9. 构建基于特征的语法
自然语言具有范围广泛的语法结构,用8.中所描述的简单的方法很难处理的如此广泛的语法结构。为了获得更大的灵活性,我们改变我们对待语法类别如S、NP和V的方式。我们将这些原子标签分解为类似字典的结构,其特征可以为一个范围的值。
本章的目的是要回答下列问题:
- 我们怎样用特征扩展上下文无关语法框架,以获得更细粒度的对语法类别和产生式的控制?
- 特征结构的主要形式化属性是什么,我们如何使用它们来计算?
- 我们现在用基于特征的语法能捕捉到什么语言模式和语法结构?
一路上,我们将介绍更多的英语句法主题,包括约定、子类别和无限制依赖成分等现象。
1 语法特征
在chap-data-intensive中,我们描述了如何建立基于检测文本特征的分类器。那些特征可能非常简单,如提取一个单词的最后一个字母,或者更复杂一点儿,如分类器自己预测的词性标签。在本章中,我们将探讨特征在建立基于规则的语法中的作用。对比特征提取,记录已经自动检测到的特征,我们现在要声明词和短语的特征。我们以一个很简单的例子开始,使用字典存储特征和它们的值。
|
对象kim和chase有几个共同的特征,CAT(语法类别)和ORTH(正字法,即拼写)。此外,每一个还有更面向语义的特征:kim['REF']意在给出kim的指示物,而chase['REL']给出chase表示的关系。在基于规则的语法上下文中,这样的特征和特征值对被称为特征结构,我们将很快看到它们的替代符号。
特征结构包含各种有关语法实体的信息。这些信息不需要详尽无遗,我们可能要进一步增加属性。例如,对于一个动词,根据动词的参数知道它扮演的“语义角色”往往很有用。对于chase,主语扮演“施事”的角色,而宾语扮演“受事”角色。让我们添加这些信息,使用'sbj'和'obj'作为占位符,它会被填充,当动词和它的语法参数结合时:
|
如果我们现在处理句子Kim chased Lee,我们要“绑定”动词的施事角色和主语,受事角色和宾语。我们可以通过链接到相关的NP的REF特征做到这个。在下面的例子中,我们做一个简单的假设:在动词直接左侧和右侧的NP分别是主语和宾语。我们还在例子结尾为Lee添加了一个特征结构。
|
同样的方法可以适用不同的动词,例如surprise,虽然在这种情况下,主语将扮演“源事”(SRC)的角色,宾语扮演“体验者”(EXP)的角色:
|
特征结构是非常强大的,但我们操纵它们的方式是极其ad hoc。我们本章接下来的任务是,显示上下文无关语法和分析如何能扩展到合适的特征结构,使我们可以一种更通用的和有原则的方式建立像这样的分析。我们将通过查看句法协议的现象作为开始;我们将展示如何使用特征典雅的表示协议约束,并在一个简单的语法中说明它们的用法。
由于特征结构是表示任何形式的信息的通用的数据结构,我们将从更形式化的视点简要地看着它们,并演示NLTK提供的特征结构的支持。在本章的最后一部分,我们将表明,特征的额外表现力开辟了一个用于描述语言结构的复杂性的广泛的可能性。
1.1 句法协议
下面的例子展示词序列对,其中第一个是符合语法的而第二个不是。(我们在词序列的开头用星号表示它是不符合语法的。)
| (1) |
|
| (2) |
|
在英语中,名词通常被标记为单数或复数。范例中的形式也各不相同:this(单数),these(复数)。例(1b)和(2b)显示在名词短语中使用指示词和名词是有限制的:要么两个都是单数要么都是复数。主语和谓词间也存在类似的约束:
| (3) |
|
| (4) |
|
这里我们可以看到,动词的形态属性与主语名词短语的句法属性一起变化。这种一起变化被称为协议。如果我们进一步看英语动词协议,我们将看到动词的现在时态通常有两种屈折形式:一为第三人称单数,另一个为人称和数量的所有其他组合,如1.1。
表 1.1:
英语规则动词的协议范式
| 单数 | 复数 | |
| 第一人称 | I run | we run |
| 第二人称 | you run | you run |
| 第三人称 | he/she/it runs | they run |
我们可以让形态学特性的作用更加明确一点儿,如ex-runs和ex-run所示。这些例子表明动词与它的主语在人称和数量上保持一致。(我们用3 作为第三人称的缩写,SG 表示单数,PL 表示复数。)
让我们看看当我们在一个上下文无关语法中编码这些协议约束会发生什么。我们将以(5)中简单的CFG开始。
| (5) | S -> NP VP NP -> Det N VP -> V Det -> 'this' N -> 'dog' V -> 'runs' |
语法(5)使我们能够产生句子this dog runs;然而,我们真正想要做的是也能产生these dogs run,而同时阻止不必要的序列,如*this dogs run和*these dog runs。最简单的方法是为语法添加新的非终结符和产生式:
| (6) | S -> NP_SG VP_SG S -> NP_PL VP_PL NP_SG -> Det_SG N_SG NP_PL -> Det_PL N_PL VP_SG -> V_SG VP_PL -> V_PL Det_SG -> 'this' Det_PL -> 'these' N_SG -> 'dog' N_PL -> 'dogs' V_SG -> 'runs' V_PL -> 'run' |
在唯一的扩展S的产生式的地方,我们现在有两个产生式,一个覆盖单数主语NP和VP的句子,另一个覆盖复数主语NP和VP的句子。事实上,(5)中的每个产生式在(6)中都有两个与之对应。在小规模的语法中这不是什么真的问题,虽然它在审美上不那么吸引人。然而,在一个更大的涵盖了一定量的英语成分子集的语法中,这样将语法规模增加一倍的前景是非常缺乏吸引力。让我们假设现在我们用同样的方法处理第一,第二和第三人称,还有单数和复数。这将导致原有的语法被乘以因子6,这是我们一定要避免的。我们可以做得比这更好吗?在下一节,我们将显示遵从数量和人称协议不必以“爆炸式”的产生式数目为代价。
1.2 使用属性和约束
我们说过非正式的语言类别具有属性;例如,名词具有复数的属性。让我们把这个弄的更明确:
| (7) | N[NUM=pl] |
在(7)中,我们介绍了一些新的符号,它的意思是类别N有一个(语法)特征叫做NUM(“number 数字”的简写),此特征的值是pl(“plural 复数”的简写)。我们可以添加类似的注解给其他类别,在词汇条目中使用它们:
| (8) | Det[NUM=sg] -> 'this' Det[NUM=pl] -> 'these' N[NUM=sg] -> 'dog' N[NUM=pl] -> 'dogs' V[NUM=sg] -> 'runs' V[NUM=pl] -> 'run' |
这确实有帮助吗?迄今为止,它看起来就像(6)中指定内容的一个稍微更详细的替代。当我们允许使用特征值变量,并利用这些表示限制时,事情变得更有趣:
| (9) | S -> NP[NUM=?n] VP[NUM=?n] NP[NUM=?n] -> Det[NUM=?n] N[NUM=?n] VP[NUM=?n] -> V[NUM=?n] |
我们使用?n作为NUM值上的变量;它可以在给定的产生式中被实例化为sg或pl。我们可以读取第一条产生式就像再说不管NP为特征NUM取什么值,VP必须取同样的值。
为了介绍这些特征限制如何工作,思考如何去建立一个树是有益的。词汇产生式将承认下面的树(树的深度为1):
| (10) |
|

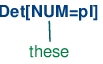
| (11) |
|


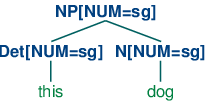
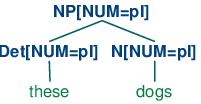
现在S -> NP[NUM=?n] VP[NUM=?n]表示无论N和Det的NUM的值是什么,它们都是相同的。因此,NP[NUM=?n] -> Det[NUM=?n] N[NUM=?n]允许(10a)和(11a)组合成一个NP,如(12a)所示,它也将允许(10b)和(11b)组合,如(12b)中所示。相比之下,(13a)和(13b)被禁止因为它们子树的根的NUM值不同;这种值的不相容可以用顶端节点的值FAIL非正式的表示。
| (12) |
|
| (13) |
|
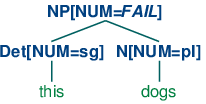

产生式VP[NUM=?n] -> V[NUM=?n]表示核心动词的NUM必须与它的VP父母的NUM值相同。结合扩展S的产生式,我们得出结论,如果主语核心名词的NUM值是pl,那么VP核心动词的NUM值也是。
| (14) |  |
语法(8)演示了如this和these这样的限定词的词汇产生式分别需要一个单数或复数的核心名词。然而,英语中其他限定词对与它们结合的名词的语法上的数量并不挑剔。一个描述这个的方法将是添加两个词汇条目到语法中,单数和复数版本的限定词如the一样一个。
Det[NUM=sg] -> 'the' | 'some' | 'any' Det[NUM=pl] -> 'the' | 'some' | 'any'
然而,一个更优雅的解决办法是保留NUM的值为未指定,让它匹配与它结合的任何名词的数量。为NUM分配一个变化的值是解决的方法之一:
Det[NUM=?n] -> 'the' | 'some' | 'any'
但事实上我们可以更简单些,在这样的产生式中不给NUM任何指定。我们只需要在这个限制制约同一个产生式的其他地方的值时才明确地输入一个变量的值。
1.1中的语法演示到目前为止我们已经在本章中介绍过的大多数想法,再加上几个新的想法。
| ||
例 1.1 (code_feat0cfg.py):图 1.1:基于特征的语法的例子 |
注意一个句法类别可以有多个特征,例如V[TENSE=pres, NUM=pl]。在一般情况下,我们喜欢多少特征就可以添加多少。
关于1.1的最后的细节是语句%start S。这个“指令”告诉分析器以S作为文法的开始符号。
一般情况下,即使我们正在尝试开发很小的语法,把产生式放在一个文件中我们可以编辑、测试和修改是很方便的。我们将1.1以NLTK 的数据格式保存为文件'feat0.fcfg'。你可以使用nltk.data.load()制作你自己的副本进行进一步的实验。
1.2 说明了基于特征的语法图表解析的操作。为输入分词之后,我们导入load_parser函数![[1]](./static/callout1.gif) ,以语法文件名为输入,返回一个图表分析器cp
,以语法文件名为输入,返回一个图表分析器cp ![[2]](./static/callout2.gif) 。调用分析器的parse()方法将迭代生成的分析树;如果文法无法分析输入,trees将为空,并将会包含一个或多个分析树,取决于输入是否有句法歧义。
。调用分析器的parse()方法将迭代生成的分析树;如果文法无法分析输入,trees将为空,并将会包含一个或多个分析树,取决于输入是否有句法歧义。
| ||
例 1.2 (code_featurecharttrace.py):图 1.2:跟踪基于特征的图表解析器 |
分析过程中的细节对于当前的目标并不重要。然而,有一个实施上的问题与我们前面的讨论语法的大小有关。分析包含特征限制的产生式的一种可行的方法是编译出问题中特征的所有可接受的值,是我们最终得到一个大的完全指定的(6)中那样的CFG。相比之下,前面例子中显示的分析器过程直接与给定语法的未指定的产生式一起运作。特征值从词汇条目“向上流动”,变量值于是通过如{?n: 'sg', ?t: 'pres'}这样的绑定(即字典)与那些值关联起来。当分析器装配有关它正在建立的树的节点的信息时,这些变量绑定被用来实例化这些节点中的值;从而通过查找绑定中?n和?t的值,未指定的VP[NUM=?n, TENSE=?t] -> TV[NUM=?n, TENSE=?t] NP[]实例化为VP[NUM='sg', TENSE='pres'] -> TV[NUM='sg', TENSE='pres'] NP[]。
最后,我们可以检查生成的分析树(在这种情况下,只有一个)。
|
1.3 术语
到目前为止,我们只看到像sg和pl这样的特征值。这些简单的值通常被称为原子——也就是,它们不能被分解成更小的部分。原子值的一种特殊情况是布尔值,也就是说,值仅仅指定一个属性是真还是假。例如,我们可能要用布尔特征AUX区分助动词,如can,may,will和do。例如,产生式V[TENSE=pres, AUX=+] -> 'can'意味着can接受TENSE的值为pres,并且AUX的值为+或true。有一个广泛采用的约定用缩写表示布尔特征f;不用AUX=+或AUX=-,我们分别用+AUX和-AUX。这些都是缩写,然而,分析器就像+和-是其他原子值一样解释它们。(15)显示了一些有代表性的产生式:
| (15) | V[TENSE=pres, +AUX] -> 'can' V[TENSE=pres, +AUX] -> 'may' V[TENSE=pres, -AUX] -> 'walks' V[TENSE=pres, -AUX] -> 'likes' |
我们说过分配“特征注释”给句法类别。表示整个类别的更激进的做法——也就是,非终结符加注释——作为一个特征的绑定。例如,N[NUM=sg]包含词性信息,可以表示为POS=N。因此,这个类别的替代符号是[POS=N, NUM=sg]。
除了原子值特征,特征可能需要本身就是特征结构的值。例如:我们可以将协议特征组合在一起(例如:人称、数量和性别)作为一个类别的不同部分,表示为AGR的值。这种情况中,我们说AGR是一个复杂值。(16)描述这个结构,在格式上称为属性值矩阵(AVM)。
| (16) | [POS = N ] [ ] [AGR = [PER = 3 ]] [ [NUM = pl ]] [ [GND = fem ]] |
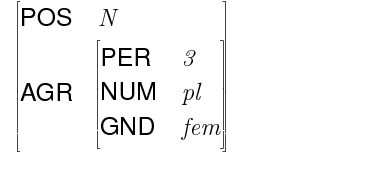
图 1.3︰ 呈现特征结构为一个属性值矩阵
在传递中,我们应该指出有显示AVM的替代方法;1.3显示了一个例子。虽然特征结构呈现的(16)中的风格不太悦目,我们将坚持用这种格式,因为它对应我们将会从NLTK得到的输出。
关于表示,我们也注意到特征结构,像字典,对特征的顺序没有指定特别的意义。所以(16)等同于︰
| (17) | [AGR = [NUM = pl ]] [ [PER = 3 ]] [ [GND = fem ]] [ ] [POS = N ] |
当我们有可能使用像AGR这样的特征时,我们可以重构像1.1这样的语法,使协议特征捆绑在一起。一个微小的语法演示了这个想法,如(18)所示。
| (18) | S -> NP[AGR=?n] VP[AGR=?n] NP[AGR=?n] -> PropN[AGR=?n] VP[TENSE=?t, AGR=?n] -> Cop[TENSE=?t, AGR=?n] Adj Cop[TENSE=pres, AGR=[NUM=sg, PER=3]] -> 'is' PropN[AGR=[NUM=sg, PER=3]] -> 'Kim' Adj -> 'happy' |
2 处理特征结构
在本节中,我们将展示如何在NLTK中构建和操作特征结构。我们还将讨论统一的基本操作,这使我们能够结合两个不同的特征结构中的信息。
NLTK中的特征结构使用构造函数FeatStruct()声明。原子特征值可以是字符串或整数。
|
一个特征结构实际上只是一种字典,所以我们可以平常的方式通过索引访问它的值。我们可以用我们熟悉的方式赋值给特征:
|
我们还可以为特征结构定义更复杂的值,如前面所讨论的。
|
指定特征结构的另一种方法是使用包含feature=value格式的特征-值对的方括号括起的字符串,其中值本身可能是特征结构:
|
特征结构本身并不依赖于语言对象;它们是表示知识的通用目的的结构。例如,我们可以将一个人的信息用特征结构编码:
|
在接下来的几页中,我们会使用这样的例子来探讨特征结构的标准操作。这将使我们暂时从自然语言处理转移,因为在我们回来谈论语法之前需要打下基础。坚持!
将特征结构作为图来查看往往是有用的;更具体的,作为有向无环图(DAG)。(19)等同于上面的AVM。
| (19) | 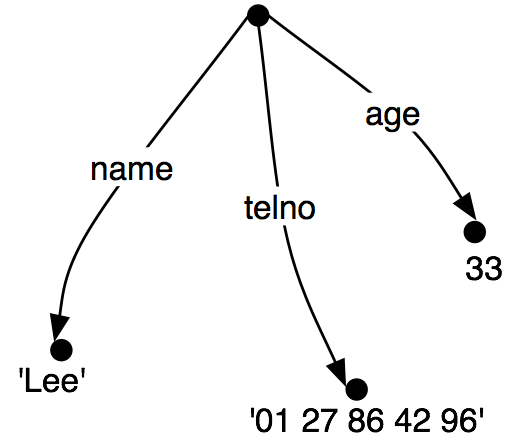 |
特征名称作为弧上的标签出现,特征值作为弧指向的节点的标签出现。
像以前一样,特征值可以是复杂的:
| (20) | 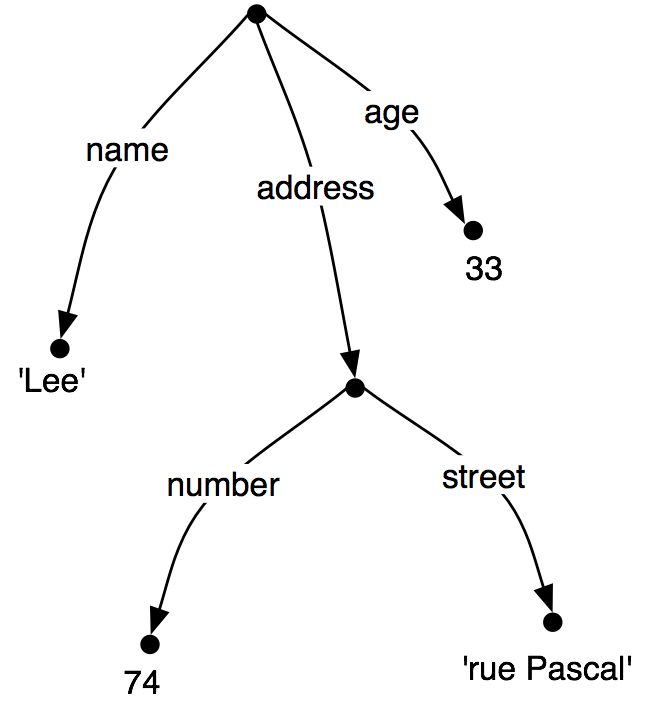 |
当我们看这种图时,很自然地想到通过图的路径。特征路径是一个可以从根节点跟踪的弧序列。我们将表示路径为元组。于是,('ADDRESS', 'STREET')是一个特征路径,它在(20)中的值是标签为'rue Pascal'的节点。
现在让我们思考一种情况,Lee 有一个配偶叫做Kim,Kim的地址与Lee 的相同。我们可能表示这个为(21)。
| (21) | 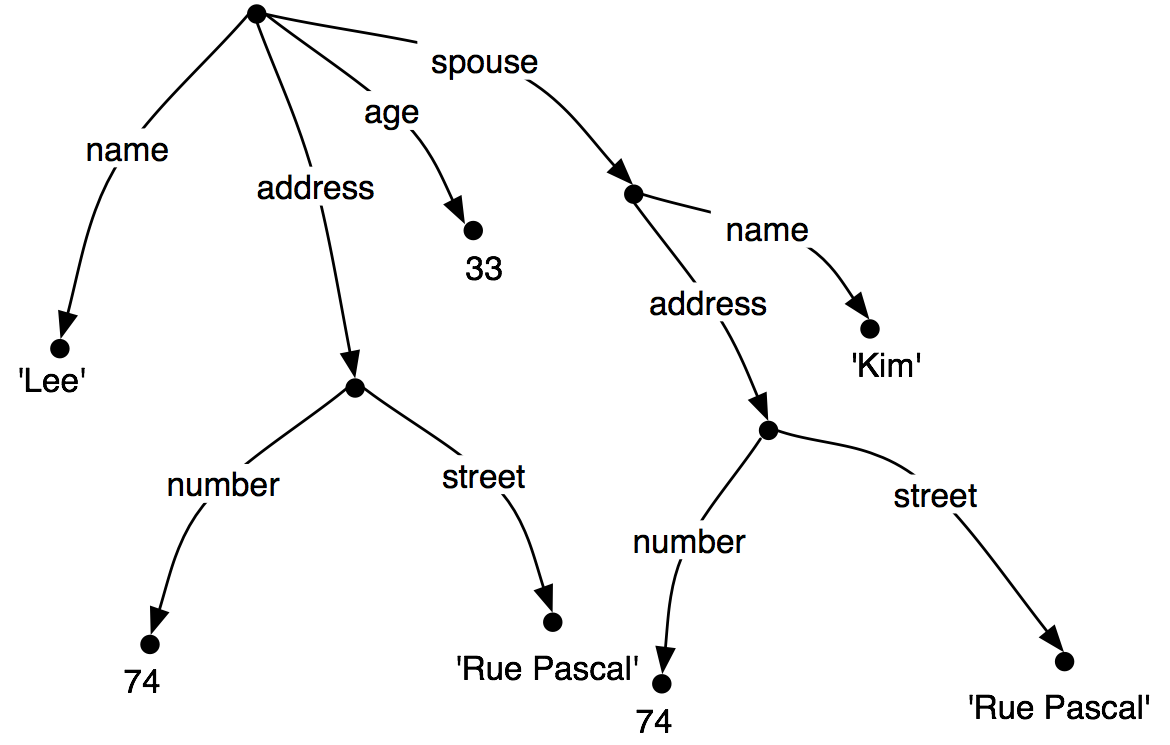 |
然而,不是重复特征结构中的地址信息,我们可以“共享”不同的弧之间的同一子图:
| (22) | 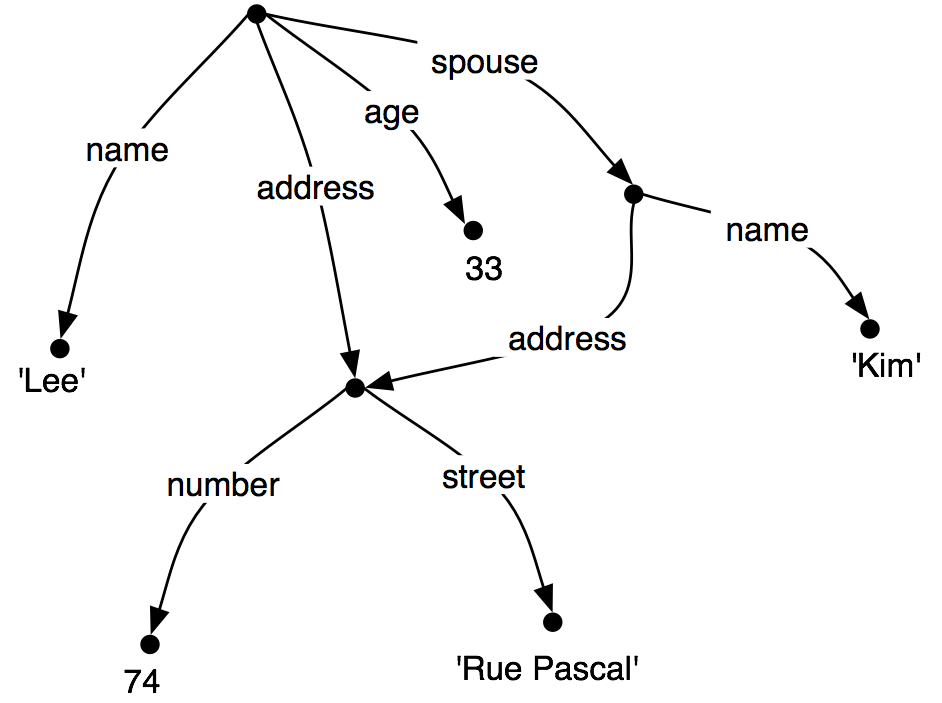 |
换句话说,(22)中路径('ADDRESS')的值与路径('SPOUSE', 'ADDRESS')的值相同。如(22)的DAG被称为包含结构共享或重入。当两条路径具有相同的值时,它们被称为是等价的。
为了在我们的矩阵式表示中表示重入,我们将在共享的特征结构第一次出现的地方加一个括号括起的数字前缀,例如(1)。以后任何对这个结构的引用将使用符号-->(1),如下所示。
|
括号内的整数有时也被称为标记或同指标志。整数的选择并不重要。可以有任意数目的标记在一个单独的特征结构中。
|
2.1 包含和统一
认为特征结构提供一些对象的部分信息是很正常的,在这个意义上,我们可以根据它们通用的程度给特征结构排序。例如,(23a)比(23b)具有更少特征,(23b)比(23c)具有更少特征。
| (23) |
|
这个顺序被称为包含;FS0包含FS1,如果包含在FS0中的信息也都包含在FS1中。我们使用符合⊑来表示包含。
当我们添加重入数的可能性时,我们需要格外地小心如何描述包含:如果FS0 ⊑ FS1,那么FS1 必须具有FS0的所有路径和重入数。所以,(20)包含(22),因为后者具有额外的重入数。显然,包含只提供了特征结构上的偏序,因为一些特征结构是不可比较的。例如,(24)既不包含也不被(23a)包含。
| (24) | [TELNO = 01 27 86 42 96] |
所以,我们已经看到了,一些特征结构比其他的更具体。我们如何去具体化一个给定的特征结构?例如,我们可能决定地址应包括的不只是一个门牌号码和街道名称,还应该包括城市。也就是说,我们可能要合并图(25b)与(25a)来去产生(25c)。
| (25) |
|
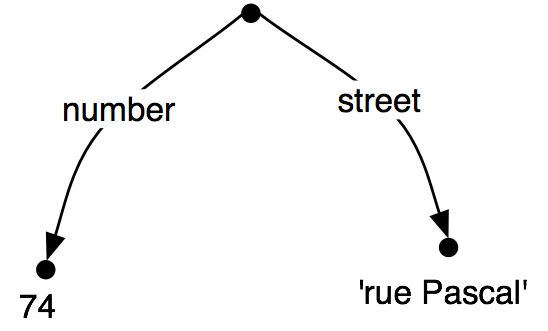
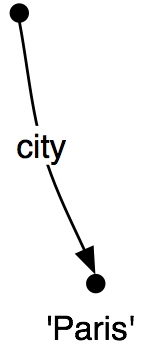
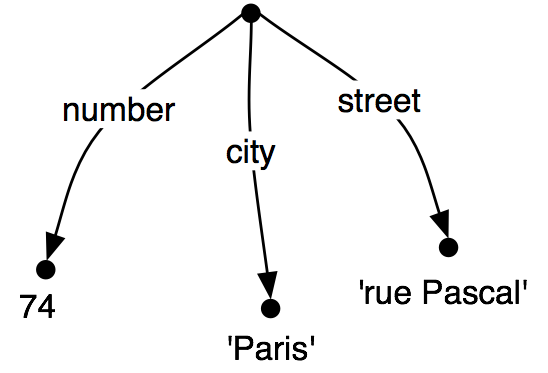
合并两个特征结构的信息被称为统一,由方法unify() 支持。
|
统一被正式定义为一个(部分)二元操作:FS0 ⊔ FS1。统一是对称的,所以FS0 ⊔ FS1 = FS1 ⊔ FS0。在Python中也是如此:
|
如果我们统一两个具有包含关系的特征结构,那么统一的结果是两个中更具体的那个:
| (26) | If FS0 ⊑ FS1, then FS0 ⊔ FS1 = FS1 |
FS0和FS1之间的统一将失败,如果这两个特征结构共享路径π,但在FS0中的π值与在FS1中的π值是不同的原子值。这通过设置统一的结果为None来实现。
|
现在,如果我们看一下统一如何与结构共享相互作用,事情就变得很有趣。首先,让我们在Python中定义(21):
|
我们为Kim的地址指定一个CITY作为参数会发生什么?请注意,fs1需要包括从特征结构的根到CITY的整个路径。
|
通过对比,如果fs1与fs2的结构共享版本统一,结果是非常不同的(如图(22)所示):
|
不是仅仅更新Kim的Lee的地址的“副本”,我们现在同时更新他们两个的地址。更一般的,如果统一包含指定一些路径π的值,那么统一同时更新等价于π的任何路径的值。
正如我们已经看到的,结构共享也可以使用变量表示,如?x。
|
3 扩展基于特征的语法
在本节中,我们回到基于特征的语法,探索各种语言问题,并展示将特征纳入语法的好处。
3.1 子类别
第8.中,我们增强了类别标签表示不同类别的动词,分别用标签IV和TV表示不及物动词和及物动词。这使我们能编写如下的产生式:
| (27) | VP -> IV VP -> TV NP |
虽然我们知道IV和TV是两种V,它们只是一个CFG中的原子非终结符,与任何其他符号对之间的区别是一样的。这个符号不会告诉我们任何有关一般动词的信息,例如我们不能说“V类的所有词汇都按时态标记”,因为walk是IV类的项目,不是V类的。所以,我们能替换如TV和IV类别标签为带着告诉我们这个动词是否与后面的NP对象结合或者它是否能不带补语等特征的V?
一个简单的方法,最初为语法框架开发的称为广义短语结构语法(GPSG),通过允许词汇类别支持子类别特征尝试解决这个问题,它告诉我们该项目所属的子类别。相比GPSG使用的整数值表示子类别,下面的例子采用更容易记忆的值,即intrans,trans和clause:
| (28) | VP[TENSE=?t, NUM=?n] -> V[SUBCAT=intrans, TENSE=?t, NUM=?n] VP[TENSE=?t, NUM=?n] -> V[SUBCAT=trans, TENSE=?t, NUM=?n] NP VP[TENSE=?t, NUM=?n] -> V[SUBCAT=clause, TENSE=?t, NUM=?n] SBar V[SUBCAT=intrans, TENSE=pres, NUM=sg] -> 'disappears' | 'walks' V[SUBCAT=trans, TENSE=pres, NUM=sg] -> 'sees' | 'likes' V[SUBCAT=clause, TENSE=pres, NUM=sg] -> 'says' | 'claims' V[SUBCAT=intrans, TENSE=pres, NUM=pl] -> 'disappear' | 'walk' V[SUBCAT=trans, TENSE=pres, NUM=pl] -> 'see' | 'like' V[SUBCAT=clause, TENSE=pres, NUM=pl] -> 'say' | 'claim' V[SUBCAT=intrans, TENSE=past, NUM=?n] -> 'disappeared' | 'walked' V[SUBCAT=trans, TENSE=past, NUM=?n] -> 'saw' | 'liked' V[SUBCAT=clause, TENSE=past, NUM=?n] -> 'said' | 'claimed' |
当我们看到一个词汇类别,如V[SUBCAT=trans],我们可以解释SUBCAT指向一个产生式,其中的V[SUBCAT=trans]作为一个VP产生式中的核心词引入。按照约定,SUBCAT值和引入核心词的产生式之间存在对应关系。对这种做法,SUBCAT只能出现在词汇类别中;它是没有意义的,例如要在VP上指定SUBCAT。与要求的一样,walk和like都属于类别V。然而walk将只出现在被具有特征SUBCAT=intrans在右侧的产生式扩展的VP中,而like相反,它需要一个SUBCAT=trans。
在上面的的动词的第三个类别中,我们指定了一个类SBar。这是一个从句标签,就像例子You claim that you like children中的claim的补语。我们需要两个进一步的产生式来分析这样的句子:
| (29) | SBar -> Comp S Comp -> 'that' |
产生的结构如下。
| (30) | 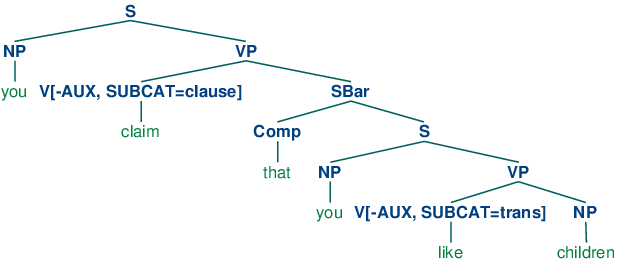 |
由于原本是用于称为语法类别的框架中的,子类别的一个替代方式被表示在基于特征的框架中,如PATR和核心驱动短语结构语法。不是用SUBCAT值作为索引产生式的方式,SUBCAT值直接为中心词的配价(它能结合的参数的列表)编码。例如,动词put带NP和PP补语(put the book on the table)可以表示为(31):
| (31) | V[SUBCAT=<NP, NP, PP>] |
这是说动词可以结合三个参数。列表最左边元素是主语NP,而其它所有的——这个例子中的后面跟着PP的NP——包括了补语子类别。当动词如put与适当的补语结合时,SUBCAT中指定的要求被免除,只需要一个主语NP。这个类别相当于传统上被认为的VP,可以表示如下。
| (32) | V[SUBCAT=<NP>] |
最后,一个句子成为一种不需要更多参数的动词类别,因此有一个值为空列表的SUBCAT。树(33)显示了在短语Kim put the book on the table中这些类别是如何组合的。
| (33) | 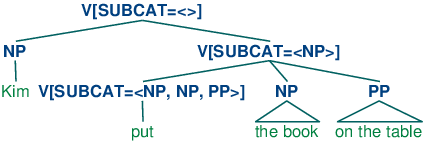 |
3.2 核心词回顾
我们注意到,在上一节中,通过从主类别标签分解出子类别信息,我们可以表达有关动词属性的更多概括。类似的另一个属性如下:V类的表达式是VP类的短语的核心。同样,N是NP的核心词,A(即形容词)是AP的核心词,P(即介词)是PP的核心词。并非所有的短语都有核心词——例如,一般认为连词短语(如the book and the bell)缺乏核心词——然而,我们希望我们的语法形式能表达它所持有的父母/核心子女关系。现在,V和VP只是原子符号,我们需要找到一种方法用特征将它们关联起来(就像我们以前关联IV和TV那样)。
X-bar句法通过抽象出短语级别的概念,解决了这个问题。它通常认为有三个这样的级别。如果N表示词汇级别,那么N'表示更高一层级别,对应较传统的级别Nom,N''表示短语级别,对应类别NP。(34a)演示了这种表示结构,而(34b)是更传统的对应。
| (34) |
|
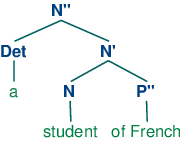
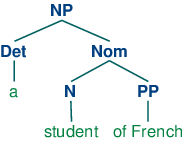
结构(34a)的核心词是N,而N'和N''被称为N的(短语的)投影。N''是最大的投影,N有时也被称为零投影。X-bar语法一个中心思想是所有成分都有结构的类似性。使用X作为N,V,A和P上的变量,我们说一个词汇核心X的直接补语子类别总是位于核心词的兄弟的位置,而修饰成分位于中间类别X'的兄弟的位置。因此,(35)中两个P''修饰成分的配置与(34a)中补语P''的形成对比。
| (35) | 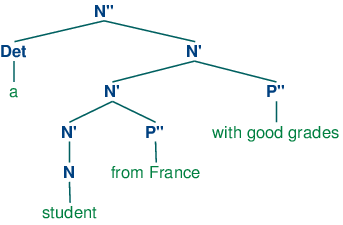 |
(36)中的产生式演示X-bar的级别用特征结构如何编码。(35)中嵌入结构通过扩展N[BAR=1]的递归规则的两个应用来实现。
| (36) | S -> N[BAR=2] V[BAR=2] N[BAR=2] -> Det N[BAR=1] N[BAR=1] -> N[BAR=1] P[BAR=2] N[BAR=1] -> N[BAR=0] P[BAR=2] N[BAR=1] -> N[BAR=0]XS |
3.3 助动词与倒装
倒装从句——其中的主语和动词顺序互换——出现在英语疑问句,也出现在“否定”副词之后:
| (37) |
|
| (38) |
|
然而,我们不能仅仅把任意动词放在主语前面:
| (39) |
|
| (40) |
|
可以放置在倒装的从句开头的动词术语叫做助动词的类别,如do,can和have也包括be,will和shall。捕捉这种结构的方法之一是使用以下产生式:
| (41) | S[+INV] -> V[+AUX] NP VP |
也就是说,标记有[+INV]的从句包含一个助动词,其后跟着一个VP。(在更详细的语法中,我们需要在VP的形式上加一些限制,取决于选择的助动词。)(42)演示了一个倒装从句的结构。
| (42) | 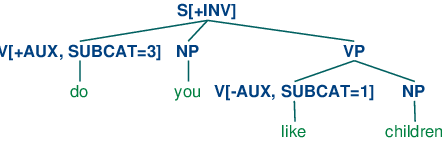 |
3.4 无限制依赖成分
考虑下面的对比:
| (43) |
|
| (44) |
|
动词like需要一个NP补语,而put需要一个跟随其后的NP和PP。(43)和(44)表明,这些补语是必须的:省略它们会导致不符合语法。然而,有些上下文中强制性的补语可以省略,如(45)和(46)所示。
| (45) |
|
| (46) |
|
也就是说,一个强制性补语可以被省略,如果句子中有是适当的填充,例如(45a)中的疑问词who,(45b)中的前置的主题this music,或(46)中的wh短语which card/slot。通常说类似(45) – (46)中的句子包含一个缺口,在那里强制性补语被省略了,这些缺口有时被用下划线标出:
| (47) |
|
所以,如果填充词许可,缺口就能出现。相反,填充词只会出现在句子希望有缺口的某个地方,如下面的例子所示:
| (48) |
|
| (49) |
|
填充词和缺口之间的相互共同出现有时被称为“依赖”。在理论语言学中相当重视的一个问题一直是一个填充词和它许可的缺口之间可以相互作用的原因;特别的,我们能简单地列出一个分开这两个的序列的有限集合吗?答案是否定的:填充词和缺口之间的距离没有上界。这一事实可以很容易地使用包含句子补语的成分来说明,如(50)所示。
| (50) |
|
因为我们可以无限加深句子补语的递归,在整个句子中缺口可以无限远的被填充。这一属性导致无限依赖成分的概念;也就是填充词-缺口依赖,在那里填充词和缺口之间的距离没有上界。
已经提出了各种各样的机制处理形式化语法中的无限依赖;在这里我们说明广义短语结构语法中使用的方法,其中包含斜线类别。一个斜线类别的形式是Y/XP;我们解释为类别Y的短语缺少一个类别XP的子成分。例如,S/NP是缺少一个NP的S。斜线类别的使用说明如(51)所示。
| (51) | 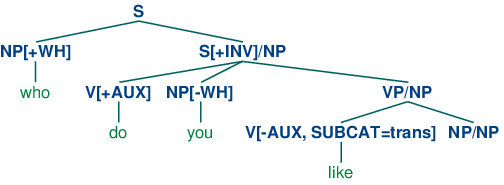 |
树的顶端部分引入了填充词who(作为NP[+wh]类表达式对待)和相应的包含成分S/NP的缺口一起。缺口信息于是被向着树的下方通过VP/NP类别“预填充”,直到到达类别NP/NP。这时,由于意识到缺口信息为空字符串直接受控于NP/NP,依赖被排除。
我们需要将斜线类别认为完全是一种新的对象吗?幸运的是,我们可以将它们纳入我们现有的基于特征的框架,通过将斜线作为一个特征,它右边的类别作为值;也就是说,S/NP可变为S[SLASH=NP]。在实践中,这也是分析器如何解释斜线类别的。
3.1中的语法演示了斜线类别的主要原则,而且还包括倒装从句的产生式。为了简化演示,我们省略了动词上的任何时态规范。
| ||
例 3.1 (code_slashcfg.py):图 3.1:具有倒装从句和长距离依赖的产生式的语法,使用斜线类别 |
3.1中的语法包含一个“缺口引进”产生式,即S[-INV] -> NP S/NP。为了正确的预填充斜线特征,我们需要为扩展S,VP和NP的产生式中箭头两侧的斜线添加变量值。例如,VP/?x -> V SBar/?x是VP -> V SBar的斜线版本,也就是说,可以为一个成分的父母VP指定斜线值,只要也为孩子SBar指定同样的值。最后,NP/NP ->允许NP上的斜线信息为空字符串。使用3.1中的语法,我们可以分析序列who do you claim that you like
|
这棵树的一个更易读的版本如(52)所示。
| (52) | 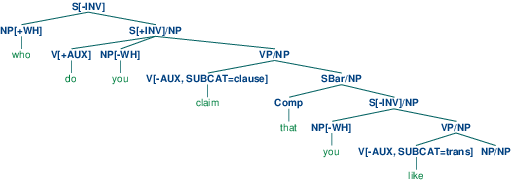 |
3.1中的语法也可以分析没有缺口的句子:
|
此外,它还允许没有wh 结构的倒装句:
|
3.5 德语中的格和性别
与英语相比,德语的协议具有相对丰富的形态。例如,在德语中定冠词根据格、性别和数量变化,如3.1所示。
表 3.1:
德语定冠词的形态范式
| 格 | 男性 | 女性 | 中性 | 复数 |
| 主格 | der | die | das | die |
| 所有格 | des | der | des | der |
| 与格 | dem | der | dem | den |
| 宾格 | den | die | das | die |
德语中的主语采用主格,大多数动词采用宾格支配它们的宾语。不过,也有例外,例如helfen支配与格:
| (53) |
3.2中的语法演示带格的协议(包括人称、数量和性别)的相互作用。
| ||
例 3.2 (code_germancfg.py):图 3.2:基于特征语法的例子 |
正如你可以看到的,特征objcase被用来指定动词支配它的对象的格。下一个例子演示了包含支配与格的动词的句子的分析树。
|
在开发语法时,排除不符合语法的词序列往往与分析符合语法的词序列一样具有挑战性。为了能知道在哪里和为什么序列分析失败,设置load_parser()方法的trace参数可能是至关重要的。思考下面的分析故障:
|
跟踪中的最后两个Scanner行显示den被识别为两个可能的类别:Det[AGR=[GND='masc', NUM='sg', PER=3], CASE='acc']和Det[AGR=[NUM='pl', PER=3], CASE='dat']。我们从3.2中的语法知道Katze的类别是N[AGR=[GND=fem, NUM=sg, PER=3]]。因而,产生式NP[CASE=?c, AGR=?a] -> Det[CASE=?c, AGR=?a] N[CASE=?c, AGR=?a]中没有变量?a的绑定,这将满足这些限制,因为Katze的AGR值将不与den的任何一个AGR值统一,也就是[GND='masc', NUM='sg', PER=3]或[NUM='pl', PER=3]。
4 小结
- 上下文无关语法的传统分类是原子符号。特征结构的一个重要的作用是捕捉精细的区分,否则将需要数量翻倍的原子类别。
- 通过使用特征值上的变量,我们可以表达语法产生式中的限制,允许不同的特征规格的实现可以相互依赖。
- 通常情况下,我们在词汇层面指定固定的特征值,限制短语中的特征值与它们的孩子中的对应值统一。
- 特征值可以是原子的或复杂的。原子值的一个特定类别是布尔值,按照惯例用[+/- f]表示。
- 两个特征可以共享一个值(原子的或复杂的)。具有共享值的结构被称为重入。共享的值被表示为AVM中的数字索引(或标记)。
- 一个特征结构中的路径是一个特征的元组,对应从图的根开始的弧的序列上的标签。
- 两条路径是等价的,如果它们共享一个值。
- 包含的特征结构是偏序的。FS0包含FS1,当包含在FS0中的所有信息也出现在FS1中。
- 两种结构FS0和FS1的统一,如果成功,就是包含FS0和FS1的合并信息的特征结构FS2。
- 如果统一在FS中指定一条路径π,那么它也指定等效与π的每个路径π'。
- 我们可以使用特征结构建立对大量广泛语言学现象的简洁的分析,包括动词子类别,倒装结构,无限制依赖结构和格支配。
5 深入阅读
本章进一步的材料请参考http://nltk.org/,包括特征结构、特征语法和语法测试套件。
X-bar句法:(Jacobs & Rosenbaum, 1970), (Jackendoff, 1977)(The primes we use replace Chomsky's typographically more demanding horizontal bars)。
协议现象的一个很好的介绍,请参阅(Corbett, 2006)。
理论语言学中最初使用特征的目的是捕捉语音的音素特性。例如,音/b/可能会被分解成结构[+labial, +voice]。一个重要的动机是捕捉分割的类别之间的一般性;例如/n/在任一+labial辅音前面被读作/m/。在乔姆斯基语法中,对一些现象,如协议,使用原子特征是很标准的,原子特征也用来捕捉跨句法类别的概括,通过类比与音韵。句法理论中使用特征的一个激进的扩展是广义短语结构语法(GPSG; (Gazdar, Klein, & and, 1985)),特别是在使用带有复杂值的特征。
从计算语言学的角度来看,(Dahl & Saint-Dizier, 1985)提出语言的功能方面可以被属性-值结构的统一捕获,一个类似的方法由(Grosz & Stickel, 1983)在PATR-II形式体系中精心设计完成。词汇功能语法(LFG; (Bresnan, 1982))的早期工作介绍了f-structure 概念,它的主要目的是表示语法关系和与成分结构短语关联的谓词参数结构。(Shieber, 1986)提供了研究基于特征语法方面的一个极好的介绍。
当研究人员试图为反面例子建模时,特征结构的代数方法的一个概念上的困难出现了。另一种观点,由(Kasper & Rounds, 1986)和(Johnson, 1988)开创,认为语法涉及结构功能的描述而不是结构本身。这些描述使用逻辑操作如合取相结合,而否定仅仅是特征描述上的普通的逻辑运算。这种面向描述的观点对LFG从一开始就是不可或缺的(参见(Huang & Chen, 1989)),也被中心词驱动短语结构语法的较高版本采用(HPSG; (Sag & Wasow, 1999))。http://www.cl.uni-bremen.de/HPSG-Bib/上有HPSG文献的全面的参考书目。
本章介绍的特征结构无法捕捉语言信息中重要的限制。例如,有没有办法表达NUM的值只允许是sg和pl,而指定[NUM=masc]是反常的。同样地,我们不能说AGR的复合值必须包含特征PER,NUM和gnd的指定,但不能包含如[SUBCAT=trans]这样的指定。指定类型的特征结构被开发出来弥补这方面的不足。开始,我们规定总是键入特征值。对于原子值,值就是类型。例如,我们可以说NUM的值是类型num。此外,num是NUM最一般类型的值。由于类型按层次结构组织,通过指定NUM的值为num的子类型,即要么是sg要么是pl,我们可以更富含信息。
In the case of complex values, we say that feature structures are themselves typed. So for example the value of AGR will be a feature structure of type AGR. We also stipulate that all and only PER, NUM and GND are appropriate features for a structure of type AGR. 一个早期的关于指定类型的特征结构的很好的总结是(Emele & Zajac, 1990)。一个形式化基础的更全面的检查可以在(Carpenter, 1992)中找到,(Copestake, 2002)重点关注为面向HPSG 的方法实现指定类型的特征结构。
有很多著作是关于德语的基于特征语法框架上的分析的。(Nerbonne, Netter, & Pollard, 1994)是这个主题的HPSG著作的一个好的起点,而(M{\"u}ller, 2002)给出HPSG 中的德语句法非常广泛和详细的分析。
(Jurafsky & Martin, 2008)的第15 章讨论了特征结构、统一的算法和将统一整合到分析算法中。
6 练习
☼ 需要什么样的限制才能正确分析词序列,如I am happy和she is happy而不是*you is happy或*they am happy?实现英语中动词be的现在时态范例的两个解决方案,首先以语法(6)作为起点,然后以语法 (18)为起点。
☼ 开发1.1中语法的变体,使用特征count来区分下面显示的句子:
(54) a. The boy sings.
b. *Boy sings.
(55) a. The boys sing.
b. Boys sing.
(56) a. The boys sing.
b. Boys sing.
(57) a. The water is precious.
b. Water is precious.
☼ 编一个写函数subsumes()判断两个特征结构fs1和fs2是否fs1包含fs2。
☼ 修改(28)中所示的语法纳入特征bar来处理短语投影。
◑ 开发一个基于特征的语法,能够正确描述下面的西班牙语名词短语:
◑ 开发EarleyChartParser的包装程序,只在输入序列分析出错时才输出跟踪。
◑ 思考6.1中的特征结构。
fs1 = nltk.FeatStruct("[A = ?x, B= [C = ?x]]") fs2 = nltk.FeatStruct("[B = [D = d]]") fs3 = nltk.FeatStruct("[B = [C = d]]") fs4 = nltk.FeatStruct("[A = (1)[B = b], C->(1)]") fs5 = nltk.FeatStruct("[A = (1)[D = ?x], C = [E -> (1), F = ?x] ]") fs6 = nltk.FeatStruct("[A = [D = d]]") fs7 = nltk.FeatStruct("[A = [D = d], C = [F = [D = d]]]") fs8 = nltk.FeatStruct("[A = (1)[D = ?x, G = ?x], C = [B = ?x, E -> (1)] ]") fs9 = nltk.FeatStruct("[A = [B = b], C = [E = [G = e]]]") fs10 = nltk.FeatStruct("[A = (1)[B = b], C -> (1)]")
例 6.1 (code_featstructures.py):图 6.1︰ 探索特征结构
在纸上计算下面的统一的结果是什么。(提示:你可能会发现绘制图结构很有用。)
- fs1 and fs2
- fs1 and fs3
- fs4 and fs5
- fs5 and fs6
- fs5 and fs7
- fs8 and fs9
- fs8 and fs10
用Python检查你的答案。
◑ 列出两个包含[A=?x, B=?x]的特征结构。
◑ 忽略结构共享,给出一个统一两个特征结构的非正式算法。
◑ 扩展3.2中的德语语法,使它能处理所谓的动词第二顺位结构,如下所示:
(58) Heute sieht der Hund die Katze.
◑ 同义动词的句法属性看上去略有不同(Levin, 1993)。思考下面的动词loaded、filled和dumped的语法模式。你能写语法产生式处理这些数据吗?
(59) a. The farmer loaded the cart with sand
b. The farmer loaded sand into the cart
c. The farmer filled the cart with sand
d. *The farmer filled sand into the cart
e. *The farmer dumped the cart with sand
f. The farmer dumped sand into the cart
★ 形态范例很少是完全正规的,矩阵中的每个单元的意义有不同的实现。例如,词位walk的现在时态词性变化只有两种不同形式:第三人称单数的walks和所有其他人称和数量的组合的walk。一个成功的分析不应该额外要求6个可能的形态组合中有5个有相同的实现。设计和实施一个方法处理这个问题。
★ 所谓的核心特征在父节点和核心孩子节点之间共享。例如,TENSE是核心特征,在一个VP和它的核心孩子V之间共享。更多细节见(Gazdar, Klein, & and, 1985)。我们看到的结构中大部分是核心结构——除了SUBCAT和SLASH。由于核心特征的共享是可以预见的,它不需要在语法产生式中明确表示。开发一种方法自动计算核心结构的这种规则行为的比重。
★ 扩展NLTK中特征结构的处理,允许统一值为列表的特征,使用这个来实现一个HPSG风格的子类别分析,核心类别的SUBCAT是它的补语的类别和它直接父母的SUBCAT值的连结。
★ 扩展NLTK的特征结构处理,允许带未指定类别的产生式,例如S[-INV] --> ?x S/?x。
★ 扩展NLTK的特征结构处理,允许指定类型的特征结构。
★ 挑选一些(Huddleston & Pullum, 2002)中描述的文法结构,建立一个基于特征的语法计算它们的比例。
关于本文档...
针对NLTK 3.0 进行更新。本章来自于Natural Language Processing with Python,Steven Bird, Ewan Klein 和Edward Loper,Copyright © 2014 作者所有。本章依据Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License [http://creativecommons.org/licenses/by-nc-nd/3.0/us/] 条款,与自然语言工具包 [http://nltk.org/] 3.0 版一起发行。
本文档构建于星期三 2015 年 7 月 1 日 12:30:05 AEST