使用Firebug进行爬取¶
注
本教程所使用的样例站Google Directory已经 被Google关闭 了。The concepts in this guide are still valid though. If you want to update this guide to use a new (working) site, your contribution will be more than welcome!. See Contributing to Scrapy for information on how to do so.
介绍¶
This document explains how to use Firebug (a Firefox add-on) to make the scraping process easier and more fun. For other useful Firefox add-ons see Useful Firefox add-ons for scraping. There are some caveats with using Firefox add-ons to inspect pages, see Caveats with inspecting the live browser DOM.
在本样例中将展现如何使用 Firebug从Google Directory来爬取数据,它包含了教程 里所使用的Open Directory Project中一样的数据,不过有着不同的结构。
Firebug提供了非常实用的检查元素功能,该功能允许您将鼠标悬浮在不同的页面元素上, 显示相应元素的HTML代码。Otherwise you would have to search for the tags manually through the HTML body which can be a very tedious task.
在下列截图中,您将看到检查元素的执行效果。
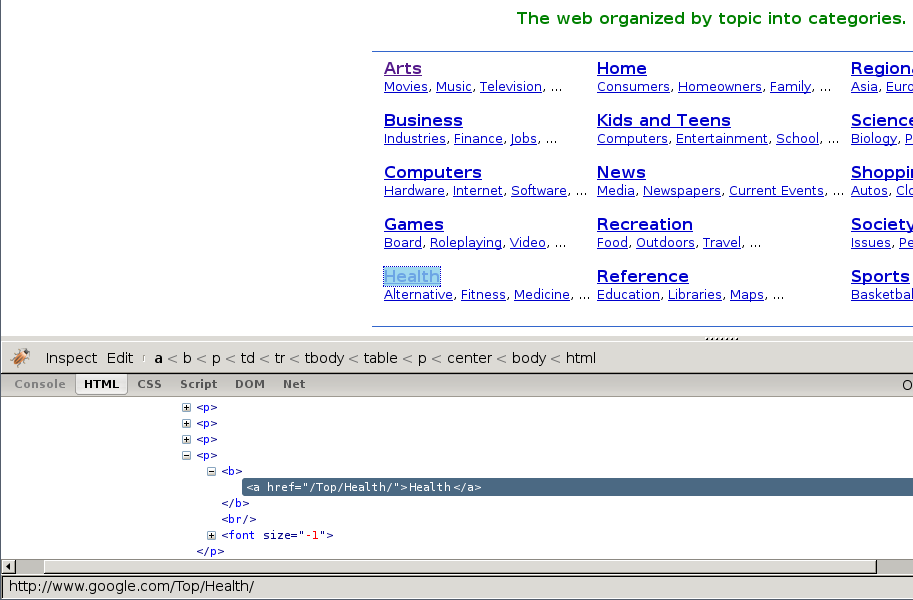
At first sight, we can see that the directory is divided in categories, which are also divided in subcategories.
However, it seems that there are more subcategories than the ones being shown in this page, so we’ll keep looking:
As expected, the subcategories contain links to other subcategories, and also links to actual websites, which is the purpose of the directory.
获取到跟进(follow)的链接¶
By looking at the category URLs we can see they share a pattern:
一旦我们知道了这点,我们就可以构建一个正则表达式来跟进链接。例如,下面的这个:
directory\.google\.com/[A-Z][a-zA-Z_/]+$
因此,根据这个表达式,我们创建第一个爬取规则:
Rule(LinkExtractor(allow='directory.google.com/[A-Z][a-zA-Z_/]+$', ),
'parse_category',
follow=True,
),
Rule对象指导基于 CrawlSpider 的spider如何跟进目录链接。parse_category will be a method of the spider which will process and extract data from those pages.
下面是Spider到目前为止的样子:
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class GoogleDirectorySpider(CrawlSpider):
name = 'directory.google.com'
allowed_domains = ['directory.google.com']
start_urls = ['http://directory.google.com/']
rules = (
Rule(LinkExtractor(allow='directory\.google\.com/[A-Z][a-zA-Z_/]+$'),
'parse_category', follow=True,
),
)
def parse_category(self, response):
# write the category page data extraction code here
pass
提取数据¶
Now we’re going to write the code to extract data from those pages.
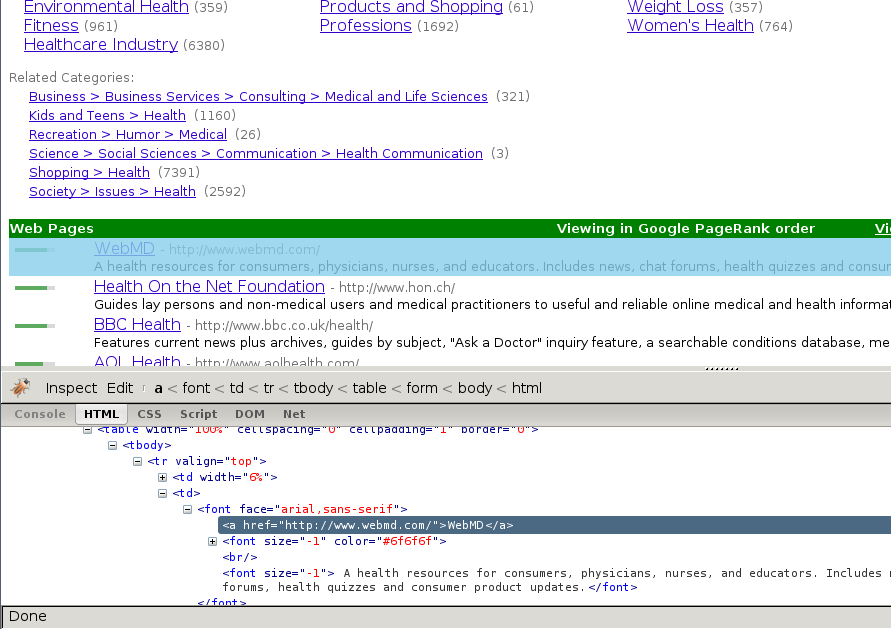
在Firebug的帮助下,我们将查看一些包含网站链接的网页(以http://directory.google.com/Top/Arts/Awards/为例), 找到使用 Selectors 提取链接的方法。我们也将使用Scrapy shell来测试得到的XPath表达式,确保表达式工作符合预期。

正如您所看到的那样,页面的标记并不是十分明显: 元素并不包含id, class或任何可以区分的属性。所以我们将使用等级槽(rank bar)作为指示点来选择提取的数据,创建XPath。
使用Firebug,我们可以看到每个链接都在 td 标签中。该标签存在于同时(在另一个 td)包含链接的等级槽(ranking bar)的 tr 中。
所以我们选择等级槽(ranking bar),接着找到其父节点(tr),最后是(包含我们要爬取数据的)链接的 td 。
对应的XPath:
//td[descendant::a[contains(@href, "#pagerank")]]/following-sibling::td//a
使用Scrapy shell来测试这些复杂的XPath表达式,确保其工作符合预期。
简单来说,该表达式会查找等级槽的td元素,接着选择所有td元素,该元素拥有子孙a元素,且 a 元素的属性href包含字符串#pagerank。
Of course, this is not the only XPath, and maybe not the simpler one to select that data. Another approach could be, for example, to find any font tags that have that grey colour of the links,
Finally, we can write our parse_category() method:
def parse_category(self, response):
# The path to website links in directory page
links = response.xpath('//td[descendant::a[contains(@href, "#pagerank")]]/following-sibling::td/font')
for link in links:
item = DirectoryItem()
item['name'] = link.xpath('a/text()').extract()
item['url'] = link.xpath('a/@href').extract()
item['description'] = link.xpath('font[2]/text()').extract()
yield item
Be aware that you may find some elements which appear in Firebug but not in the original HTML, such as the typical case of <tbody> elements.
or tags which Therefer in page HTML sources may on Firebug inspects the live DOM