例如a?, [a-z]? |
| {n} | 精确重复n次,n为非负整数 |
| {n,} | 至少重复n次 |
| {,n} | 重复不多于n次 |
| {m,n} | 至少重复m次不多于n次 |
| a(b|c)+ | 括号表示操作符的范围 |
对Python解释器而言,一个正则表达式与任何其他字符串没有两样。如果字符串中包含一个反斜杠后面跟一些特殊字符,Python解释器将会特殊处理它们。例如,\b会被解释为一个退格符号。一般情况下,当使用含有反斜杠的正则表达式时,我们应该告诉解释器一定不要解释字符串里面的符号,而仅仅是将它直接传递给re库来处理。我们通过给字符串加一个前缀r,来表明它是一个原始字符串。例如:原始字符串r'\band\b'包含两个\b符号会被re库解释为匹配词的边界而不是解释为退格字符。如果你能逐渐习惯使用r'...'表示正则表达式——就像从现在开始我们将做的那样——你将会避免去想这些解释上的歧义。
3.5 正则表达式的有益应用
前面的例子都涉及到使用re.search(regexp, w)匹配一些正则表达式regexp来搜索词w。除了检查一个正则表达式是否匹配一个单词外,我们还可以使用正则表达式从词汇中提取的特征或以特殊的方式来修改词。
提取单词片段
re.findall()(“find all”)方法找出指定正则表达式的所有(无重叠的)匹配。让我们找出一个词中的元音,再计数它们:
|
让我们来看看一些文本中的两个或两个以上的元音序列,并确定它们的相对频率:
|
注意
轮到你来: 在W3C 日期时间格式中,日期像这样表示:2009-12-31。Replace the ? in the following Python code with a regular expression, in order to convert the string '2009-12-31' to a list of integers [2009, 12, 31]:
[int(n) for n in re.findall(?, '2009-12-31')]
在单词片段上做更多事情
一旦我们会使用re.findall()从单词中提取素材,就可以在这些片段上做一些有趣的事情,例如将它们粘贴在一起或用它们绘图。
英文文本是高度冗余的,忽略掉词内部的元音仍然可以很容易的阅读,有些时候这很明显。例如,declaration变成dclrtn,inalienable变成inlnble,保留所有词首或词尾的元音序列。在我们的下一个例子中,正则表达式匹配词首元音序列,词尾元音序列和所有的辅音;其它的被忽略。这三个析取从左到右处理,如果词匹配三个部分中的一个,正则表达式后面的部分将被忽略。我们使用re.findall()提取所有匹配的词中的字符,然后使''.join()将它们连接在一起(更多连接操作参见3.9)。
|
接下来,让我们将正则表达式与条件频率分布结合起来。在这里,我们将从罗托卡特语词汇中提取所有辅音-元音序列,如ka和si。因为每部分都是成对的,它可以被用来初始化一个条件频率分布。然后我们为每对的频率画出表格:
|
考查s行和t行,我们看到它们是部分的“互补分布”,这个证据表明它们不是这种语言中的独特音素。从而我们可以令人信服的从罗托卡特语字母表中去除s,简单加入一个发音规则:当字母t跟在i后面时发s的音。(注意单独的条目su即kasuari,‘cassowary’是从英语中借来的)。
如果我们想要检查表格中数字背后的词汇,有一个索引允许我们迅速找到包含一个给定的辅音-元音对的单词的列表将会有帮助,例如,cv_index['su']应该给我们所有含有su的词汇。下面是我们如何能做到这一点:
|
这段代码依次处理每个词w,对每一个词找出匹配正则表达式«[ptksvr][aeiou]»的所有子字符串。对于词kasuari,它找到ka, su和ri。因此,cv_word_pairs将包含('ka', 'kasuari'), ('su', 'kasuari')和('ri', 'kasuari')。更进一步使用nltk.Index()转换成有用的索引。
查找词干
在使用网络搜索引擎时,我们通常不介意(甚至没有注意到)文档中的词汇与我们的搜索条件的后缀形式是否相同。查询laptops会找到含有laptop的文档,反之亦然。事实上,laptop与laptops只是词典中的同一个词(或词条)的两种形式。对于一些语言处理任务,我们想忽略词语结尾,只是处理词干。
抽出一个词的词干的方法有很多种。这里的是一种简单直观的方法,直接去掉任何看起来像一个后缀的字符:
|
虽然我们最终将使用NLTK 中内置的词干提取器,看看我们如何能够使用正则表达式处理这个任务是有趣的。我们的第一步是建立一个所有后缀的连接。我们需要把它放在括号内以限制这个析取的范围。
|
在这里,尽管正则表达式匹配整个单词,re.findall()只是给我们后缀。这是因为括号有第二个功能:选择要提取的子字符串。如果我们要使用括号来指定析取的范围,但不想选择要输出的字符串,必须添加?:,它是正则表达式许多神秘奥妙的地方之一。下面是改进后的版本。
|
然而,实际上,我们会想将词分成词干和后缀。所以,我们应该用括号括起正则表达式的这两个部分:
|
这看起来很有用途,但仍然有一个问题。让我们来看看另外的词,processes:
|
正则表达式错误地找到了后缀-s,而不是后缀-es。这表明另一个微妙之处:星号操作符是“贪婪的”,所以表达式的.*部分试图尽可能多的匹配输入的字符串。如果我们使用“非贪婪”版本的“*”操作符,写成*?,我们就得到我们想要的:
|
我们甚至可以通过使第二个括号中的内容变成可选,来得到空后缀:
|
这种方法仍然有许多问题,(你能发现它们吗?)但我们仍将继续定义一个函数来获取词干,并将它应用到整个文本:
|
请注意我们的正则表达式不但将 ponds 的 s 删除,也将 is 和 basis 的删除。它产生一些非词如distribut和deriv,但这些在一些应用中是可接受的词干。
搜索已分词文本
你可以使用一种特殊的正则表达式搜索一个文本中多个词(这里的文本是一个词符列表)。例如,"<a> <man>"找出文本中所有a man的实例。尖括号用于标记词符的边界,尖括号之间的所有空白都被忽略(这只对NLTK中的findall()方法处理文本有效)。在下面的例子中,我们使用<.*>,它将匹配所有单个词符,将它括在括号里,于是只匹配词(例如monied)而不匹配短语(例如,a monied man)会生成。第二个例子找出以词bro结尾的三个词组成的短语。最后一个例子找出以字母l开始的三个或更多词组成的序列。
|
注意
轮到你来:巩固你对正则表达式模式与替换的理解,使用nltk.re_show(p, s),它能标注字符串s中所有匹配模式p的地方,以及nltk.app.nemo(),它能提供一个探索正则表达式的图形界面。更多的练习,可以尝试本章尾的正则表达式的一些练习。
当我们研究的语言现象与特定词语相关时建立搜索模式是很容易的。在某些情况下,一个小小的创意可能会花很大功夫。例如,在大型文本语料库中搜索x and other ys形式的表达式能让我们发现上位词(见5):
|
只要有足够多的文本,这种做法会给我们一整套有用的分类标准信息,而不需要任何手工劳动。然而,我们的搜索结果中通常会包含误报,即我们想要排除的情况。例如,结果demands and other factors暗示demand是类型factor的一个实例,但是这句话实际上是关于要求增加工资的。尽管如此,我们仍可以通过手工纠正这些搜索的结果来构建自己的英语概念的本体。
注意
这种自动和人工处理相结合的方式是最常见的建造新的语料库的方式。我们将在11.继续讲述这些。
搜索语料也会有遗漏的问题,即漏掉了我们想要包含的情况。仅仅因为我们找不到任何一个搜索模式的实例,就断定一些语言现象在一个语料库中不存在,是很冒险的。也许我们只是没有足够仔细的思考合适的模式。
注意
轮到你来: 查找模式as x as y的实例以发现实体及其属性信息。
3.6 规范化文本
在前面的程序例子中,我们在处理文本词汇前经常要将文本转换为小写,即set(w.lower() for w in text)。通过使用lower()我们将文本规范化为小写,这样一来The与the的区别被忽略。我们常常想比这走得更远,去掉所有的词缀以及提取词干的任务等。更进一步的步骤是确保结果形式是字典中确定的词,即叫做词形归并的任务。我们依次讨论这些。首先,我们需要定义我们将在本节中使用的数据:
|
词干提取器
NLTK 中包括几个现成的词干提取器,如果你需要一个词干提取器,你应该优先使用它们中的一个,而不是使用正则表达式制作自己的词干提取器,因为NLTK 中的词干提取器能处理的不规则的情况很广泛。Porter 和Lancaster 词干提取器按照它们自己的规则剥离词缀。请看Porter词干提取器正确处理了词lying(将它映射为lie),而Lancaster词干提取器并没有处理好。
|
词干提取过程没有明确定义,我们通常选择心目中最适合我们的应用的词干提取器。如果你要索引一些文本和使搜索支持不同词汇形式的话,Porter词干提取器是一个很好的选择(3.6 所示,它采用面向对象编程技术,这超出了本书的范围,字符串格式化技术将在3.9讲述,enumerate()函数将在4.2解释)。
| ||
| ||
例 3.6 (code_stemmer_indexing.py):图 3.6:使用词干提取器索引文本 |
词形归并
WordNet词形归并器只在产生的词在它的词典中时才删除词缀。这个额外的检查过程使词形归并器比刚才提到的词干提取器要慢。请注意,它并没有处理lying,但它将women转换为woman。
|
如果你想编译一些文本的词汇,或者想要一个有效词条(或中心词)列表,WordNet词形归并器是一个不错的选择。
注意
另一个规范化任务涉及识别非标准词,包括数字、缩写、日期以及映射任何此类词符到一个特殊的词汇。例如,每一个十进制数可以被映射到一个单独的标识符0.0,每首字母缩写可以映射为AAA。这使词汇量变小,提高了许多语言建模任务的准确性。
3.7 用正则表达式为文本分词
分词是将字符串切割成可识别的构成一块语言数据的语言单元。虽然这是一项基础任务,我们能够一直拖延到现在为止才讲,是因为许多语料库已经分过词了,也因为NLTK中包括一些分词器。现在你已经熟悉了正则表达式,你可以学习如何使用它们来为文本分词,并对此过程中有更多的掌控权。
分词的简单方法
文本分词的一种非常简单的方法是在空格符处分割文本。考虑以下摘自《爱丽丝梦游仙境》中的文本:
|
我们可以使用raw.split()在空格符处分割原始文本。使用正则表达式能做同样的事情,匹配字符串中的所有空格符是不够的,因为这将导致分词结果包含\n换行符;我们需要匹配任何数量的空格符、制表符或换行符:
|
正则表达式«[ \t\n]+»匹配一个或多个空格、制表符(\t)或换行符(\n)。其他空白字符,如回车和换页符,实际上应该也包含。于是,我们将使用一个re库内置的缩写\s,它表示匹配所有空白字符。前面的例子中第二条语句可以改写为re.split(r'\s+', raw)。
注意
要点: 记住在正则表达式前加字母r(表示"原始的"),它告诉Python解释器按照字面表示对待字符串,而不去处理正则表达式中包含的反斜杠字符。
在空格符处分割文本给我们如'(not'和'herself,'这样的词符。另一种方法是使用Python提供给我们的字符类\w匹配词中的字符,相当于[a-zA-Z0-9_]。它还定义了这个类的补集\W,即所有字母、数字和下划线以外的字符。我们可以在一个简单的正则表达式中用\W来分割所有单词字符以外的输入:
|
可以看到,在开始和结尾都给了我们一个空字符串(要了解原因请尝试'xx'.split('x'))。通过re.findall(r'\w+', raw)使用模式匹配词汇而不是空白符号,我们得到相同的标识符,但没有空字符串。现在,我们正在匹配词汇,我们处在扩展正则表达式覆盖更广泛的情况的位置。正则表达式«\w+|\S\w*»将首先尝试匹配词中字符的所有序列。如果没有找到匹配的,它会尝试匹配后面跟着词中字符的任何非空白字符(\S是\s的补)。这意味着标点会与跟在后面的字母(如's)在一起,但两个或两个以上的标点字符序列会被分割。
|
让我们扩展前面表达式中的\w+,允许连字符和撇号:«\w+([-']\w+)*»。这个表达式表示\w+后面跟零个或更多[-']\w+的实例;它会匹配hot-tempered和it's。(我们需要在这个表达式中包含?:,原因前面已经讨论过。)我们还将添加一个模式来匹配引号字符,让它们与它们包括的文字分开。
|
上面的表达式也包括«[-.(]+»,这会使双连字符、省略号和左括号被单独分词。
3.4列出了我们已经在本节中看到的正则表达式字符类符号,以及一些其他有用的符号。
表 3.4:
正则表达式符号
| 符号 | 功能 |
|---|---|
| \b | 词边界(零宽度) |
| \d | 任一十进制数字(相当于[0-9]) |
| \D | 任何非数字字符(等价于[^0-9]) |
| \s | 任何空白字符(相当于[ \t\n\r\f\v]) |
| \S | 任何非空白字符(相当于[^ \t\n\r\f\v]) |
| \w | 任何字母数字字符(相当于[a-zA-Z0-9_]) |
| \W | 任何非字母数字字符(相当于[^a-zA-Z0-9_]) |
| \t | 制表符 |
| \n | 换行符 |
NLTK 的正则表达式分词器
函数nltk.regexp_tokenize()与re.findall()类似(我们一直在使用它进行分词)。然而,nltk.regexp_tokenize()分词效率更高,且不需要特殊处理括号。为了增强可读性,我们将正则表达式分几行写,每行添加一个注释。特别的(?x) "verbose 标志”告诉Python去掉嵌入的空白字符和注释。
|
使用verbose 标志时,不可以再使用' '来匹配一个空格字符;使用\s代替。regexp_tokenize()函数有一个可选的gaps参数。设置为True时,正则表达式指定标识符间的距离,就像使用re.split()一样。
注意
我们可以使用set(tokens).difference(wordlist)通过比较分词结果与一个词表,然后报告任何没有在词表出现的标识符,来评估一个分词器。你可能想先将所有标记变成小写。
分词的进一步问题
分词是一个比你可能预期的要更为艰巨的任务。没有单一的解决方案能在所有领域都行之有效,我们必须根据应用领域的需要决定那些是词符。
在开发分词器时,访问已经手工分词的原始文本是有益的,这可以让你的分词器的输出结果与高品质(或称“黄金标准”)的词符进行比较。NLTK语料库集合包括宾州树库的数据样本,包括《华尔街日报》原始文本(nltk.corpus.treebank_raw.raw())和分好词的版本(nltk.corpus.treebank.words())。
分词的最后一个问题是缩写的存在,如didn't。如果我们想分析一个句子的意思,将这种形式规范化为两个独立的形式:did 和 n't(或 not)可能更加有用。我们可以通过查表来做这项工作。
3.8 分割
本节将讨论更高级的概念,你在第一次阅读本章时可能更愿意跳过本节。
分词是一个更普遍的分割问题的一个实例。在本节中,我们将看到这个问题的另外两个实例,它们使用与到目前为止我们已经在本章看到的完全不同的技术。
断句
在词级水平处理文本通常假定能够将文本划分成单个句子。正如我们已经看到,一些语料库已经提供句子级别的访问。在下面的例子中,我们计算布朗语料库中每个句子的平均词数:
|
在其他情况下,文本可能只是作为一个字符流。在将文本分词之前,我们需要将它分割成句子。NLTK通过包含Punkt 句子分割器(Kiss & Strunk, 2006)使得这个功能便于使用。这里是使用它为一篇小说文本断句的例子。(请注意,如果在你读到这篇文章时分割器内部数据已经更新过,你会看到不同的输出):
|
请注意,这个例子其实是一个单独的句子,报道Lucian Gregory先生的演讲。然而,引用的演讲包含几个句子,这些已经被分割成几个单独的字符串。这对于大多数应用程序是合理的行为。
断句是困难的,因为句号会被用来标记缩写而另一些句号同时标记缩写和句子结束,就像发生在缩写如U.S.A.上的那样。
断句的另一种方法见2节。
分词
对于一些书写系统,由于没有词的可视边界表示这一事实,文本分词变得更加困难。例如,在中文中,三个字符的字符串:爱国人(ai4 “love” [verb], guo3 “country”,ren2 “person”) 可以被分词为“爱国/人”,“country-loving person”,或者“爱/国人”,“love country-person”。
类似的问题在口语语言处理中也会出现,听者必须将连续的语音流分割成单个的词汇。当我们事先不认识这些词时,这个问题就演变成一个特别具有挑战性的版本。语言学习者会面对这个问题,例如小孩听父母说话。考虑下面的人为构造的例子,单词的边界已被去除:
| (1) |
|
我们的第一个挑战仅仅是表示这个问题:我们需要找到一种方法来分开文本内容与分词标志。我们可以给每个字符标注一个布尔值来指示这个字符后面是否有一个分词标志(这个想法将在7.“分块”中大量使用)。让我们假设说话人会给语言学习者一个说话时的停顿,这往往是对应一个延长的暂停。这里是一种表示方法,包括初始的分词和目标分词:
|
观察由0和1组成的分词表示字符串。它们比源文本短一个字符,因为长度为n文本可以在n-1个地方被分割。3.7中的segment()函数演示了我们可以从这个表示回到初始分词的文本。
| ||
| ||
例 3.7 (code_segment.py):图 3.7:从分词表示字符串重建文本分词;seg1和seg2表示假设的一些儿童讲话的初始和最终分词;segment()函数可以使用它们重现分词的文本。 |
现在分词的任务变成了一个搜索问题:找到将文本字符串正确分割成词汇的字位串。我们假定学习者接收词,并将它们存储在一个内部词典中。给定一个合适的词典,是能够由词典中的词的序列来重构源文本的。根据(Brent, 1995),我们可以定义一个目标函数,一个打分函数,我们将基于词典的大小和从词典中重构源文本所需的信息量尽力优化它的值。我们在3.8中说明了这些。
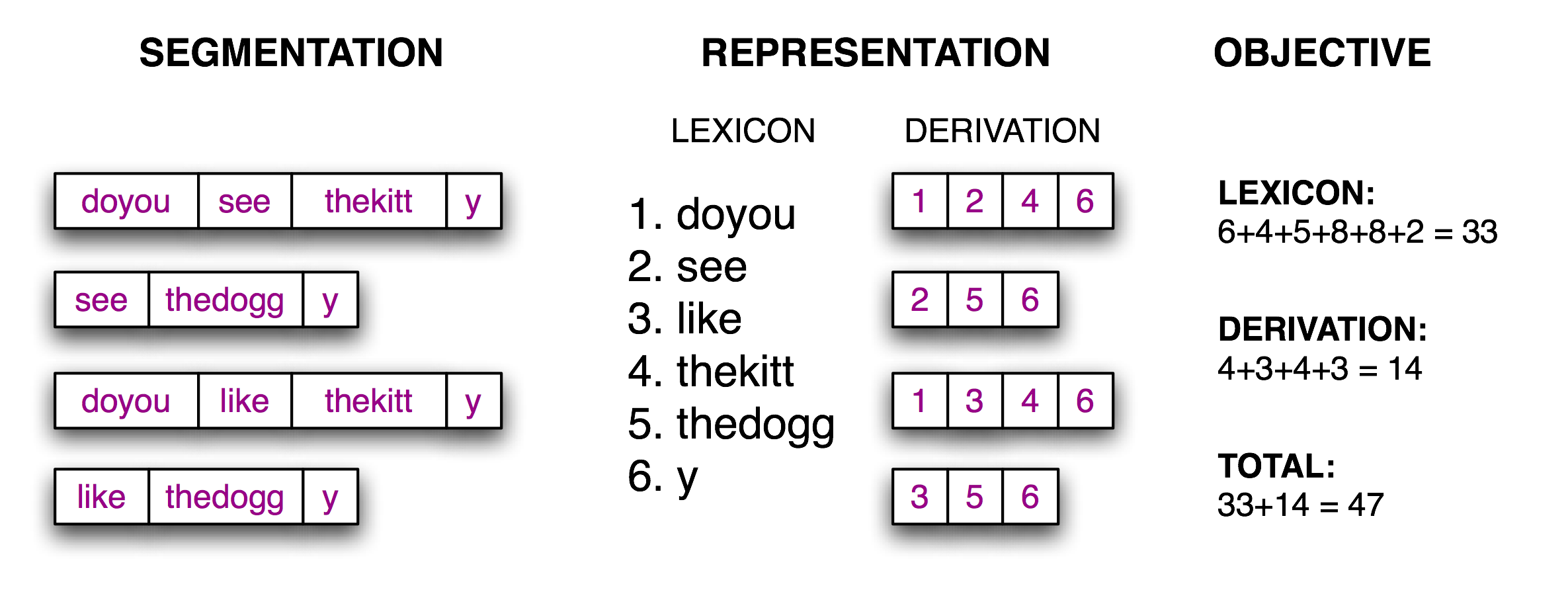
图 3.8:计算目标函数:给定一个假设的源文本的分词(左),推导出一个词典和推导表,它能让源文本重构,然后合计每个词项(包括边界标志)与推导表的字符数,作为分词质量的得分;得分值越小表明分词越好。
实现这个目标函数是很简单的,如例子3.9所示。
| ||
| ||
例 3.9 (code_evaluate.py):图 3.9:计算存储词典和重构源文本的成本 |
最后一步是寻找最小化目标函数值的0和1的模式,如3.10所示。请注意,最好的分词包括像thekitty这样的“词”,因为数据中没有足够的证据进一步分割这个词。
| ||
| ||
例 3.10 (code_anneal.py):图 3.10:使用模拟退火算法的非确定性搜索:一开始仅搜索短语分词;随机扰动0和1,它们与“温度”成比例;每次迭代温度都会降低,扰动边界会减少。由于此搜索算法是不确定的,你可能会看到略有不同的结果。 |
有了足够的数据,就可能以一个合理的准确度自动将文本分割成词汇。这种方法可用于为那些词的边界没有任何视觉表示的书写系统分词。
3.9 格式化:从列表到字符串
我们经常会写程序来汇报一个单独的数据项例如一个语料库中满足一些复杂的标准的特定的元素,或者一个单独的总数统计例如一个词计数器或一个标注器的性能。更多的时候,我们写程序来产生一个结构化的结果;例如:一个数字或语言形式的表格,或原始数据的格式变换。当要表示的结果是语言时,文字输出通常是最自然的选择。然而当结果是数值时,可能最好是图形输出。在本节中,你将会学到呈现程序输出的各种方式。
从列表到字符串
我们用于文本处理的最简单的一种结构化对象是词列表。当我们希望把这些输出到显示器或文件时,必须把这些词列表转换成字符串。在Python做这些,我们使用join()方法,并指定字符串作为使用的“胶水”。
|
所以' '.join(silly)的意思是:取出silly中的所有项目,将它们连接成一个大的字符串,使用' '作为项目之间的间隔符。即join()是一个你想要用来作为胶水的字符串的一个方法。(许多人感到join()的这种表示方法是违反直觉的。)join()方法只适用于一个字符串的列表——我们一直把它叫做一个文本——在Python中享有某些特权的一个复杂类型。
字符串与格式
我们已经看到了有两种方式显示一个对象的内容:
|
print命令让Python努力以人最可读的形式输出的一个对象的内容。第二种方法——叫做变量提示——向我们显示可用于重新创建该对象的字符串。重要的是要记住这些都仅仅是字符串,为了你用户的方便而显示的。它们并不会给我们实际对象的内部表示的任何线索。
还有许多其他有用的方法来将一个对象作为字符串显示。这可能是为了人阅读的方便,或是因为我们希望导出我们的数据到一个特定的能被外部程序使用的文件格式。
格式化输出通常包含变量和预先指定的字符串的一个组合,例如给定一个频率分布fdist,我们可以这样做:
|
输出包含变量和常量交替出现的表达式是难以阅读和维护的。一个更好的解决办法是使用字符串格式化表达式。
|
要了解这里发生了什么事情,让我们在字符串格式化表达式上面测试一下。(现在,这将是你探索新语法的常用方法。)
|
花括号'{}'标记一个替换字段的出现:它作为传递给str.format()方法的对象的字符串值的占位符。我们可以将'{}'嵌入到一个字符串的内部,然后以适当的参数调用format()来让字符串替换它们。包含替换字段的字符串叫做格式字符串。
让我们更深入的解开这段代码,以便更仔细的观察它的行为:
|
我们可以有任意个数目的占位符,但str.format方法必须以数目完全相同的参数来调用。
|
从左向右取用给format()的参数,任何多余的参数都会被简单地忽略。
|
格式字符串中的替换字段可以以一个数值开始,它表示format()的位置参数。'from {} to {}'这样的语句等同于'from {0} to {1}',但是我们使用数字来得到非默认的顺序:
|
我们还可以间接提供值给占位符。下面是使用for循环的一个例子:
|
对齐
到目前为止,我们的格式化字符串可以在页面(或屏幕)上输出任意的宽度。我们可以通过插入一个冒号':'跟随一个整数来添加空白以获得指定宽带的输出。所以{:6}表示我们想让字符串对齐到宽度6。数字默认表示右对齐,单我们可以在宽度指示符前面加上'<'对齐选项来让数字左对齐。
|
字符串默认是左对齐,但可以通过'>'对齐选项右对齐。
|
其它控制字符可以用于指定浮点数的符号和精度;例如{:.4f}表示浮点数的小数点后面应该显示4个数字。
|
字符串格式化很聪明,能够知道如果你包含一个'%'在你的格式化字符串中,那么你想表示这个值为百分数;不需要乘以100。
|
格式化字符串的一个重要用途是用于数据制表。回想一下,在1中,我们看到从条件频率分布中制表的数据。让我们自己来制表,行使对标题和列宽的完全控制,如3.11所示。注意语言处理工作与结果制表之间是明确分离的。
| ||
例 3.11 (code_modal_tabulate.py): 图 3.11:布朗语料库的不同部分的频率模型 |
回想一下3.6中的列表, 我们使用格式字符串'{:{width}}'并绑定一个值给 format()中的width参数。这我们使用变量知道字段的宽度。
|
我们可以使用width = max(len(w) for w in words)自动定制列的宽度,使其足够容纳所有的词。
将结果写入文件
我们已经看到了如何读取文本文件(3.1)。将输出写入文件往往也很有用。下面的代码打开可写文件output.txt,将程序的输出保存到文件。
|
当我们将非文本数据写入文件时,我们必须先将它转换为字符串。正如我们前面所看到的,可以使用格式化字符串来做这一转换。让我们把总词数写入我们的文件:
|
小心!
你应该避免包含空格字符的文件名例如output file.txt,和除了大小写外完全相同的文件名,例如Output.txt和output.TXT。
文本换行
当程序的输出是文档式的而不是像表格时,通常会有必要包装一下以便可以方便地显示它。考虑下面的输出,它的行尾溢出了,且使用了一个复杂的print语句:
|
我们可以在Python 的textwrap模块的帮助下采取换行。为了最大程度的清晰,我们将每一个步骤分在一行:
|
请注意,在more与其下面的数字之间有一个换行符。如果我们希望避免这种情况,可以重新定义格式化字符串,使它不包含空格(例如'%s_(%d),',然后不输出wrapped的值,我们可以输出wrapped.replace('_', ' ')。
3.10 小结
- 在本书中,我们将文本作为一个单词列表。“原始文本”是一个潜在的长字符串,其中包含文字和用于设置格式的空白字符,也是我们通常存储和可视化文本的方式。
- 在Python 中指定一个字符串使用单引号或双引号:'Monty Python',"Monty Python"。
- 字符串中的字符是使用索引来访问的,索引从零计数:'Monty Python'[0]给出的值是M。字符串的长度使用len()得到。
- 子字符串使用切片符号来访问: 'Monty Python'[1:5] 给出的值是onty。如果省略起始索引,子字符串从字符串的开始处开始;如果省略结尾索引,切片会一直到字符串的结尾处结束。
- 字符串可以被分割成列表:'Monty Python'.split()给出['Monty', 'Python']。列表可以连接成字符串:'/'.join(['Monty', 'Python'])给出'Monty/Python'。
- 我们可以使用text = open('input.txt').read()从一个文件input.txt读取文本。可以使用text = request.urlopen(url).read().decode('utf8')从一个url读取文本。我们可以使用for line in open(f)遍历一个文本文件的每一行。
- 我们可以通过打开一个用于写入的文件output_file = open('output.txt', 'w')来向文件写入文本,然后添加内容到文件中print("Monty Python", file=output_file)。
- 在网上找到的文本可能包含不需要的内容(如页眉、页脚和标记),在我们做任何语言处理之前需要去除它们。
- 分词是将文本分割成基本单位或词符,例如词和标点符号等。基于空格符的分词对于许多应用程序都是不够的,因为它会捆绑标点符号和词。NLTK提供了一个现成的分词器nltk.word_tokenize()。
- 词形归并是一个过程,将一个词的各种形式(如appeared,appears)映射到这个词标准的或引用的形式,也称为词位或词元(如appear)。
- 正则表达式是用来指定模式的一种强大而灵活的方法。一旦我们导入re模块,我们就可以使用re.findall()来找到一个字符串中匹配一个模式的所有子字符串。
- 如果一个正则表达式字符串包含一个反斜杠,你应该使用带有一个r前缀的原始字符串:r'regexp',来告诉Python不要预处理这个字符串。
- 当某些字符前使用了反斜杠时,例如\n, 处理时会有特殊的含义(换行符);然而,当反斜杠用于正则表达式通配符和操作符之前时,如\., \|, \$,这些字符失去它们特殊的含义并按字面含义匹配。
- 一个字符串格式化表达式template % arg_tuple包含一个格式字符串template,它由如%-6s和%0.2d这样的转换标识符符组成。
7 深入阅读
本章的附加材料发布在http://nltk.org/,包括网络上免费提供的资源的链接。记得咨询http://docs.python.org/上的的参考材料。(例如:此文档涵盖“通用换行符支持”,解释了各种操作系统如何规定不同的换行符。)
更多的使用NLTK 处理词汇的例子请参阅http://nltk.org/howto上的分词、词干提取以及语料库HOWTO 文档。(Jurafsky & Martin, 2008)的第2、3 章包含正则表达式和形态学的更高级的材料。Python文本处理更广泛的讨论请参阅(Mertz, 2003)。规范非标准词的信息请参阅(Sproat et al, 2001)
关于正则表达式的参考材料很多,无论是理论的还是实践的。在Python中使用正则表达式的一个入门教程,请参阅Kuchling的Regular Expression HOWTO,http://www.amk.ca/python/howto/regex/。关于使用正则表达式的全面而详细的手册,请参阅(Friedl, 2002),其中涵盖包括Python在内大多数主要编程语言的语法。其他材料还包括(Jurafsky & Martin, 2008)的第2.1 节,(Mertz, 2003)的第3章。
网上有许多关于Unicode的资源。以下是与处理Unicode的Python的工具有关的有益的讨论:
- Ned Batchelder, Pragmatic Unicode, http://nedbatchelder.com/text/unipain.html
- Unicode HOWTO, Python Documentation, http://docs.python.org/3/howto/unicode.html
- David Beazley, Mastering Python 3 I/O, http://pyvideo.org/video/289/pycon-2010--mastering-python-3-i-o
- Joel Spolsky, The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!), http://www.joelonsoftware.com/articles/Unicode.html
SIGHAN,ACL中文语言处理特别兴趣小组http://sighan.org/,重点关注中文文本分词的问题。我们分割英文文本的方法依据(Brent, 1995);这项工作属于语言获取领域(Niyogi, 2006)。
搭配是多词表达式的一种特殊情况。一个多词表达式是一个小短语,仅从它的词汇不能预测它的意义和其他属性,例如part of speech (Baldwin & Kim, 2010)。
模拟退火是一种启发式算法,找寻在一个大型的离散的搜索空间上的一个函数的最佳值的最好近似,基于对金属冶炼中的退火的模拟。该技术在许多人工智能文本中都有描述。
(Hearst, 1992)描述了使用如x and other ys的搜索模式发现文本中下位词的方法。
3.12 练习
☼ 定义一个字符串s = 'colorless'。写一个Python 语句将其变为“colourless”,只使用切片和连接操作。
☼ 我们可以使用切片符号删除词汇形态上的结尾。例如,'dogs'[:-1]删除了dogs的最后一个字符,留下dog。使用切片符号删除下面这些词的词缀(我们插入了一个连字符指示词缀的边界,请在你的字符串中省略掉连字符): dish-es, run-ning, nation-ality, un-do, pre-heat。
☼ 我们看到如何通过索引超出一个字符串的末尾产生一个IndexError。构造一个向左走的太远走到字符串的前面的索引,这有可能吗?
☼ 我们可以为分片指定一个“步长”。下面的表达式间隔一个字符返回一个片内字符:monty[6:11:2]。也可以反向进行:monty[10:5:-2]。自己尝试一下,然后实验不同的步长。
☼ 如果你让解释器处理monty[::-1]会发生什么?解释为什么这是一个合理的结果。
☼ 说明以下的正则表达式匹配的字符串类。
- [a-zA-Z]+
- [A-Z][a-z]*
- p[aeiou]{,2}t
- \d+(\.\d+)?
- ([^aeiou][aeiou][^aeiou])*
- \w+|[^\w\s]+
使用nltk.re_show()测试你的答案。
☼ 写正则表达式匹配下面字符串类:
- 一个单独的限定符(假设只有a, an和the为限定符)。
- 整数加法和乘法的算术表达式,如2*3+8。
☼ 写一个工具函数以URL为参数,返回删除所有的HTML标记的URL 的内容。使用from urllib import request和request.urlopen('http://nltk.org/').read().decode('utf8')来访问URL的内容。
☼ 将一些文字保存到文件corpus.txt。定义一个函数load(f)以要读取的文件名为其唯一参数,返回包含文件中文本的字符串。
- 使用nltk.regexp_tokenize()创建一个分词器分割这个文本中的各种标点符号。使用一个多行的正则表达式,使用verbose 标志(?x)带有行内注释。
- 使用nltk.regexp_tokenize()创建一个分词器分割以下几种表达式:货币金额;日期;个人和组织的名称。
☼ 将下面的循环改写为列表推导:
>>> sent = ['The', 'dog', 'gave', 'John', 'the', 'newspaper'] >>> result = [] >>> for word in sent: ... word_len = (word, len(word)) ... result.append(word_len) >>> result [('The', 3), ('dog', 3), ('gave', 4), ('John', 4), ('the', 3), ('newspaper', 9)]
☼ 定义一个字符串raw包含你自己选择的句子。现在,以空格以外的其它字符例如's'分割raw。
☼ 写一个for循环输出一个字符串的字符,每行一个。
☼ 在字符串上调用不带参数的split与以' '作为参数的区别是什么,即sent.split()与sent.split(' ')相比?当被分割的字符串包含制表符、连续的空格或一个制表符与空格的序列会发生什么?(在IDLE 中你将需要使用'\t'来输入制表符。)
☼ 创建一个变量words,包含一个词列表。实验words.sort()和sorted(words)。它们有什么区别?
☼ 通过在Python提示符输入以下表达式,探索字符串和整数的区别:"3" * 7和3 * 7。尝试使用int("3")和str(3)进行字符串和整数之间的转换。
☼ 使用文本编辑器创建一个文件prog.py,包含单独的一行monty = 'Monty Python'。接下来,打开一个新的Python会话,并在提示符下输入表达式monty。你会从解释器得到一个错误。现在,请尝试以下代码(注意你要丢弃文件名中的.py):
>>> from prog import monty >>> monty
这一次,Python应该返回一个值。你也可以尝试import prog,在这种情况下,Python应该能够处理提示符处的表达式prog.monty。
☼ 格式化字符串%6s与%-6s用来显示长度大于6 个字符的字符串时,会发生什么?
◑ 阅读语料库中的一些文字,为它们分词,输出其中出现的所有wh-类型词的列表。(英语中的wh-类型词被用在疑问句,关系从句和感叹句:who, which, what等。)按顺序输出它们。在这个列表中有因为有大小写或标点符号的存在而重复的词吗?
◑ 创建一个文件,包含词汇和(任意指定)频率,其中每行包含一个词,一个空格和一个正整数,如fuzzy 53。使用open(filename).readlines()将文件读入一个Python列表。接下来,使用split()将每一行分成两个字段,并使用int()将其中的数字转换为一个整数。结果应该是一个列表形式:[['fuzzy', 53], ...]。
◑ 编写代码来访问喜爱的网页,并从中提取一些文字。例如,访问一个天气网站,提取你所在的城市今天的最高温度预报。
◑ 写一个函数unknown(),以一个URL为参数,返回一个那个网页出现的未知词列表。为了做到这一点,请提取所有由小写字母组成的子字符串(使用re.findall()),并去除所有在Words语料库(nltk.corpus.words)中出现的项目。尝试手动分类这些词,并讨论你的发现。
◑ 使用上面建议的正则表达式处理网址 http://news.bbc.co.uk/,检查处理结果。你会看到那里仍然有相当数量的非文本数据,特别是JavaScript 命令。你可能还会发现句子分割没有被妥善保留。定义更深入的正则表达式,改善此网页文本的提取。
◑ 你能写一个正则表达式以这样的方式来分词吗,将词don't分为do和n't?解释为什么这个正则表达式无法正常工作:«n't|\w+»。
◑ 尝试编写代码将文本转换成hAck3r,使用正则表达式和替换,其中e → 3, i → 1, o → 0, l → |, s → 5, .→ 5w33t!, ate → 8。在转换之前将文本规范化为小写。自己添加更多的替换。现在尝试将s映射到两个不同的值:词开头的s映射为$,词内部的s映射为5。
◑ Pig Latin是英语文本的一个简单的变换。文本中每个词的按如下方式变换:将出现在词首的所有辅音(或辅音群)移到词尾,然后添加ay,例如string → ingstray, idle → idleay。http://en.wikipedia.org/wiki/Pig_Latin
- 写一个函数转换一个词为Pig Latin。
- 写代码转换文本而不是单个的词。
- 进一步扩展它,保留大写字母,将qu保持在一起(例如这样quiet会变成ietquay),并检测y是作为一个辅音(如yellow)还是一个元音(如style)。
◑ 下载一种包含元音和谐的语言(如匈牙利语)的一些文本,提取词汇的元音序列,并创建一个元音二元语法表。
◑ Python 的random模块包括函数choice(),它从一个序列中随机选择一个项目,例如choice("aehh ")会产生四种可能的字符中的一个,字母h的几率是其它字母的两倍。写一个表达式产生器,从字符串"aehh "产生500 个随机选择的字母的序列,并将这个表达式写入函数''.join()调用中,将它们连接成一个长字符串。你得到的结果应该看起来像失去控制的喷嚏或狂笑:he haha ee heheeh eha。使用split()和join()再次规范化这个字符串中的空格。
◑ 考虑下面的摘自MedLine 语料库的句子中的数字表达式:The corresponding free cortisol fractions in these sera were 4.53 +/- 0.15% and 8.16 +/- 0.23%, respectively.我们应该说数字表达式4.53 +/- 0.15%是三个词吗?或者我们应该说它是一个单独的复合词?或者我们应该说它实际上是九个词,因为它读作“four point five three,plus or minus fifteen percent”?或者我们应该说这不是一个“真正的”词,因为它不会出现在任何词典中?讨论这些不同的可能性。你能想出产生这些答案中至少两个以上可能性的应用领域吗?
◑ 可读性测量用于为一个文本的阅读难度打分,给语言学习者挑选适当难度的文本。在一个给定的文本中,让我们定义μw为每个词的平均字母数,μs为每个句子的平均词数。文本自动可读性指数(ARI)被定义为: 4.71 μw + 0.5 μs - 21.43。计算布朗语料库各部分的ARI 得分,包括 f(lore)和j(learned)部分。利用nltk.corpus.brown.words()产生一个词汇序列,nltk.corpus.brown.sents()产生一个句子的序列的事实。
◑ 使用Porter词干提取器规范化一些已标注的文本,对每个词调用提取词干器。用Lancaster词干提取器做同样的事情,看看你是否能观察到一些差别。
◑ 定义变量saying包含列表['After', 'all', 'is', 'said', 'and', 'done', ',', 'more', 'is', 'said', 'than', 'done', '.']。使用for循环处理这个列表,并将结果存储在一个新的链表lengths 中。提示:使用lengths = [],从分配一个空列表给lengths开始。然后每次循环中用append()添加另一个长度值到列表中。现在使用列表推导做同样的事情。
◑ 定义一个变量silly包含字符串:'newly formed bland ideas are inexpressible in an infuriating way'。(这碰巧是合法的解释,讲英语西班牙语双语者可以适用于乔姆斯基著名的无意义短语,colorless green ideas sleep furiously,来自维基百科)。编写代码执行以下任务:
- 分割silly为一个字符串列表,每一个词一个字符串,使用Python的split()操作,并保存到叫做bland的变量中。
- 提取silly中每个词的第二个字母,将它们连接成一个字符串,得到'eoldrnnnna''。
- 使用join()将bland中的词组合回一个单独的字符串。确保结果字符串中的词以空格隔开。
- 按字母顺序输出silly中的词,每行一个。
◑ index()函数可用于查找序列中的项目。例如,'inexpressible'.index('e')告诉我们字母e的第一个位置的索引值。
- 当你查找一个子字符串会发生什么,如'inexpressible'.index('re')?
- 定义一个变量words,包含一个词列表。现在使用words.index()来查找一个单独的词的位置。
- 定义上一个练习中的变量silly。使用index()函数结合列表切片,建立一个包括silly中in之前(但不包括)的所有的词的列表phrase。
◑ 编写代码,将国家的形容词转换为它们对应的名词形式,如将Canadian和Australian转换为Canada和Australia(见http://en.wikipedia.org/wiki/List_of_adjectival_forms_of_place_names)。
◑ 阅读LanguageLog中关于短语的as best as p can和as best p can形式的帖子,其中p是一个代名词。在一个语料库和3.5中描述的搜索已标注的文本的findall()方法的帮助下,调查这一现象。http://itre.cis.upenn.edu/~myl/languagelog/archives/002733.html
◑ 研究《创世记》的lolcat版本,使用nltk.corpus.genesis.words('lolcat.txt')可以访问,和http://www.lolcatbible.com/index.php?title=How_to_speak_lolcat上将文本转换为lolspeak的规则。定义正则表达式将英文词转换成相应的lolspeak 词。
◑ 使用help(re.sub)和参照本章的深入阅读,阅读有关re.sub()函数来使用正则表达式进行字符串替换。使用re.sub编写代码从一个HTML文件中删除HTML标记,规范化空格。
★ 分词的一个有趣的挑战是已经被分割的跨行的词。例如如果long-term被分割,我们就得到字符串long-\nterm。
- 写一个正则表达式,识别连字符连结的跨行处的词汇。这个表达式将需要包含\n字符。
- 使用re.sub()从这些词中删除\n字符。
- 你如何确定一旦换行符被删除后不应该保留连字符的词汇,如'encyclo-\npedia'?
★ 阅读维基百科Soundex条目。用Python 实现这个算法。
★ 获取两个或多个文体的原始文本,计算它们各自的在前面关于阅读难度的练习中描述的阅读难度得分。例如,比较ABC农村新闻和ABC科学新闻(nltk.corpus.abc)。使用Punkt处理句子分割。
★ 将下面的嵌套循环重写为嵌套列表推导:
>>> words = ['attribution', 'confabulation', 'elocution', ... 'sequoia', 'tenacious', 'unidirectional'] >>> vsequences = set() >>> for word in words: ... vowels = [] ... for char in word: ... if char in 'aeiou': ... vowels.append(char) ... vsequences.add(''.join(vowels)) >>> sorted(vsequences) ['aiuio', 'eaiou', 'eouio', 'euoia', 'oauaio', 'uiieioa']
★ 使用WordNet为一个文本集合创建语义索引。扩展例3.6中的一致性搜索程序,使用它的第一个同义词集偏移索引每个词,例如wn.synsets('dog')[0].offsetoffset(或者使用上位词层次中的一些祖先的偏移,这是可选的)。
★ 在多语言语料库如世界人权宣言语料库(nltk.corpus.udhr),和NLTK 的频率分布和关系排序的功能(nltk.FreqDist, nltk.spearman_correlation)的帮助下,开发一个系统,猜测未知文本。为简单起见,使用一个单一的字符编码和少几种语言。
★ 写一个程序处理文本,发现一个词以一种新的意义被使用的情况。对于每一个词计算这个词所有同义词集与这个词的上下文的所有同义词集之间的WordNet相似性。(请注意,这是一个粗略的办法;要做的很好是困难的,开放性研究问题。)
★ 阅读关于规范化非标准词的文章(Sproat et al, 2001),实现一个类似的文字规范系统。
关于本文档...
针对NLTK 3.0 作出更新。本章来自于Natural Language Processing with Python,Steven Bird, Ewan Klein 和Edward Loper,Copyright © 2014 作者所有。本章依据Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License [http://creativecommons.org/licenses/by-nc-nd/3.0/us/] 条款,与自然语言工具包 [http://nltk.org/] 3.0 版一起发行。
本文档构建于星期三 2015 年 7 月 1 日 12:30:05 AEST