ALBERT:用于语言表示学习的自监督轻量级 BERT
Zhenzhong Lan1Mingda Chen2∗Sebastian Goodman1Kevin Gimpel2
Piyush Sharma1Radu Soricut1
1Google Research2Toyota Technological Institute at Chicago
{lanzhzh, seabass, piyushsharma, rsoricut}@google.com
{mchen, kgimpel}@ttic.edu
摘 要
预训练自然语言的表示时,增加模型大小通常可提高下游任务的性能。 但是,由于 GPU/TPU 内存限制、训练时间较长以及模型意外变差,在某些时候增大模型变得更加困难。 为了解决这些问题,我们提出了两种参数缩减技术,以降低内存消耗并提高 BERT 的训练速度(Devlin 等人,2019 年)。 综合实证证据表明,我们提出的方法比原来的 BERT 模型具有更好的可扩展性。 我们还使用一种侧重于建模句间连贯性的自监督损失,并一致表明它对多句子输入的下游任务有所帮助。 因此,我们的最佳模型在 GLUE、RACE 和 SQuAD 基准上建立了新的最先进的结果,而且相比 BERT-large 参数更少。 代码和预训练好的模型可在 https://github.com/google-research/google-research/tree/master/albert 获取到。
1简介
全面网络预训练(Dai 和 Le, 2015;Radford 等人,2018;Devlin 等人,2019;Howard 和 Ruder, 2018)在语言表示学习方面取得了一系列突破。 许多很难的 NLP 任务,包括那些训练数据有限的任务,都大大受益于这些预先训练的模型。 这些突破最引人注目的迹象之一是,在中国专为初中、高中英语考试设计的阅读理解任务即 RACE 考试中机器性能的演变(Lai等人,2017年):最初描述该任务并制定该建模挑战的论文报告的最先进的机器准确率为44.1%;最新公布的结果报告其模型性能为83.2%(Liu 等人,2019年);我们在这里的工作甚至推动它更高到 89.4%,惊人的 45.3% 的改进,这主要归功于我们目前建立高性能的预训练语言表示的能力。
这些改进的证据表明,大型网络对于实现最先进的性能至关重要(Devlin 等人,2019;Radford 等人,2019)。 在实际应用中,对大型模型进行预训练并将其提炼为小型模型已成为常见做法(Sun et al., 2019; Turc et al., 2019)。 考虑到模型大小的重要性,我们问:拥有更好的 NLP 模型是否像拥有更大的模型一样简单?
回答这个问题的一个障碍是可用硬件的内存限制。 鉴于当前最先进的模型通常具有数亿甚至数十亿个参数,当我们尝试扩展模型时,很容易达到这些限制。 在分布式训练中,训练速度也会受到很大阻碍,因为通信开销与模型中的参数数量成正比。 我们还观察到,仅仅增加 BERT-large(Devlin 等人,2019 年)等模型的隐藏层大小可能会导致性能下降。 表 1 和图 1 显示了一个典型的示例,其中我们仅仅将 BERT-large 的隐藏层大小扩大 2 倍,获得比 BERT-xlarge 模型更差的结果。
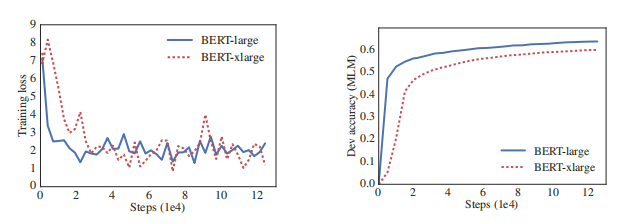
图 1:BERT-large 和 BERT-xlarge(隐藏层大小比 BERT-large 大 2 倍)的训练集损失(左)和 验证集 masked LM 准确率(右)。 较大的模型在没有明显的过度拟合迹象的情况下,具有较低的屏蔽 LM 准确率。
| 模型 | 隐藏大小 | 参数 | RACE (Accuracy) |
| BERT-large (Devlin et al., 2019) | 1024 | 334M | 72.0% |
| BERT-large (ours) | 1024 | 334M | 73.9% |
| BERT-xlarge (ours) | 2048 | 1270M | 54.3% |
表 1: 增加 BERT-large 的隐藏大小会导致 RACE 的性能下降。
上述问题的现有解决方案包括模型并行化(Shoeybi等人,2019年)和智能内存管理(Chen等人,2016年;戈麦斯等人,2017年)。 这些解决方案解决内存限制问题,但没有解决通信开销和模型变差问题。 在本文中,我们通过设计一个比传统的 BERT 体系结构参数少得多的精简 BERT (ALBERT) 体系结构来解决上述所有问题。
ALBERT 采用两种参数缩减技术,可解除扩展预训练模型的主要障碍。 第一个是分解嵌入的参数化。 通过将大型词汇嵌入矩阵分解为两个小矩阵,我们将隐藏层的大小与词汇嵌入的大小分开。 这种分离使得在不显著增加词汇嵌入的参数大小的情况下更容易增加隐藏层大小。 第二种技术是跨层参数共享。 此技术可防止参数随网络深度而增长。 这两种技术都大大减少了BERT的参数数量,同时不严重影响性能,从而提高了参数效率。 与 BERT-large 配置相似的 ALBERT 的参数减少了 18 倍,而训练可以快 1.7 倍左右。 参数缩减技术还作为一种正规化形式,可以稳定训练并帮助泛化。
为了进一步提高 ALBERT 的性能,我们还引入了句子顺序预测 (SOP) 的自监督损失。 SOP主要侧重于句子间的连贯性,旨在解决在原来的 BERT 中提出的下一句预测(NSP)无效的问题(Yang 等人,2019;Liu 等人,2019)。
由于这些设计决策,我们能够扩展到更大的 ALBERT 配置,这些配置的参数仍比 BERT 少,但性能显著提高。 我们在著名的自然语言理解任务 GLUE、SQuAD 和 RACE 基准上建立了新的最先进的结果。 具体来说,我们将 RACE 准确率提高到 89.4%,GLUE 基准提高到 89.4,SQuAD 2.0 的 F1 分数提高到 92.2。
2相关工作
2.1扩展自然语言的表示学习
学习自然语言的表示已被证明对广泛的NLP任务有用,并被广泛采用(Mikolov et al., 2013; Le & Mikolov, 2014; Dai & Le, 2015; Peters et al., 2018; Devlin et al., 2019; Radford et al., 2018; 2019)。 过去两年最重要的变化之一是从预训练词嵌入,无论是标准词向量(Mikolov 等人,2013;Pennington 等人,2014)还是上下文词向量(McCann 等人,2017;Peters 等人,2018),到全网络预训练然后对特定任务进行微调(Dai 和 Le,2015;Radford 等人, 2018;Devlin 等人,2019)的转变。 在这些工作中,通常显示较大的模型可提高性能。 例如,Devlin 等人 (2019) 显示,在三个选定的自然语言理解任务中,使用更大的隐藏大小、更多的隐藏层和更多的注意力,总是能带来更好的性能。 但是,它们停留在隐藏大小 1024。 我们表明,在相同的设置下,将隐藏大小增加到 2048 会导致模型变差,从而降低性能。 因此,扩展自然语言的表示学习不像简单地增加模型大小那么容易。
此外,由于计算限制,特别是在 GPU/TPU 内存限制方面,很难对大型模型进行试验。 鉴于当前最先进的模型通常具有数亿甚至数十亿个参数,我们轻松就达到内存限制。 为了解决这个问题,Chen等人(2016年)提出了一种叫做梯度检查点的方法,以减少内存要求为亚线性的,而代价是额外的正向传递。 Gomez 等人(2017 年)提出了从下一层重建每一层激活的方法,以便它们不需要存储中间激活。 这两种方法都降低了内存消耗,但代价是速度。 相比之下,我们的参数缩减技术可减少内存消耗,提高训练速度。
2.2跨层参数共享
以前已经有人探讨了Transformer 架构(Vaswani 等人,2017 年)跨层共享参数的想法,但之前的工作侧重于标准编码解码器任务的训练,而不是预训练/微调设置。 与我们的观察结果不同,Dehghani等人(2018年)表明,具有跨层参数共享(Universal Transformer,UT)的网络在语言建模和主语-动词一致性方面比标准transformer具有更好的性能。 最近,Bai等人(2019年)提出了transformer网络深度均衡模型(DQE),并表明DQE可以达到一个平衡点,该均衡点使特定层的输入嵌入和输出嵌入保持不变。 我们的观察表明,我们的嵌入是振荡的,而不是收敛的。 Hao等人(2019年)将参数共享 transformer 与标准 transformer 相结合,进一步增加了标准 transformer 的参数数量。
2.3句子排序目标
ALBERT 使用基于预测两个连续文本段的顺序的预训练损失。 一些研究人员已经试验了与话语一致性类似的训练前目标。 对话语中的连贯性和内聚性已经有广泛的研究,发现许多连接相邻文本段的现象(Hobbs,1979;Halliday & Hasan, 1976;Grosz 等人,1995)。 实践中大多数有效的目标都很简单。 Skips(Kiros等人,2015年)和FastSent(Hill等人,2016年)句子嵌入是通过使用句子的编码来预测相邻句子中的单词而学习的。 句子嵌入学习的其他目标包括预测未来的句子,而不仅仅是邻居(Gan等人,2017年)和预测明确的话语标记(Jernite等人,2017年;Nie等人,2019年)。 我们的损失与Jernite等人(2017年)的句子排序目标最为相似,其中学习句子嵌入,以确定连续两个句子的顺序。 然而,与上述大多数工作不同,我们的损失是在文本片段而不是句子上定义的。 BERT(Devlin 等人,2019 年)使用的损失基于预测一个文本对中的第二个文本是否是另一个文档中的文本交换。 我们比较实验中的这种损失,发现句子排序是一项更具挑战性的预训练任务,对于某些下游任务更有用。 同时,Wang等人(2019年)也试图预测文本连续两段的顺序,但他们在三向分类任务中将其与原始的下一个句子预测相结合,而不是对两者进行比较。
3ALBERT 的组成
在本节中,我们将介绍 ALBERT 的设计决策,并提供与原始 BERT 体系结构的相应配置的量化比较(Devlin 等人,2019 年)。
3.1模型体系结构选择
ALBERT 架构的主干与 BERT 类似,使用具有 GELU(Hendrycks & Gimpel, 2016)非线性的 transformer 编码器(Vaswani et al., 2017)。 我们遵循 BERT 符号约定,将词汇嵌入的大小表示为 E,将编码器层数表示为 L,将隐藏层大小表示为 H。遵循 Devlin et al. (2019),我们将 feed-forward/filter 大小设置为 4H,并将 attention 的 head 数设置为 H/64。
ALBERT 对 BERT 的设计选择做出了三个主要贡献。
分解嵌入参数化。 在 BERT 中,以及随后的建模改进如 XLNet(Yang 等人,2019 年)和 RoBERTa(Liu等人,2019 年),WordPiece 嵌入大小 E 与隐藏层大小 H 相关联(即 E ≡ H)。由于建模和实际原因,此决策似乎不够理想,如下所示。
从建模的角度来看,WordPiece 嵌入旨在学习与上下文无关的表示,而隐藏层嵌入旨在学习上下文相关的表示。 正如上下文长度实验所表明的(Liu等人,2019年),类似BERT的表示的力量来自上下文的使用,为学习这种上下文相关的表示提供信号。 因此,将 WordPiece 嵌入大小 E 与隐藏图层大小 H 分开,使我们能够根据建模需求(这就要求 H ≫ E)更有效地使用总模型参数。
从实际角度来看,自然语言处理通常需要词汇量 V 很大。 如果 E ≡ H,则增加 H 会增加嵌入矩阵的大小,该矩阵的大小为 V × E。这很容易导致具有数十亿个参数的模型,其中大多数参数仅在训练期间进行稀疏更新。
因此,对于 ALBERT,我们使用嵌入参数的分解,将它们分解为两个较小的矩阵。 我们不是将 one-hot 向量直接投影到大小为 H 的隐藏空间,而是首先将它们投影到大小为 E 的低维嵌入空间中,然后将其投影到隐藏空间。 通过使用此分解,我们将嵌入参数从 O(V × H) 减少到 O(V × E + E × H)。 当 H ≫ E 时,此参数减少显著。我们选择对所有单词片段使用相同的 E,因为它们在文档中的分布比全词嵌入更均匀,其中嵌入大小不同对于不同的词语很重要(Grave et al. (2017); Baevski & Auli (2018); Dai et al. (2019))。
跨层参数共享。 对于ALBERT,我们建议跨层参数共享作为提高参数效率的另一种方法。 有多种方法可以共享参数,例如,仅跨层共享馈送网络 (FFN) 参数,或仅共享注意参数。 ALBERT 的默认决策是跨网络层共享所有参数。 除非另有说明,否则我们所有的实验都使用此默认决策,我们将此设计决策与第 4.5 节实验中的其他策略进行比较。
Dehghani等人(2018年)(Universal Transformer,UT)和Bai等人(2019年)(深度均衡模型,DQE)也探索了 Transformer 网络的类似策略。 与我们的观察不同,Dehghani等人(2018年)显示 UT 优于原生 Transformer。 Bai等人(2019年)表明,其DQEs达到一个平衡点,该均衡点中特定层的输入和输出嵌入保持不变。 我们对 L2 距离和余弦相似性的测量表明,我们的嵌入是振荡的,而不是收敛的。
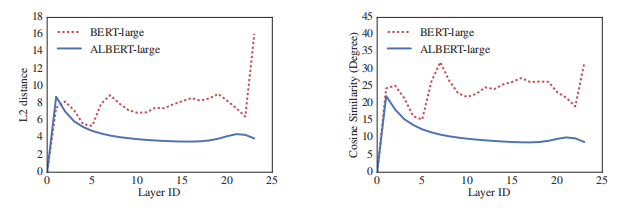
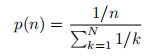
图2:对于 BERT-large 和 ALBERT-large,每个层的输入和输出嵌入的 L2 距离和余弦相似性(按度数计算)。
图 2 显示了使用 BERT-大和 ALBERT 大配置的每个层的输入和输出嵌入的 L2 距离和后弦相似性(参见表 2)。 我们观察到,对于 ALBERT 来说,从层到图层的过渡比 BERT 更平滑。 结果表明,权重分担对稳定网络参数有影响。 尽管与 BERT 相比,这两个指标都有下降,但它们即使在 24 层之后也不会收敛到 0。 这表明ALBERT参数的解空间与DQE找到的解空间大不相同。
句子间连贯性损失。 除了屏蔽语言模型 (MLM) 损失(Devlin 等人,2019 年)之外,BERT 还使用一个称为下一句预测 (NSP) 的损失。 NSP 是一个二元分类损失,用于预测原始文本中两个文本段是否连续出现,如下所示:通过从训练语料库中获取连续文本段创建正样本;通过将不同文档的文本段变成一对创建负样本;正样本和负样本采样概率相等。 NSP 目标旨在提高下游任务(如自然语言推理)的性能,这些任务需要推理句子对之间的关系。 然而,随后的研究(Yang 等人,2019年;Liu 等人,2019)发现 NSP 的影响不可靠,因此决定消除它,这一决策得到多个下游任务效果改进的支持。
我们推测,与 MLM 相比,NSP 无效的主要原因是它作为一项任务缺乏难度。 NSP 将主题预测和连贯性预测合并为一项任务。 但是,与连贯性预测相比,主题预测更易于学习,并且与使用 MLM 损失所学内容重叠更多。
我们认为,句子间建模是语言理解的一个重要方面,但我们提出主要基于连贯性的损失。 也就是说,对于 ALBERT,我们使用句子顺序预测 (SOP) 损失,它避免了主题预测,而是侧重于对句子间一致性建模。 SOP 损失的正样本使用与 BERT 相同的技术(同一文档中的两个连续文本段),负样本使用相同的两个连续文本段但交换它们的顺序。 这迫使模型学习关于话语级一致性属性的更精细的区别。 正如我们在第 4.6 节中显示的,事实证明 NSP 根本不解决 SOP 任务(即,它最终学习了更简单的主题预测信号,并在 SOP 任务上以随机基线级别执行),而 SOP 可以合理地解决 NSP 任务,大概基于对未对齐的一致性提示的分析。 因此,ALBERT 模型持续提高多句编码任务的下游任务性能。
3.2模型设置
在表 2 中,我们介绍了具有可比超参数设置的 BERT 和 ALBERT 模型之间的差异。 由于上面讨论的设计选择,ALBERT 模型的参数尺寸比相应的 BERT 模型要小得多。
| 模型 | 参数 | 层 | 隐藏 | 嵌入 | 参数共享 | |
| BERT | base | 108M | 12 | 768 | 768 | 假 |
| large | 334M | 24 | 1024 | 1024 | 假 | |
| xlarge | 1270M | 24 | 2048 | 2048 | 假 | |
| ALBERT | base | 12M | 12 | 768 | 128 | 真 |
| large | 18M | 24 | 1024 | 128 | 真 | |
| xlarge | 60M | 24 | 2048 | 128 | 真 | |
| xxlarge | 235M | 12 | 4096 | 128 | 真 | |
表2:本文分析的主要BERT和ALBERT模型的配置。
例如,ALBERT-large 的参数比 BERT-large 参数减少了约 18 倍,分别为 18M 和 334M。 如果我们将 BERT 设置为具有 H = 2048 的超大尺寸,则最终得到的模型具有 12.7 亿个参数且性能不足(图 1)。 相比之下,H = 2048 的 ALBERT-xlarge 配置只有 60M 参数,H = 4096 的 ALBERT-xxlarge 配置具有 233M 参数,即 BERT-large 参数的大约 70%。 请注意,对于 ALBERT-xxlarge,我们主要在 12 层网络上报告结果,因为 24 层网络(具有相同配置)获得类似的结果,但计算成本更高。
参数效率的提高是 ALBERT 设计选择的最重要优势。 在量化这一优势之前,我们需要更详细地介绍我们的实验设置。
4实验结果
4.1实验设置
为了保持尽可能有意义的比较,我们遵循 BERT(Devlin 等人,2019 年)设置,使用 BOOKCORPUS(Zhu 等人,2015 年)和英语维基百科(Devlin 等人,2019 年)用于预训练基线模型。 这两个语料由大约 16GB 的未压缩文本组成。 我们将输入格式化为"[CLS] x1 [SEP] x2 [SEP]",其中 x1 = x1,1, x1,2 · · · 和 x2 = x1,1, x1,2 · · · 是两个文本段。 我们总是将最大输入长度限制为 512,并随机生成小于 512 且概率为 10% 的输入序列。 与 BERT 一样,我们使用 30,000 的词汇大小,使用 SentencePiece(Kudo & Richardson,2018 )进行词符化,如 XLNet(Yang 等人,2019 年)。
我们使用 n-gram 掩蔽(Joshi 等人,2019 年)为 MLM 目标生成屏蔽输入,每个 n-gram 屏蔽的长度随机选择。 长度 n 的概率由
我们将 n-gram(即 n)的最大长度设置为 3(即 MLM 目标最多可以包含 3-gram 的完整单词,如"White House correspondents")。
所有模型更新都使用 4096 的批次大小和学习速率为 0.00176 的 LAMB 优化器(You 等人,2019 年)。 除非另有说明,我们对所有模型训练 125,000 步。 训练在 Cloud TPU V3 上进行。 用于训练的 TPU 数量从 64 到 1024 不等,具体取决于模型大小。
本节中描述的实验设置用于我们所有版本的 BERT 以及 ALBERT 模型,除非另有说明。
4.2评估参数
4.2.1内在评价
为了监控训练进度,我们使用与 4.1 节中相同的过程,基于 SQuAD 和 RACE 开发集创建一个开发集。 我们报告 MLM 和句子分类任务的准确率。 请注意,我们仅使用这个数据集检查模型是如何收敛;它不是用于模型选择等会影响下游任务性能的途径。
4.2.2下游评估
遵循 Yang 等人(2019)和 Liu 等人(2019),我们在三个流行的基准上评估我们的模型:一般语言理解评估(GLUE)基准(Wang 等人,2018)、斯坦福问答数据集(SQuAD;Rajpurkar 等人,2016;2018)和阅读理解考试(RACE)(Lai 等人,2017)。 为完整起见,我们在附录 A.1中 提供了这些基准的说明。 与 (Liu 等人, 2019) 中一样,我们对开发集执行早期停止,除了基于任务排行榜的最终比较之外,我们报告所有比较,同时报告测试集结果。
4.3BERT 和 ALBERT 的总体比较
现在,我们已准备好量化第 3 节中描述的设计选择的影响,特别是参数效率方面的选择。 参数效率的改进显示 ALBERT 设计选择的最重要优势,如表 3 所示:根据几个具有代表性的下游任务开发集的分数,在大约只有 BERT-large 参数的 70% 时,ALBERT-xxlarge 比 BERT-large 有显著改进:SQuAD v1.1(+1.9%)、SQuAD v2.0(+3.1%)、MNLI(+1.4%)、SST-2(+2.2%)以及 RACE(+8.4%)。
我们还观察到,在所有指标上,BERT-xlarge 的结果比 BERT-base 要差得多。 这表明像 BERT-xlarge 这样的模型比参数尺寸较小的模型更难训练。 另一个有趣的观察是,在相同的训练配置(相同数量的 TPU)下,训练时的数据吞吐量速度。 由于通信更少,计算更少,ALBERT 模型的数据吞吐量高于其相应的 BERT 模型。 最慢的是 BERT-xlarge 模型,我们用它作为基线。 随着模型变大,BERT 和 ALBERT 模型之间的差异会越来越大,例如,ALBERT-xlarge 的训练速度比 BERT-xlarge 快 2.4 倍。
| 模型 | 参数 | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg | 加速 | |
| BERT | base | 108M | 90.4/83.2 | 80.4/77.6 | 84.5 | 92.8 | 68.2 | 82.3 | 17.7 倍 |
| large | 334M | 92.2/85.5 | 85.0/82.2 | 86.6 | 93.0 | 73.9 | 85.2 | 3.8 倍 | |
| xlarge | 1270M | 86.4/78.1 | 75.5/72.6 | 81.6 | 90.7 | 54.3 | 76.6 | 1.0 | |
| ALBERT | base | 12M | 89.3/82.3 | 80.0/77.1 | 81.6 | 90.3 | 64.0 | 80.1 | 21.1 倍 |
| large | 18M | 90.6/83.9 | 82.3/79.4 | 83.5 | 91.7 | 68.5 | 82.4 | 6.5 倍 | |
| xlarge | 60M | 92.5/86.1 | 86.1/83.1 | 86.4 | 92.4 | 74.8 | 85.5 | 2.4 倍 | |
| xxlarge | 235M | 94.1/88.3 | 88.1/85.1 | 88.0 | 95.2 | 82.3 | 88.7 | 1.2 倍 | |
表 3:在 BOOKCORPUS 和维基百科上预训练 125k 步的模型在开发集上的结果。 在这里和其它地方,Avg 列是通过对其左边的下游任务的平均分来计算的(SQuAD 的每个 F1 和 EM 两个数字先取平均分)。
接下来,我们进行细分实验,量化 ALBERT 的每个设计选项的贡献。
4.4分解嵌入参数化
表 4 显示使用 ALBERT-base 配置设置(见表 2),使用同一组具有代表性的下游任务,改变词汇嵌入大小 E 的效果。 在非共享条件 (BERT 风格)下,较大的嵌入大小可以提供更好的性能,但不会增加太多。 在全共享条件(ALBERT 风格)下,大小 128 的嵌入似乎是最好的。 基于这些结果,我们在以后的所有设置中使用嵌入大小 E = 128,作为进一步扩展的必要步骤。
| 模型 | E | 参数 | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg | |
| ALBERT | 64 | 87M | 89.9/82.9 | 80.1/77.8 | 82.9 | 91.5 | 66.7 | 81.3 | |
| base | 128 | 89M | 89.9/82.8 | 80.3/77.3 | 83.7 | 91.5 | 67.9 | 81.7 | |
| not-shared | 256 | 93M | 90.2/83.2 | 80.3/77.4 | 84.1 | 91.9 | 67.3 | 81.8 | |
| 768 | 108M | 90.4/83.2 | 80.4/77.6 | 84.5 | 92.8 | 68.2 | 82.3 | ||
| ALBERT | 64 | 10M | 88.7/81.4 | 77.5/74.8 | 80.8 | 89.4 | 63.5 | 79.0 | |
| base | 128 | 12M | 89.3/82.3 | 80.0/77.1 | 81.6 | 90.3 | 64.0 | 80.1 | |
| all-shared | 256 | 16M | 88.8/81.5 | 79.1/76.3 | 81.5 | 90.3 | 63.4 | 79.6 | |
| 768 | 31M | 88.6/81.5 | 79.2/76.6 | 82.0 | 90.6 | 63.3 | 79.8 |
表4:词汇嵌入大小对 ALBERT-base 性能的影响。
4.5跨层参数共享
表 5 展示使用具有两个嵌入大小(E = 768 和 E = 128)的 ALBERT-base 配置(表 2)的各种跨层参数共享策略的实验。 我们比较全共享策略(ALBERT 风格)、非共享策略(BERT 风格)和中间策略,中间策略仅共享 attention 参数(但不共享 FNN 参数)或仅共享 FFN 参数(而不共享 attention 参数)。
全共享策略在这两种情况下都会影响性能,但与 E = 768(Avg 减小 2.5)相比,E = 128(Avg 减小 1.5)的严重程度较低。 此外,大多数性能下降似乎来自共享 FFN 层参数,而共享注意参数在 E = 128 时不会下降(在平均时为 0.1),当 E = 768(平均为 -0.7)时,性能下降不会下降。
还有其他共享参数跨层的策略。 例如,我们可以将 L 图层划分为大小 M 的 N 组,并且每个大小-M 组共享参数。 总体而言,我们的实验结果表明,组大小 M 越小,我们获得的性能越好。 但是,减小组大小 M 也会显著增加总体参数的数量。 我们选择全共享策略作为我们的默认选择。
| 模型 | 参数 | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg | |
| ALBERT | all-shared | 31M | 88.6/81.5 | 79.2/76.6 | 82.0 | 90.6 | 63.3 | 79.8 |
| base | shared-attention | 83M | 89.9/82.7 | 80.0/77.2 | 84.0 | 91.4 | 67.7 | 81.6 |
| E=768 | shared-FFN | 57M | 89.2/82.1 | 78.2/75.4 | 81.5 | 90.8 | 62.6 | 79.5 |
| not-shared | 108M | 90.4/83.2 | 80.4/77.6 | 84.5 | 92.8 | 68.2 | 82.3 | |
| ALBERT | all-shared | 12M | 89.3/82.3 | 80.0/77.1 | 82.0 | 90.3 | 64.0 | 80.1 |
| base | shared-attention | 64M | 89.9/82.8 | 80.7/77.9 | 83.4 | 91.9 | 67.6 | 81.7 |
| E=128 | shared-FFN | 38M | 88.9/81.6 | 78.6/75.6 | 82.3 | 91.7 | 64.4 | 80.2 |
| not-shared | 89M | 89.9/82.8 | 80.3/77.3 | 83.2 | 91.5 | 67.9 | 81.6 | |
表5:跨层参数共享策略的影响,ALBERT-base 的配置。
4.6句子预测 (SOP)
我们使用 ALBERT-base 配置,对额外的句间损失的三种实验条件进行了 head-to-head 的比较:无(XLNet 和 RoBERTa 风格)、NSP(BERT 风格)和 SOP(ALBERT 风格)。 结果显示在表 6 中,包括内部(MLM、NSP 和 SOP 任务的准确性)和下游任务。
| 内在任务 | 下游任务 | ||||||||
| SP 任务 | MLM | Nsp | Sop | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg |
| None | 54.9 | 52.4 | 53.3 | 88.6/81.5 | 78.1/75.3 | 81.5 | 89.9 | 61.7 | 79.0 |
| Nsp | 54.5 | 90.5 | 52.0 | 88.4/81.5 | 77.2/74.6 | 81.6 | 91.1 | 62.3 | 79.2 |
| Sop | 54.0 | 78.9 | 86.5 | 89.3/82.3 | 80.0/77.1 | 82.0 | 90.3 | 64.0 | 80.1 |
表6:句子预测损失、NSP与SOP对内在和下游任务的影响。
内在任务的结果显示,NSP 损失没有给 SOP 任务带来任何判别力(准确率为 52.0%,与 "None"条件下的随机猜测表现相似)。 这使我们能够得出结论,NSP最终只建模主题转移。 相比之下,SOP 损失确实较好地解决了 NSP 任务(78.9% 的准确率),而 SOP 任务甚至更好(86.5% 的准确率)。 更重要的是,在多句子编码任务中,SOP 损失似乎持续改善了下游任务的性能(SQuAD 1.1 约 +1%,SQuAD 2.0 约 +2%,RACE 约 +1.7%),Avg score 改善约 +1%。
4.7网络深度和宽度的影响
在本节中,我们将检查深度(网络层数)和宽度(隐藏大小)如何影响 ALBERT 的性能。 表 7 显示了使用不同数量的网络层数的 ALBERT-large 配置的性能(参见表 2)。 具有 3 个或更多图层的网络通过使用之前深度的参数进行微调(例如,从 6 层网络参数的检查点对 12 层网络参数进行微调)。 类似的技术也被用于Gong等人(2019年)。 如果我们将 3 层 ALBERT 模型与 1 层 ALBERT 模型进行比较,尽管它们具有相同的参数数,但性能会显著提高。 但是,当继续增加图层数量时,回报会逐渐减少:12 层网络的结果与 24 层网络的结果相对接近,48 层网络的性能似乎有所下降。
| 层数 | 参数 | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg |
| 1 | 18M | 31.1/22.9 | 50.1/50.1 | 66.4 | 80.8 | 40.1 | 52.9 |
| 3 | 18M | 79.8/69.7 | 64.4/61.7 | 77.7 | 86.7 | 54.0 | 71.2 |
| 6 | 18M | 86.4/78.4 | 73.8/71.1 | 81.2 | 88.9 | 60.9 | 77.2 |
| 12 | 18M | 89.8/83.3 | 80.7/77.9 | 83.3 | 91.7 | 66.7 | 81.5 |
| 24 | 18M | 90.3/83.3 | 81.8/79.0 | 83.3 | 91.5 | 68.7 | 82.1 |
| 48 | 18M | 90.0/83.1 | 81.8/78.9 | 83.4 | 91.9 | 66.9 | 81.8 |
表 7:增加 ALBERT-large 网络层数的效果。
在表 8 中可以看到类似的现象(这次是宽度),用于 3 层 ALBERT-large 配置。 随着隐藏大小的增加,随着回报的递减,性能会提高。 在隐藏大小 6144 时,性能似乎显著下降。 我们注意到,这些模型似乎都没有一个过拟合训练数据,与表现最好的 ALBERT 配置相比,它们都有更高的训练集和验证集损失。
| 隐藏层大小 | 参数 | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg |
| 1024 | 18M | 79.8/69.7 | 64.4/61.7 | 77.7 | 86.7 | 54.0 | 71.2 |
| 2048 | 60M | 83.3/74.1 | 69.1/66.6 | 79.7 | 88.6 | 58.2 | 74.6 |
| 4096 | 225M | 85.0/76.4 | 71.0/68.1 | 80.3 | 90.4 | 60.4 | 76.3 |
| 6144 | 499M | 84.7/75.8 | 67.8/65.4 | 78.1 | 89.1 | 56.0 | 74.0 |
表 8:增加 ALBERT-large 3-层 隐藏层大小的效果。
4.8如果我们训练的时间相同会怎么样?
表 3 中的加速结果表明,与 ALBERT-xxlarge 相比,BERT 大的数据吞吐量高出约 3.17 倍。 由于较长的训练通常会导致更好的性能,因此我们执行比较,其中,我们控制实际训练时间(即让模型训练相同的小时数),而不是控制数据吞吐量(训练步骤数)。 在表 9 中,我们比较了 BERT-large 模型在 400k 训练步骤(经过 34 小时训练后)后的性能,大致相当于使用 125k 训练步骤(32 小时训练)训练 ALBERT-xxlarge 模型所需的时间。
训练大致相同的时间后,ALBERT-xxlarge 明显优于 BERT-large:平均值提高 1.5%,RACE 的差异高达 +5.2%。
| 模型 | 步数 | 时间 | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg |
| BERT-large | 400k | 34h | 93.5/87.4 | 86.9/84.3 | 87.8 | 94.6 | 77.3 | 87.2 |
| ALBERT-xxlarge | 125k | 32h | 94.0/88.1 | 88.3/85.3 | 87.8 | 95.4 | 82.5 | 88.7 |
表 9:控制训练时间的效果,BERT-large 与 ALBERT-xxlarge 的配置对比。
4.9非常宽的 ALBERT 模型同样需要更深?
在 4.7 节中,我们显示对于 ALBERT-large(H=1024), 12 层和 24 层配置之间的差异很小。 对于更宽的 ALBERT 配置(如 ALBERT-xxlarge (H=4096)),此结果是否仍然存在?
| 层数 | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg |
| 12 | 94.0/88.1 | 88.3/85.3 | 87.8 | 95.4 | 82.5 | 88.7 |
| 24 | 94.1/88.3 | 88.1/85.1 | 88.0 | 95.2 | 82.3 | 88.7 |
表 10:使用 ALBERT-xxlarge 配置进行深层网络的影响。
答案由表10的结果给出。 12 层和 24 层 ALBERT-xxlarge 配置在下游精度方面的差异可以忽略不计,平均分数相同。 我们的结论是,在共享所有跨层参数(ALBERT 样式)时,不需要比 12 层配置更深的模型。
4.10额外的训练数据和丢弃效果
到此时间所做的实验仅使用维基百科和BOOKCORPUS数据集,如(Devlin等人,2019年)。 在本节中,我们将报告 XLNet(Yang 等人,2019 年)和 RoBERTa(Liu 等人,2019 年)使用的其他数据的影响的测量。
图 3a 在两种条件下绘制了 dev 集 MLM 精度,无需附加数据,后一种情况可显著提升。 我们还在表 11 中观察到下游任务的性能改进,但 SQuAD 基准测试除外(这些基准基于维基百科,因此受到域外培训材料的负面影响)。
图 3:在训练期间添加数据和删除丢弃的效果。
| SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg | |
| 无其他数据 | 89.3/82.3 | 80.0/77.1 | 81.6 | 90.3 | 64.0 | 80.1 |
| 具有其他数据 | 88.8/81.7 | 79.1/76.3 | 82.4 | 92.8 | 66.0 | 80.8 |
表 11:使用 ALBERT 基础配置的其他训练数据的效果。
我们还注意到,即使经过 1M 步骤的训练,我们最大的模型仍然不能与它们的训练数据过度拟合。 因此,我们决定删除丢弃,以进一步提高我们的模型容量。 图 3b 中的图示表明,去除丢弃可显著提高 MLM 的准确性。 在 1M 左右训练步骤(表 12)对 ALBERT-xxlarge 进行中间评估也证实,删除丢弃有助于下游任务。 有经验(Szegedy等人,2017年)和理论(Li等人,2019年)证据表明,卷积神经网络中的批量规范化和辍学的组合可能有有害结果。 据我们所知,我们率先证明,丢弃会损害大型基于 Transformer 模型的性能。 然而,ALBERT 的基础网络结构是 transformer 的一个特例,需要进一步的实验,看看这种现象是否出现在其他基于 transformer 的体系结构中。
| SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE | Avg | |
| With dropout | 94.7/89.2 | 89.6/86.9 | 90.0 | 96.3 | 85.7 | 90.4 |
| Without dropout | 94.8/89.5 | 89.9/87.2 | 90.4 | 96.5 | 86.1 | 90.7 |
表 12:删除 dropout 的效果,用 ALBERT-xxlarge 的配置测量。
4.11当前 NLU 任务的最先进结果
我们在本节中报告的结果使用了 Devlin 等人(2019 年)使用的训练数据,以及 Liu 等人(2019 年)和 Yang 等人(2019 年)使用的额外数据。 我们在两种微调设置下报告最先进的结果:单模型和融合。 在这两种设置中,我们只执行单任务微调。 继刘等人(2019年)之后,在开发集上,我们报告五次运行中值结果。
单模型 ALBERT 配置包含所讨论的性能最佳的设置:使用组合 MLM 和 SOP 损耗的 ALBERT-xxlarge 配置(表 2),并且没有丢弃。 根据开发集性能选择有助于最终组合模型的检查点;考虑此选择的检查点数范围为 6 到 17,具体取决于任务。 对于 GLUE(表 13)和 RACE(表 14)基准,我们平均为组合模型的模型预测进行平均调整,其中候选模型使用不同的训练步骤使用 12 层和 24 层体系结构进行微调。 对于 SQuAD(表 14),我们平均为具有多个概率的跨度的预测分数;我们还对"无法回答"决定的分数进行平均。
单模型和合奏结果表明,ALBERT 显著改善了所有三个基准的最先进的技术,达到 GLUE 分数 89.4,SQuAD 2.0 测试 F1 分数为 92.2,RACE 测试精度为 89.4。 后者似乎特别有进步,比BERT(Devlin等人,2019年)上升了17.4%,比XLNet(Yang等人,2019年)上升了7.6%,比RoBERTa(Liu等人,2019年)上升了6.2%,比DCMI+(张等人,2019年)上升了5.3%。"2019年"是一个多重组合专为阅读理解任务设计的模型。 我们的单一模型的精度达到 86.5%,仍比最先进的融合模型高出 2.4%。
| 模型 | MNLI | QNLI | QQP | RTE | SST | MRPC | CoLA | STS | WNLI | Avg |
| 在验证集上的单任务单一模型 | ||||||||||
| BERT-large | 86.6 | 92.3 | 91.3 | 70.4 | 93.2 | 88.0 | 60.6 | 90.0 | - | - |
| XLNet-large | 89.8 | 93.9 | 91.8 | 83.8 | 95.6 | 89.2 | 63.6 | 91.8 | - | - |
| RoBERTa-large | 90.2 | 94.7 | 92.2 | 86.6 | 96.4 | 90.9 | 68.0 | 92.4 | - | - |
| ALBERT (1M) | 90.4 | 95.2 | 92.0 | 88.1 | 96.8 | 90.2 | 68.7 | 92.7 | - | - |
| ALBERT (1.5M) | 90.8 | 95.3 | 92.2 | 89.2 | 96.9 | 90.9 | 71.4 | 93.0 | - | - |
| 测试集上融合(截至 2019 年 9 月 16 日排行榜) | ||||||||||
| ALICE | 88.2 | 95.7 | 90.7 | 83.5 | 95.2 | 92.6 | 69.2 | 91.1 | 80.8 | 87.0 |
| MT-DNN | 87.9 | 96.0 | 89.9 | 86.3 | 96.5 | 92.7 | 68.4 | 91.1 | 89.0 | 87.6 |
| XLNet | 90.2 | 98.6 | 90.3 | 86.3 | 96.8 | 93.0 | 67.8 | 91.6 | 90.4 | 88.4 |
| RoBERTa | 90.8 | 98.9 | 90.2 | 88.2 | 96.7 | 92.3 | 67.8 | 92.2 | 89.0 | 88.5 |
| Adv-RoBERTa | 91.1 | 98.8 | 90.3 | 88.7 | 96.8 | 93.1 | 68.0 | 92.4 | 89.0 | 88.8 |
| ALBERT | 91.3 | 99.2 | 90.5 | 89.2 | 97.1 | 93.4 | 69.1 | 92.5 | 91.8 | 89.4 |
表13:GLUE基准的最先进的结果。 对于单任务单模型结果,我们以 1M 步(与 RoBERTa 相当)和 1.5M 步报告 ALBERT。 ALBERT 融合使用经过 1M、1.5M 和其它数量步骤训练的模型。
| 模型 | SQuAD1.1 开发集 | SQuAD2.0 开发集 | SQuAD2.0 测试集 | RACE 测试集(初/高) |
| 单个模型(截至2019年9月23日排行榜) | ||||
| BERT-large | 90.9/84.1 | 81.8/79.0 | 89.1/86.3 | 72.0 (76.6/70.1) |
| XLNet | 94.5/89.0 | 88.8/86.1 | 89.1/86.3 | 81.8 (85.5/80.2) |
| RoBERTa | 94.6/88.9 | 89.4/86.5 | 89.8/86.8 | 83.2 (86.5/81.3) |
| UPM | - | - | 89.9/87.2 | - |
| XLNet + SG-Net Verifier++ | - | - | 90.1/87.2 | - |
| ALBERT (1M) | 94.8/89.2 | 89.9/87.2 | - | 86.0 (88.2/85.1) |
| ALBERT (1.5M) | 94.8/89.3 | 90.2/87.4 | 90.9/88.1 | 86.5 (89.0/85.5) |
| 单个模型(截至2019年9月23日排行榜) | ||||
| BERT-large | 92.2/86.2 | - | - | - |
| XLNet + SG-Net Verifier | - | - | 90.7/88.2 | - |
| UPM | - | - | 90.7/88.2 | |
| XLNet + DAAF + Verifier | - | - | 90.9/88.6 | - |
| DCMN+ | - | - | - | 84.1 (88.5/82.3) |
| ALBERT | 95.5/90.1 | 91.4/88.9 | 92.2/89.7 | 89.4 (91.2/88.6) |
表14:关于SQuAD和RACE基准的最先进的结果。
5讨论
虽然 ALBERT-xxlarge 的参数比 BERT-large 的参数少并且得到明显更好的结果,但由于其结构较大,计算成本更高。 因此,下一个重要的步骤是通过 sparse attention(Child 等人,2019)和 block attention(Shen 等人,2018年)等方法,加快 ALBERT 的训练和推理速度。 垂直领域的研究路线可能提供额外的表示能力,包括 hard 样本挖掘(Mikolov 等人,2013年)和更有效的语言模型训练(Yang 等人,2019)。 此外,尽管我们有令人信服的证据表明,句子顺序预测是一个让连续性更有用处的学习任务,可以导致更好的语言表示,但我们假设可能有更多的维度还没有被当前的自我监督训练损失所捕获,这些维度可能会对当前的表示创造额外的表示能力。
致谢
作者感谢 Beer Changpinyo、Nan Ding 和 Tomer Levinboim 对该项目的讨论和提供有用的反馈;Omer Levy 和Naman Goyal 阐明 RoBERTa 实验的设置;Zihang Dai 阐明 XLNet 实验;Brandon Norick、Emma Strubell 和 Sachin Mehta 为论文提供了有用的反馈。 感谢 Liang Xu 和中国 GLUE 社区发布中文版的 ALBERT 模型。
参考文献
Alexei Baevski and Michael Auli. Adaptive input representations for neural language modeling. arXiv preprint arXiv:1809.10853, 2018.
Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. Deep equilibrium models. In Neural Information Processing Systems (NeurIPS), 2019.
Roy Bar-Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. The second PASCAL recognising textual entailment challenge. In Proceedings of the second PASCAL challenges workshop on recognising textual entailment, volume 6, pp. 6–4. Venice, 2006.
Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. The fifth PASCAL recognizing textual entailment challenge. In TAC, 2009.
Daniel Cer, Mona Diab, Eneko Agirre, I˜nigo Lopez-Gazpio, and Lucia Specia. SemEval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pp. 1–14, Vancouver, Canada, August 2017. Association for Computational Linguistics. doi: 10.18653/v1/S17-2001. URL https://www.aclweb.org/anthology/S17-2001.
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016.
Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019.
Ido Dagan, Oren Glickman, and Bernardo Magnini. The PASCAL recognising textual entailment challenge. In Machine Learning Challenges Workshop, pp. 177–190. Springer, 2005.
Andrew M Dai and Quoc V Le. Semi-supervised sequence learning. In Advances in neural information processing systems, pp. 3079–3087, 2015.
Zihang Dai, Zhilin Yang, Yiming Yang, William W Cohen, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. arXiv preprint arXiv:1807.03819, 2018.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1423. URL https: //www.aclweb.org/anthology/N19-1423.
William B. Dolan and Chris Brockett. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005), 2005. URL https://www.aclweb.org/anthology/I05-5002.
Zhe Gan, Yunchen Pu, Ricardo Henao, Chunyuan Li, Xiaodong He, and Lawrence Carin. Learning generic sentence representations using convolutional neural networks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 2390–2400, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/D17-1254. URL https://www.aclweb.org/anthology/D17-1254.
Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. The third PASCAL recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, pp. 1–9, Prague, June 2007. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/W07-1401.
Aidan N Gomez, Mengye Ren, Raquel Urtasun, and Roger B Grosse. The reversible residual network: Backpropagation without storing activations. In Advances in neural information processing systems, pp. 2214–2224, 2017.
Linyuan Gong, Di He, Zhuohan Li, Tao Qin, Liwei Wang, and Tieyan Liu. Efficient training of bert by progressively stacking. In International Conference on Machine Learning, pp. 2337–2346, 2019.
Edouard Grave, Armand Joulin, Moustapha Ciss´e, Herv´e J´egou, et al. Efficient softmax approximation for gpus. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pp. 1302–1310. JMLR. org, 2017.
Barbara J. Grosz, Aravind K. Joshi, and Scott Weinstein. Centering: A framework for modeling the local coherence of discourse. Computational Linguistics, 21(2):203–225, 1995. URL https: //www.aclweb.org/anthology/J95-2003.
M.A.K. Halliday and Ruqaiya Hasan. Cohesion in English. Routledge, 1976.
Jie Hao, Xing Wang, Baosong Yang, Longyue Wang, Jinfeng Zhang, and Zhaopeng Tu. Modeling recurrence for transformer. Proceedings of the 2019 Conference of the North, 2019. doi: 10. 18653/v1/n19-1122. URL http://dx.doi.org/10.18653/v1/n19-1122.
Dan Hendrycks and Kevin Gimpel. Gaussian Error Linear Units (GELUs). arXiv preprint arXiv:1606.08415, 2016.
Felix Hill, Kyunghyun Cho, and Anna Korhonen. Learning distributed representations of sentences from unlabelled data. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1367–1377. Association for Computational Linguistics, 2016. doi: 10.18653/v1/N16-1162. URL http: //aclweb.org/anthology/N16-1162.
Jerry R. Hobbs. Coherence and coreference. Cognitive Science, 3(1):67–90, 1979.
Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification. arXiv preprint arXiv:1801.06146, 2018.
Shankar Iyer, Nikhil Dandekar, and Kornl Csernai. First quora dataset release: Question pairs, January 2017. URL https://www.quora.com/q/quoradata/ First-Quora-Dataset-Release-Question-Pairs.
Yacine Jernite, Samuel R Bowman, and David Sontag. Discourse-based objectives for fast unsupervised sentence representation learning. arXiv preprint arXiv:1705.00557, 2017.
Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. SpanBERT: Improving pre-training by representing and predicting spans. arXiv preprint arXiv:1907.10529, 2019.
Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel, Antonio Torralba, Raquel Urtasun, and Sanja Fidler. Skip-thought vectors. In Proceedings of the 28th International Conference on Neural Information Processing Systems Volume 2, NIPS’15, pp. 3294–3302, Cambridge, MA, USA, 2015. MIT Press. URL http://dl.acm.org/citation.cfm?id= 2969442.2969607.
Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 66–71, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-2012. URL https://www.aclweb.org/anthology/D18-2012.
Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 785–794, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/D17-1082. URL https://www. aclweb.org/anthology/D17-1082.
Quoc Le and Tomas Mikolov. Distributed representations of sentences and documents. In Proceedings of the 31st ICML, Beijing, China, 2014.
Hector Levesque, Ernest Davis, and Leora Morgenstern. The Winograd schema challenge. In Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning, 2012.
Xiang Li, Shuo Chen, Xiaolin Hu, and Jian Yang. Understanding the disharmony between dropout and batch normalization by variance shift. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2682–2690, 2019.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. Learned in translation: Contextualized word vectors. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems 30, pp. 6294–6305. Curran Associates, Inc., 2017. URL http://papers.nips.cc/paper/ 7209-learned-in-translation-contextualized-word-vectors.pdf.
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pp. 3111–3119, 2013.
Allen Nie, Erin Bennett, and Noah Goodman. DisSent: Learning sentence representations from explicit discourse relations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 4497–4510, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1442. URL https://www.aclweb.org/anthology/ P19-1442.
Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532–1543, Doha, Qatar, October 2014. Association for Computational Linguistics. doi: 10.3115/v1/D14-1162. URL https://www.aclweb.org/anthology/ D14-1162.
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 2227–2237, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. doi: 10.18653/v1/N18-1202. URL https://www.aclweb.org/anthology/N18-1202.
Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf, 2018.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 2019.
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2383–2392, Austin, Texas, November 2016. Association for Computational Linguistics. doi: 10.18653/v1/D16-1264. URL https://www.aclweb. org/anthology/D16-1264.
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 784–789, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-2124. URL https://www.aclweb. org/anthology/P18-2124.
Tao Shen, Tianyi Zhou, Guodong Long, Jing Jiang, and Chengqi Zhang. Bi-directional block selfattention for fast and memory-efficient sequence modeling. arXiv preprint arXiv:1804.00857, 2018.
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism, 2019.
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pp. 1631–1642, Seattle, Washington, USA, October 2013. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/D13-1170.
Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. Patient knowledge distillation for BERT model compression. arXiv preprint arXiv:1908.09355, 2019.
Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander A Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
Iulia Turc, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Well-read students learn better: The impact of student initialization on knowledge distillation. arXiv preprint arXiv:1908.08962, 2019.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, pp. 5998–6008, 2017.
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 353–355, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/W18-5446. URL https://www.aclweb.org/anthology/ W18-5446.
Wei Wang, Bin Bi, Ming Yan, Chen Wu, Zuyi Bao, Liwei Peng, and Luo Si. StructBERT: Incorporating language structures into pre-training for deep language understanding. arXiv preprint arXiv:1908.04577, 2019.
Alex Warstadt, Amanpreet Singh, and Samuel R Bowman. Neural network acceptability judgments. arXiv preprint arXiv:1805.12471, 2018.
Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 1112–1122, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. doi: 10.18653/v1/N18-1101. URL https://www.aclweb. org/anthology/N18-1101.
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V Le. XLNet: Generalized autoregressive pretraining for language understanding. arXiv preprint arXiv:1906.08237, 2019.
Yang You, Jing Li, Jonathan Hseu, Xiaodan Song, James Demmel, and Cho-Jui Hsieh. Reducing BERT pre-training time from 3 days to 76 minutes. arXiv preprint arXiv:1904.00962, 2019.
Shuailiang Zhang, Hai Zhao, Yuwei Wu, Zhuosheng Zhang, Xi Zhou, and Xiang Zhou. DCMN+: Dual co-matching network for multi-choice reading comprehension. arXiv preprint arXiv:1908.11511, 2019.
Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE international conference on computer vision, pp. 19–27, 2015.
附录
A.1下游的评估任务
GLUE GLUE 由 9 项任务组成,即Corpus of Linguistic Acceptability(CoLA;Warstadt 等人,2018)、Stanford Sentiment Treebank(SST;Socher 等人,2013)、Microsoft Research Paraphrase Corpus(MRPC;Dolan & Brockett,2005)、Semantic Textual Similarity Benchmark(STS;Cer 等人,2017)、Quora Question Pairs(QQP;Iyer 等人,2017年),Multi-Genre NLI(MNLI;Williams 等人,2018年)、Question NLI(QNLI;Rajpurkar 等人,2016年),Recognizing Textual Entailment(RTE;Dagan 等人,2005;Bar-Haim 等人,2006;Giampiccolo 等人,2007;Bentivogli 等人,2009)和 Winograd NLI(WNLI;Levesque 等人,2012)。 它侧重于评估模型自然语言理解的能力。 报告 MNLI 结果时,我们只报告"匹配"条件 (MNLI-m)。 我们遵循以前工作的微调过程(Devlin 等人,2019;Liu 等人,2019;Yang 等人,2019),并报告从 GLUE 提交中获得的测试集性能。 对于测试集的提交结果,我们执行如 Liu 等人(2019 )和 Yang 等人(2019)所述的针对 WNLI 和 QNLI 任务的修改。
SQuAD SQuAD 是一个从维基百科构建的提取问题回答的数据集。 答案是来自上下文段落的文本段,任务是预测答案的范围。 我们在两个版本的 SQuAD 上评估我们的模型:v1.1 和 v2.0。 SQuAD v1.1 具有 100,000 个人工标注的问题/答案对。 SQuAD v2.0 额外引入 50,000 个没有答案的问题。 对于 SQuAD v1.1,我们使用与 BERT 相同的训练过程,而对于 SQuAD v2.0,模型联合训练提取范围的损失和一个预测可回答性的分类器(Yang 等人,2019;Liu 等人,2019)。 我们报告开发集和测试集的性能。
RACE RACE 是一个用于多选阅读理解的大型数据集,从中国英语考试中收集,有近 100,000 个问题。 RACE 中的每个样本都有 4 个候选答案。 遵循此前的工作(Yang 等人,2019;Liu 等人,2019),我们将段落、问题和每个候选答案连接起来作为模型的输入。 然后,我们使用"[CLS]"词符的表示来预测每个答案的概率。 数据集由两个领域组成:初中和高中。 我们在这两个领域训练模型,并报告开发集和测试集的准确率。
A.2超参数
下游任务的超参数如表 15 所示。 我们采用的参数来自 Liu 等人,(2019);Devlin 等人(2019) 和 Yang 等人(2019)。
| LR | BSZ | ALBERT DR | Classifier DR | TS | WS | MSL | |
| CoLA | 1.00E-05 | 16 | 0 | 0.1 | 5336 | 320 | 512 |
| Sts | 2.00E-05 | 16 | 0 | 0.1 | 3598 | 214 | 512 |
| SST-2 | 1.00E-05 | 32 | 0 | 0.1 | 20935 | 1256 | 512 |
| MNLI | 3.00E-05 | 128 | 0 | 0.1 | 10000 | 1000 | 512 |
| QNLI | 1.00E-05 | 32 | 0 | 0.1 | 33112 | 1986 | 512 |
| QQP | 5.00E-05 | 128 | 0.1 | 0.1 | 14000 | 1000 | 512 |
| RTE | 3.00E-05 | 32 | 0.1 | 0.1 | 800 | 200 | 512 |
| MRPC | 2.00E-05 | 32 | 0 | 0.1 | 800 | 200 | 512 |
| WNLI | 2.00E-05 | 16 | 0.1 | 0.1 | 2000 | 250 | 512 |
| SQuAD v1.1 | 5.00E-05 | 48 | 0 | 0.1 | 3649 | 365 | 384 |
| SQuAD v2.0 | 3.00E-05 | 48 | 0 | 0.1 | 8144 | 814 | 512 |
| RACE | 2.00E-05 | 32 | 0.1 | 0.1 | 12000 | 1000 | 512 |
表 15:下游任务中的 ALBERT 超参数。 LR:学习率。 BSZ:批次大小。 DR:丢弃率。 TS:训练步数。 WS:预热步数。 MSL:最大序列长度。