scan — Theano中的循环¶
指南¶
Scan函数提供在Theano中执行循环所需的基本功能。Scan很花哨,我们将通过例子的方式介绍。
简单的循环累加:计算 ¶
¶
假设,给定k,你想使用循环获得A**k。更确切地说,如果A是张量,你想以元素级别计算A**k。python/numpy代码可能如下所示:
result = 1
for i in range(k):
result = result * A
这里有三个事情要处理:分配给result的初始值,result中的结果累加,和不变的变量A。不变的变量以non_sequences传递给scan。Initialization occurs in outputs_info, and the accumulation happens automatically.
The equivalent Theano code would be:
import theano
import theano.tensor as T
k = T.iscalar("k")
A = T.vector("A")
# Symbolic description of the result
result, updates = theano.scan(fn=lambda prior_result, A: prior_result * A,
outputs_info=T.ones_like(A),
non_sequences=A,
n_steps=k)
# We only care about A**k, but scan has provided us with A**1 through A**k.
# Discard the values that we don't care about. Scan is smart enough to
# notice this and not waste memory saving them.
final_result = result[-1]
# compiled function that returns A**k
power = theano.function(inputs=[A,k], outputs=final_result, updates=updates)
print(power(range(10),2))
print(power(range(10),4))
[ 0. 1. 4. 9. 16. 25. 36. 49. 64. 81.]
[ 0.00000000e+00 1.00000000e+00 1.60000000e+01 8.10000000e+01
2.56000000e+02 6.25000000e+02 1.29600000e+03 2.40100000e+03
4.09600000e+03 6.56100000e+03]
让我们逐行分析示例。我们做的是首先构造一个函数(使用lambda表达式),给定prior_result和A返回prior_result * A。参数的顺序通过scan固定:上一次调用fn的输出(或初始的初始值)为第一个参数,后面则为所有的固定变量(non_sequences)。
接下来,我们将输出(outputs_info)初始化为一个每个元素被填充为1的张量,它与A具有相同形状和dtype。然后,我们把A传递给scan,作为一个固定变量(non_sequences)参数,并指定步数k来迭代我们的lambda表达式。
Scan返回一个元组,包含我们的结果(result)和updates字典(在这个例子中为空)。Note that the result is not a matrix, but a 3D tensor containing the value of A**k for each step. 我们想要的是最后一个值(k步之后),所以我们编译一个函数来返回该值。注意这里会有一个优化,在编译时会检测到你只使用结果的最后一个值,并确保scan不存储所有使用的中间值。So do not worry if A and k are large.
在张量的第一维上迭代:计算多项式¶
除了循环固定次数之外,scan还可以在张量的主导维度上迭代(类似于Python的for x in a_list)。
要循环的张量应该使用sequence关键字参数传递给scan。
Here’s an example that builds a symbolic calculation of a polynomial from a list of its coefficients:
import numpy
coefficients = theano.tensor.vector("coefficients")
x = T.scalar("x")
max_coefficients_supported = 10000
# Generate the components of the polynomial
components, updates = theano.scan(fn=lambda coefficient, power, free_variable: coefficient * (free_variable ** power),
outputs_info=None,
sequences=[coefficients, theano.tensor.arange(max_coefficients_supported)],
non_sequences=x)
# Sum them up
polynomial = components.sum()
# Compile a function
calculate_polynomial = theano.function(inputs=[coefficients, x], outputs=polynomial)
# Test
test_coefficients = numpy.asarray([1, 0, 2], dtype=numpy.float32)
test_value = 3
print(calculate_polynomial(test_coefficients, test_value))
print(1.0 * (3 ** 0) + 0.0 * (3 ** 1) + 2.0 * (3 ** 2))
19.0
19.0
There are a few things to note here.
首先,我们通过先生成每个系数,然后在最后对它们求和来计算多项式。(我们也可以累积它们,然后取最后一个值,这样内存更高效,但这仅是一个例子)。
Second, there is no accumulation of results, we can set outputs_info to None. 这指示scan它不需要将先前的结果传递给fn。
The general order of function parameters to fn is:
sequences (if any), prior result(s) (if needed), non-sequences (if any)
第三,可以用一个方便的方法来模拟python的enumerate:即简单地在sequences中加入theano.tensor.arange。
第四,如果给定多个不同长度的sequences,scan会将其缩短为它们中最短的长度。这也使得我们(为了更通用)可以放心地传递一个很长的arange,因为arange在创建时必须指定其长度。
不用lambda表达式,简单地累加到标量中¶
虽然这个例子看起来几乎是不言自明的,但它强调了一个要小心的缺陷:所提供的输出初值,即outputs_info,形状必须和每次迭代时生成的输出变量类似,此外,它绝不可以影响到后者的后续迭代。
import numpy as np
import theano
import theano.tensor as T
up_to = T.iscalar("up_to")
# define a named function, rather than using lambda
def accumulate_by_adding(arange_val, sum_to_date):
return sum_to_date + arange_val
seq = T.arange(up_to)
# An unauthorized implicit downcast from the dtype of 'seq', to that of
# 'T.as_tensor_variable(0)' which is of dtype 'int8' by default would occur
# if this instruction were to be used instead of the next one:
# outputs_info = T.as_tensor_variable(0)
outputs_info = T.as_tensor_variable(np.asarray(0, seq.dtype))
scan_result, scan_updates = theano.scan(fn=accumulate_by_adding,
outputs_info=outputs_info,
sequences=seq)
triangular_sequence = theano.function(inputs=[up_to], outputs=scan_result)
# test
some_num = 15
print(triangular_sequence(some_num))
print([n * (n + 1) // 2 for n in range(some_num)])
[ 0 1 3 6 10 15 21 28 36 45 55 66 78 91 105]
[0, 1, 3, 6, 10, 15, 21, 28, 36, 45, 55, 66, 78, 91, 105]
另一个简单的例子¶
不同于之前的一些例子,这个例子如果不使用scan,很难用其它方法重新实现。
它的参数为一个由索引数组组成的序列和索引对应的值,以及一个输出数组“模型”(其形状和dtype即为模版)。它会产生和模型具有相同的shape和dtype数组的一个序列,除了在指定的数组索引处,其余所有值都设置为0。
location = T.imatrix("location")
values = T.vector("values")
output_model = T.matrix("output_model")
def set_value_at_position(a_location, a_value, output_model):
zeros = T.zeros_like(output_model)
zeros_subtensor = zeros[a_location[0], a_location[1]]
return T.set_subtensor(zeros_subtensor, a_value)
result, updates = theano.scan(fn=set_value_at_position,
outputs_info=None,
sequences=[location, values],
non_sequences=output_model)
assign_values_at_positions = theano.function(inputs=[location, values, output_model], outputs=result)
# test
test_locations = numpy.asarray([[1, 1], [2, 3]], dtype=numpy.int32)
test_values = numpy.asarray([42, 50], dtype=numpy.float32)
test_output_model = numpy.zeros((5, 5), dtype=numpy.float32)
print(assign_values_at_positions(test_locations, test_values, test_output_model))
[[[ 0. 0. 0. 0. 0.]
[ 0. 42. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]]
[[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 50. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]]]
这表明你可以将新的Theano变量引入scan函数。
多个输出、多个点击值 — 用Scan实现循环神经网络¶
The examples above showed simple uses of scan. However, scan also supports referring not only to the prior result and the current sequence value, but also looking back more than one step.
This is needed, for example, to implement a RNN using scan. Assume that our RNN is defined as follows :
Note that this network is far from a classical recurrent neural network and might be useless. The reason we defined as such is to better illustrate the features of scan.
In this case we have a sequence over which we need to iterate u, and two outputs x and y. To implement this with scan we first construct a function that computes one iteration step :
def oneStep(u_tm4, u_t, x_tm3, x_tm1, y_tm1, W, W_in_1, W_in_2, W_feedback, W_out):
x_t = T.tanh(theano.dot(x_tm1, W) + \
theano.dot(u_t, W_in_1) + \
theano.dot(u_tm4, W_in_2) + \
theano.dot(y_tm1, W_feedback))
y_t = theano.dot(x_tm3, W_out)
return [x_t, y_t]
As naming convention for the variables we used a_tmb to mean a at t-b and a_tpb to be a at t+b. Note the order in which the parameters are given, and in which the result is returned. Try to respect chronological order among the taps ( time slices of sequences or outputs) used. For scan is crucial only for the variables representing the different time taps to be in the same order as the one in which these taps are given. Also, not only taps should respect an order, but also variables, since this is how scan figures out what should be represented by what. Given that we have all the Theano variables needed we construct our RNN as follows :
W = T.matrix()
W_in_1 = T.matrix()
W_in_2 = T.matrix()
W_feedback = T.matrix()
W_out = T.matrix()
u = T.matrix() # it is a sequence of vectors
x0 = T.matrix() # initial state of x has to be a matrix, since
# it has to cover x[-3]
y0 = T.vector() # y0 is just a vector since scan has only to provide
# y[-1]
([x_vals, y_vals], updates) = theano.scan(fn=oneStep,
sequences=dict(input=u, taps=[-4,-0]),
outputs_info=[dict(initial=x0, taps=[-3,-1]), y0],
non_sequences=[W, W_in_1, W_in_2, W_feedback, W_out],
strict=True)
# for second input y, scan adds -1 in output_taps by default
Now x_vals and y_vals are symbolic variables pointing to the sequence of x and y values generated by iterating over u. The sequence_taps, outputs_taps give to scan information about what slices are exactly needed. Note that if we want to use x[t-k] we do not need to also have x[t-(k-1)], x[t-(k-2)],.., but when applying the compiled function, the numpy array given to represent this sequence should be large enough to cover this values. Assume that we compile the above function, and we give as u the array uvals = [0,1,2,3,4,5,6,7,8]. By abusing notations, scan will consider uvals[0] as u[-4], and will start scaning from uvals[4] towards the end.
Conditional ending of Scan¶
Scan can also be used as a repeat-until block. In such a case scan will stop when either the maximal number of iteration is reached, or the provided condition evaluates to True.
For an example, we will compute all powers of two smaller then some provided value max_value.
def power_of_2(previous_power, max_value):
return previous_power*2, theano.scan_module.until(previous_power*2 > max_value)
max_value = T.scalar()
values, _ = theano.scan(power_of_2,
outputs_info = T.constant(1.),
non_sequences = max_value,
n_steps = 1024)
f = theano.function([max_value], values)
print(f(45))
[ 2. 4. 8. 16. 32. 64.]
As you can see, in order to terminate on condition, the only thing required is that the inner function power_of_2 to return also the condition wrapped in the class theano.scan_module.until. The condition has to be expressed in terms of the arguments of the inner function (in this case previous_power and max_value).
As a rule, scan always expects the condition to be the last thing returned by the inner function, otherwise an error will be raised.
Reducing Scan’s memory usage¶
This section presents the scan_checkpoints function. In short, this function reduces the memory usage of scan (at the cost of more computation time) by not keeping in memory all the intermediate time steps of the loop, and recomputing them when computing the gradients. This function is therefore only useful if you need to compute the gradient of the ouptut of scan with respect to its inputs, and shouldn’t be used otherwise.
Before going more into the details, here are its current limitations:
- It only works in the case where only the output of the last time step is needed, like when computing
A**kor in an encoder-decoder setup. - It only accepts sequences of the same length.
- If
n_stepsis specified, it has the same value as the length of any sequences. - It is signly-recurrent, meaning that only the previous time step can be used to compute the current one (ie
h[t]can only depend onh[t-1]). In other words,tapscan not be used insequencesandoutputs_info.
Often, in order to be able to compute the gradients through scan operations, Theano needs to keep in memory some intermediate computations of scan. This can sometimes use a prohibitively large amount of memory. scan_checkpoints allows to discard some of those intermediate steps and recompute them again when computing the gradients. Its save_every_N argument specifies the number time steps to do without storing the intermediate results. For example, save_every_N = 4 will reduce the memory usage by 4, while having to recompute 3/4 time steps of the forward loop. Since the grad of scan is about 6x slower than the forward, a ~20% slowdown is expected. Apart from the save_every_N argument and the current limitations, the usage of this function is similar to the classic scan function.
Optimizing Scan’s performance¶
This section covers some ways to improve performance of a Theano function using Scan.
Minimizing Scan usage¶
Scan makes it possible to define simple and compact graphs that can do the same work as much larger and more complicated graphs. However, it comes with a significant overhead. As such, when performance is the objective, a good rule of thumb is to perform as much of the computation as possible outside of Scan. This may have the effect of increasing memory usage but can also reduce the overhead introduces by using Scan.
Explicitly passing inputs of the inner function to scan¶
It is possible, inside of Scan, to use variables previously defined outside of the Scan without explicitly passing them as inputs to the Scan. However, it is often more efficient to explicitly pass them as non-sequence inputs instead. Section Using shared variables - Gibbs sampling provides an explanation for this and section Using shared variables - the strict flag describes the strict flag, a tool that Scan provides to help ensure that the inputs to the function inside Scan have all been provided as explicit inputs to the scan() function.
Deactivating garbage collecting in Scan¶
Deactivating the garbage collection for Scan can allow it to reuse memory between executions instead of always having to allocate new memory. This can improve performance at the cost of increased memory usage. By default, Scan reuses memory between iterations of the same execution but frees the memory after the last iteration.
There are two ways to achieve this, using the Theano flag config.scan.allow_gc and setting it to False, or using the argument allow_gc of the function theano.scan() and set it to False (when a value is not provided for this argument, the value of the flag config.scan.allow_gc is used).
Graph optimizations¶
This one is simple but still worth pointing out. Theano is able to automatically recognize and optimize many computation patterns. However, there are patterns that Theano doesn’t optimize because doing so would change the user interface (such as merging shared variables together into a single one, for instance). Additionaly, Theano doesn’t catch every case that it could optimize and so it remains useful for performance that the user defines an efficient graph in the first place. This is also the case, and sometimes even more so, for the graph inside of Scan. This is because it will be executed many times for every execution of the Theano function that contains it.
The LSTM tutorial on DeepLearning.net provides an example of an optimization that Theano cannot perform. Instead of performing many matrix multiplications between matrix 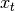 and each of the shared matrices
and each of the shared matrices 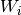 ,
, 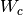 ,
, 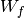 and
and  , the matrices
, the matrices  , are merged into a single shared matrix
, are merged into a single shared matrix  and the graph performs a single larger matrix multiplication between and . The resulting matrix is then sliced to obtain the results of that the small individual matrix multiplications would have produced. This optimization replaces several small and inefficient matrix multiplications by a single larger one and thus improves performance at the cost of a potentially higher memory usage.
and the graph performs a single larger matrix multiplication between and . The resulting matrix is then sliced to obtain the results of that the small individual matrix multiplications would have produced. This optimization replaces several small and inefficient matrix multiplications by a single larger one and thus improves performance at the cost of a potentially higher memory usage.
参考¶
本模块提供Scan Op。
Scan是一种常见的重复形式,可用于循环。它的思想是你沿着某个输入序列scan一个函数,每次产生一个输出,并且该函数在下一次可以看到这个输出(但不会修改)。(技术上,该函数可以看到你的前K次的输出和(从过去和未来)前L次的输入。
例如,给定初始状态z=0,通过在一个列表上scan z+x_i函数,可以计算sum()。
Special cases:
- 可以通过仅返回
scan的最后一个输出来执行reduce操作。 - 可以通过应用一个忽略先前步骤输出的函数来执行map操作。
Often a for-loop can be expressed as a scan() operation, and scan is the closest that theano comes to looping. The advantage of using scan over for loops is that it allows the number of iterations to be a part of the symbolic graph.
The Scan Op should typically be used by calling any of the following functions: scan(), map(), reduce(), foldl(), foldr().
-
theano.map(fn, sequences, non_sequences=None, truncate_gradient=-1, go_backwards=False, mode=None, name=None)[source]¶ Similar behaviour as python’s map.
Parameters: - fn – The function that
mapapplies at each iteration step (seescanfor more info). - sequences – List of sequences over which
mapiterates (seescanfor more info). - non_sequences – List of arguments passed to
fn.mapwill not iterate over these arguments (seescanfor more info). - truncate_gradient – See
scan. - go_backwards (bool) – Decides the direction of iteration. True means that sequences are parsed from the end towards the begining, while False is the other way around.
- mode – See
scan. - name – See
scan.
- fn – The function that
-
theano.reduce(fn, sequences, outputs_info, non_sequences=None, go_backwards=False, mode=None, name=None)[source]¶ Similar behaviour as python’s reduce.
Parameters: - fn – The function that
reduceapplies at each iteration step (seescanfor more info). - sequences – List of sequences over which
reduceiterates (seescanfor more info). - outputs_info – List of dictionaries describing the outputs of reduce (see
scanfor more info). - non_sequences –
- List of arguments passed to
fn.reducewill - not iterate over these arguments (see
scanfor more info).
- List of arguments passed to
- go_backwards (bool) – Decides the direction of iteration. True means that sequences are parsed from the end towards the begining, while False is the other way around.
- mode – See
scan. - name – See
scan.
- fn – The function that
-
theano.foldl(fn, sequences, outputs_info, non_sequences=None, mode=None, name=None)[source]¶ Similar behaviour as haskell’s foldl.
Parameters: - fn – The function that
foldlapplies at each iteration step (seescanfor more info). - sequences – List of sequences over which
foldliterates (seescanfor more info). - outputs_info – List of dictionaries describing the outputs of reduce (see
scanfor more info). - non_sequences – List of arguments passed to fn.
foldlwill not iterate over these arguments (seescanfor more info). - mode – See
scan. - name – See
scan.
- fn – The function that
-
theano.foldr(fn, sequences, outputs_info, non_sequences=None, mode=None, name=None)[source]¶ Similar behaviour as haskell’ foldr.
Parameters: - fn – The function that
foldrapplies at each iteration step (seescanfor more info). - sequences – List of sequences over which
foldriterates (seescanfor more info). - outputs_info – List of dictionaries describing the outputs of reduce (see
scanfor more info). - non_sequences – List of arguments passed to fn.
foldrwill not iterate over these arguments (seescanfor more info). - mode – See
scan. - name – See
scan.
- fn – The function that
-
theano.scan(fn, sequences=None, outputs_info=None, non_sequences=None, n_steps=None, truncate_gradient=-1, go_backwards=False, mode=None, name=None, profile=False, allow_gc=None, strict=False)[source]¶ This function constructs and applies a Scan op to the provided arguments.
Parameters: - fn —
fnis a function that describes the operations involved in one step ofscan.fnshould construct variables describing the output of one iteration step. 它应该期望输入的theano变量表示输入序列的所有切片和输出的初始值,并且其它所有传递给scan的参数为non_sequences。scan将这些变量传递到fn的顺序如下:- 第一个序列的所有切片
- 第二个序列的所有切片
- ...
- 最后一个序列的所有切片
- 第一个输出的所有初始切片
- 第二个输出的所有初始切片
- ...
- 最后一个输出的所有初始切片
- 所有其他参数(作为non_sequences给出的列表)
序列的顺序与传递给scan的列表sequences中的顺序相同。The order of the outputs is the same as the order of
outputs_info. For any sequence or output the order of the time slices is the same as the one in which they have been given as taps. For example if one writes the following :scan(fn, sequences = [ dict(input= Sequence1, taps = [-3,2,-1]) , Sequence2 , dict(input = Sequence3, taps = 3) ] , outputs_info = [ dict(initial = Output1, taps = [-3,-5]) , dict(initial = Output2, taps = None) , Output3 ] , non_sequences = [ Argument1, Argument2])
fn应该按以下给定顺序期望参数:Sequence1[t-3]Sequence1[t+2]Sequence1[t-1]Sequence2[t]Sequence3[t+3]Output1[t-3]Output1[t-5]Output3[t-1]Argument1Argument2
The list of
non_sequencescan also contain shared variables used in the function, thoughscanis able to figure those out on its own so they can be skipped. 为了代码清晰,我们建议尽量将它们提供给scan。在某种程度上,scan也可以计算出其他non sequences(不是共享变量),甚至即使它们没有传递给scan(但由fn使用)。A simple example of this would be :import theano.tensor as TT W = TT.matrix() W_2 = W**2 def f(x): return TT.dot(x,W_2)
预期该函数返回两个东西。One is a list of outputs ordered in the same order as
outputs_info, with the difference that there should be only one output variable per output initial state (even if no tap value is used). Secondly fn should return an update dictionary (that tells how to update any shared variable after each iteration step). 这个字典是可选的,可以用元组组成的列表给出。对这两个列表的顺序没有约束,fn可以返回(outputs_list, update_dictionary)或(update_dictionary, outputs_list)或只是其中一个(如果另一个为空)。To use
scanas a while loop, the user needs to change the functionfnsuch that also a stopping condition is returned. To do so, he/she needs to wrap the condition in anuntilclass. The condition should be returned as a third element, for example:... return [y1_t, y2_t], {x:x+1}, theano.scan_module.until(x < 50)
注意,即使条件被传递(并且如果需要它被用于分配内存),仍然需要多个步骤(在这里被视为最大步骤数)。= {}):
- sequences —
sequencesis the list of Theano variables or dictionaries describing the sequencesscanhas to iterate over. If a sequence is given as wrapped in a dictionary, then a set of optional information can be provided about the sequence. The dictionary should have the following keys:input(必需的)— 表示序列的Theano变量。taps—fn所需序列的temporal taps。它们作为整数列提供,其中值k暗示在迭代步骤t,scan将传递切片t+k给fn。Default value is[0]
Any Theano variable in the list
sequencesis automatically wrapped into a dictionary wheretapsis set to[0] - outputs_info –
outputs_info是Theano变量或字典的列表,描述重复计算的输出的初始状态。当该初始状态以字典给出时,可以提供关于与这些初始状态相对应的输出的可选信息。The dictionary should have the following keys:initial— Theano变量,表示给定输出的初始状态。In case the output is not computed recursively (think of a map) and does not require an initial state this field can be skipped. 由于fn(仅)使用上一次的输出,初始状态应当与输出具有相同的形状,并且不应该涉及downcast到输出的数据类型。如果用到多个time taps,则初始状态应当具有一个额外维度来覆盖所有可能的taps。例如,如果我们使用-5,-2and-1作为过去的taps,在步骤0,fn将需要(通过滥用符号)output[-5],output[-2]andoutput[-1]。这将由初始状态给出,在这种情况下应该具有shape (5,)+output.shape。If this variable containing the initial state is calledinit_ytheninit_y[0]corresponds tooutput[-5].init_y[1]对应于output[-4],init_y[2]对应于output[-3],init_y[3]对应于output[-2],init_y[4]对应于output[-1]。While this order might seem strange, it comes natural from splitting an array at a given point. Assume that we have a arrayx, and we choosekto be time step0. Then our initial state would bex[:k], while the output will bex[k:]. Looking at this split, elements inx[:k]are ordered exactly like those ininit_y.taps– Temporal taps of the output that will be pass tofn. They are provided as a list of negative integers, where a valuekimplies that at iteration steptscan will pass tofnthe slicet+k.
scanwill follow this logic if partial information is given:- 如果输出不包含在字典中,则
scan会将它封装在一个字典中,并假设你只使用输出的最后一步(即它使你的tap值的列表等于[-1]) 。 - 如果你将一个输出封装在一个字典中,并且你不提供任何tap,但是你提供一个初始状态,它将假设你只使用一个tap值-1。
- 如果你将一个输出封装在一个字典中,但你不提供任何初始状态,它假定你没有使用任何形式的tap。
- 如果你提供
None而不是变量或空字典,scan假设你不会对这个输出使用任何tap(例如在map的情况下)。
如果
outputs_info是一个空的列表或无,则scan假定没有任何tap用于任何输出。如果仅为输出的子集提供信息,则引发异常(因为没有关于scan应如何将提供的信息映射到fn的输出的约定)。 - non_sequences –
non_sequencesis the list of arguments that are passed tofnat each steps. One can opt to exclude variable used infnfrom this list as long as they are part of the computational graph, though for clarity we encourage not to do so. - n_steps –
n_stepsis the number of steps to iterate given as an int or Theano scalar. If any of the input sequences do not have enough elements, scan will raise an error. If the value is 0 the outputs will have 0 rows. If the value is negative,scanwill run backwards in time. 如果go_backwards标记已设置,并且n_steps为负,则scan将按时间向前运行。If n_steps is not provided,scanwill figure out the amount of steps it should run given its input sequences. - truncate_gradient –
truncate_gradientis the number of steps to use in truncated BPTT. If you compute gradients through a scan op, they are computed using backpropagation through time. By providing a different value then -1, you choose to use truncated BPTT instead of classical BPTT, where you go for onlytruncate_gradientnumber of steps back in time. - go_backwards –
go_backwardsis a flag indicating ifscanshould go backwards through the sequences. If you think of each sequence as indexed by time, making this flag True would mean thatscangoes back in time, namely that for any sequence it starts from the end and goes towards 0. - name — 当profiling
scan时,为scan的任何实例提供名称至关重要。The profiler will produce an overall profile of your code as well as profiles for the computation of one step of each instance ofscan. Thenameof the instance appears in those profiles and can greatly help to disambiguate information. - mode – It is recommended to leave this argument to None, especially when profiling
scan(otherwise the results are not going to be accurate). If you prefer the computations of one step ofscanto be done differently then the entire function, you can use this parameter to describe how the computations in this loop are done (seetheano.functionfor details about possible values and their meaning). - profile — 标志或字符串。If true, or different from the empty string, a profile object will be created and attached to the inner graph of scan. In case
profileis True, the profile object will have the name of the scan instance, otherwise it will have the passed string. Profile object collect (and print) information only when running the inner graph with the new cvm linker ( with default modes, other linkers this argument is useless) - allow_gc – Set the value of allow gc for the internal graph of scan. If set to None, this will use the value of config.scan.allow_gc.
- strict — 如果为真,则
fn中使用的所有共享变量必须作为non_sequences或sequences。
Returns: (outputs, updates)形式的元组;
outputs是一个Theano变量或一个Theano变量列表表示scan的输出(按照与outputs_info中相同的顺序)。updates是字典的一个子类,指定在scan中使用的所有共享变量的更新规则。This dictionary should be passed totheano.functionwhen you compile your function. 与正常字典相比的变化是,我们验证字典的键是SharedVariable,并且这些字典的相加被验证为一致。Return type: 元组
- fn —