BLEU:一种自动评估机器翻译的方法
摘要
1 介绍
1.1 理由
人工评估机器翻译(MT)会权衡翻译的许多方面,包括翻译的充分性、保真度和流畅度(Hovy, 1999; White and O’Connell, 1994)。 Reeder(2001)给出了MT评估技术及其丰富文献的综合目录。 在大多数情况下,这些不同的人工评估方法相当昂贵(Hovy,1999)。 此外,它们可能要花费数周或数月 来完成。 这是一个很大的问题,因为机器翻译系统的开发人员需要监控每天 的更改对系统的影响,以便区分好的想法和糟糕的想法。 我们认为,MT的进展将来自评估的改进,并且等待从评估瓶颈中释放的富有成果的研究思路已陷入僵局。 开发人员将受益于一种廉价的自动评估,这种评估快速、独立于语言,并与人工评估高度关联。 我们在本文中提出这样一种评估方法。
1.2 观点
如何衡量翻译的好坏? 机器翻译越接近专业的人工翻译,它就越好。 这是我们的提议背后的核心理念。 为了判断机器翻译的质量,可以根据一个数值指标来衡量其与一个或多个人工参考翻译的接近程度。 因此,我们的MT评估系统需要两个成分:
1. 一个“翻译接近度”数值指标
2. 一个高质量的人工参考翻译语料库
我们的接近度指标仿造语音识别社区使用非常成功的单词错误率,并针对多个参考翻译进行适当修改以允许单词选择和单词顺序序的合理差异。 它的主要思想是使用与参考翻译匹配的可变长度短语的加权平均值。 这个观点使得可以利用各种加权方案产生一系列指标。 我们从这个系列中选择一个很有价值的基准指标。 在第2节中,我们详细描述这个基准指标。 在第3节中,我们评估BLEU的性能。 在第4节中,我们描述一个人工评估实验。 在第5节中,我们将基准指标性能与人工评估进行比较。
2 基准BLEU指标
通常,给定源语句有许多“完美”的翻译。 这些翻译的单词选择可能不同,或者即使它们使用相同的单词但单词顺序也可能不同。 然而,人类可以清楚地区分好的翻译和坏翻译。 例如,考虑这两个对一条中文源语句的候选翻译:
例1
候选翻译1: It is a guide to action which ensures that the military always obeys the commands of the party.
候选翻译2: It is to insure the troops forever hearing the activity guidebook that party direct.
虽然它们似乎是在同一主题上,但它们的质量明显不同。 为了比较,下面我们提供同一语句的三个参考人类翻译。
参考翻译1: It is a guide to action that ensures that the military will forever heed Party commands.
参考翻译2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
参考翻译3: It is the practical guide for the army always to heed the directions of the party.
很明显,好的候选翻译1与这三个参考译文共享许多单词和短语,而候选翻译2则没有。 我们将在第2.1节中简要地量化这种共享概念。 但首先要注意候选翻译1与参考翻译1共享"It is a guide to action",与参考翻译2共享"which",与参考翻译1共享"ensures that the military",与参考翻译2和3共享"always",最后与参考翻译2共享"of the party"(全部忽略大小写)。 相比之下,候选翻译2表现出的匹配要少得多,而且它们的范围较小。
很明显,程序可以简单地通过比较每个候选翻译和参考翻译之间的n-gram匹配来将候选翻译1排名高于候选翻译2。 对第5节中提供的大量翻译的实验表明,这种区分能力是一种普遍现象,而不是人工编造的一些无聊示例。
BLEU实现者的主要编程任务是将候选翻译的n-gram与参考翻译的n-gram进行比较并计算匹配数。 这些匹配与位置无关。 匹配越多,候选翻译就越好。 为简单起见,我们首先关注计算unigram匹配。
2.1 修正的n-gram精度
我们的指标的基石是熟悉的精度 指标。 为了计算精度,可以简单地计算在任何参考翻译中出现的候选翻译中的单词(unigrams)的数量,然后除以候选翻译中的单词总数。 不幸的是,MT系统可以过度生成“合理的”单词,导致不合理但高精度的翻译,如下面的示例2所示。 直观地,问题很明显:在识别出匹配的候选单词之后,应该认为参考单词已经用过。 我们将这种直觉形式化为修正的unigram精度。 要计算这个精度,首先计算每个单词在任何单个参考翻译中出现的最大次数。 接下来,将每个候选单词的总计数截断到每个参考单词的最大计数2,将这些截断后的计数加起来,并除以候选词的总的(未截断的)数目。
例2
候选翻译: the the the the the the the.
参考翻译1: The cat is on the mat.
参考翻译2: There is a cat on the mat.
修正的unigram精度 = 2/7。 3
在例1中,候选翻译1的修正的unigram精度达到17/18;而候选翻译2的修正的unigram精度达到8/14。 类似地,示例2中修正的unigram精度是2/7,即使其标准unigram精度为7/7。
修正的n-gram精度的计算对于任何n类似:收集所有候选n-gram计数和其相应的最大参考计数。 候选计数被其相应的参考最大值截断、求和并除以候选n-gram的总数。 在示例1中,候选翻译1的修正的bigram精度为10/17,而较低质量的候选翻译2的修正的bigram精度为1/13。 在示例2中,(不真实的)候选翻译的修正的bigram精度为0。 这种修正后的n-gram精度评分捕获翻译的两个方面:充分性和流畅性。 使用与参考翻译中相同的单词(1-grams)的翻译倾向于满足充分性。 较长的n-gram匹配可以说明流畅性。 4
2.1.1 文本块的修正的n-gram精度
我们如何在多语句测试集上计算修正的n-gram精度? 虽然通常在整个文档的语料库中评估MT系统,但我们的基本评估单位是句子。 一条源语句可以翻译成许多目标语句,在这种情况下我们滥用术语并将相应的目标语句称为“语句”。我们首先逐句计算n-gram匹配。 接下来,我们将所有候选语句的截断的n-gram计数相加,并除以测试语料库中候选n-gram的数量,以计算整个测试语料库的修正的精度分数pn。

2.1.2 仅使用修正的n-gram精度的排名系统
为了验证修正后的n-gram精度能否区分非常好的翻译和不良翻译,我们计算了(好的)人工翻译和标准的(较差)机器翻译系统的输出的修正后的精度,总共127条源语句,每条源语句有4个参考翻译。 平均精度结果如图1所示。
图1:区分人类与机器
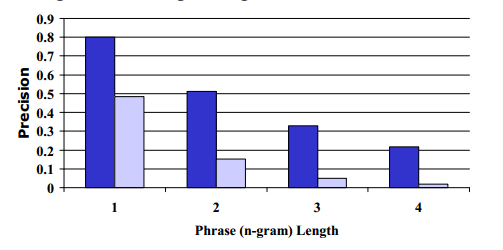
区分人类(高精度)和机器(低精度)的信号很强且引人注目。 从unigram精度到4-gram精度,差异变得越来越大。 似乎任何单个n-gram精度分数都可以区分好的翻译和不良翻译。 然而,为了有用,指标还必须可靠地区分质量差别不大的翻译。 此外,它必须区分两种不同质量的人工翻译。 后一要求确保当MT接近人类翻译质量时,指标的持续有效性。
为此,我们通过对源语言(中文)和目标语言(英语)都不是母语的人获得一个人工翻译。 为了比较,我们通过母语为英语的人获得相同文档的人工翻译。 我们还通过三个商业系统获得机器翻译。 这五个“系统” — 两个人和三个机器 — 基于两个的专业人工参考翻译进行评分。 平均的修正的n-gram精度结果如图2所示。
图2:机器和人工翻译
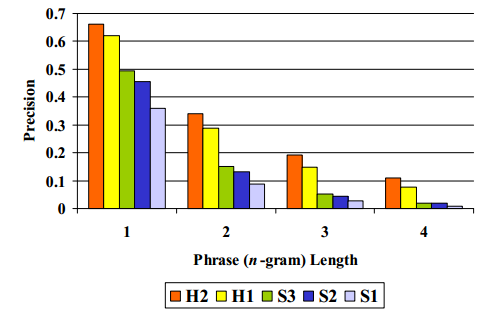
这些n-gram统计中的每一个都意味着相同的排名:H2(人类-2)优于H1(人类-1),并且H1和S3(机器/系统-3)之间的质量大幅下降。 S3看起来比S2好,后者看起来比S1好。 值得注意的是,人类评判员给这些“系统”打出相同的排名顺序,我们将在后面讨论。 虽然在任何单个n-gram精度中似乎有足够的信号,但将所有这些信号组合成单个数值指标更加稳健。
2.1.3 组合修正后的n-gram精度
我们应该如何组合各种n-gram尺寸的修正的精度? 修正精度的加权线性平均值对于这5个系统的结果令人鼓舞。 然而,如图2所示,修正的n-gram精度随n大致呈指数衰减:修正的unigram精度远大于修改的bigram精度,后者又比修改的trigram精度大得多。 合理的平均方案必须考虑到这种指数衰减;修正精度的对数的加权平均值满足该要求。
BLEU使用具有均匀权重的平均对数,这相当于使用修正的n-gram精度的几何平均值。5, 6 通过实验,我们获得的与单语人工评判的最佳相关性的最大n-gram的n为4,虽然3-grams和5-grams 给出差不多的结果。
2.2 语句长度
候选翻译既不应该太长也不应该太短,评估指标应该强制这一点。 在某种程度上,n-gram精度已经实现了这一点。 n-gram精度惩罚候选翻译中未出现在任何参考翻译中的虚假词。 另外,如果候选翻译中的单词比其最大参考计数更频繁地出现,则修正的精度会受到惩罚。 如果一个单词出现的次数是合理的则奖励,一个单词比它在任何参考翻译中出现更多次则进行惩罚。 但是,仅凭修正的n-gram精度无法确保正确的翻译长度,如下面简短、荒谬的示例所示。
例3:
候选翻译: of the
参考翻译1: It is a guide to action that ensures that the military will forever heed Party commands.
参考翻译2: It is the guiding principle which guarantees the military forces always being under the command of the Party.
参考翻译3: It is the practical guide for the army always to heed the directions of the party.
因为这个候选翻译与正确的长度相比是如此之短,所以人们会看到过高的精度:修正的unigram精度为2/2,修正的bigram精度为1/1。
2.2.1 recall 的麻烦
传统上,精度与recall 相结合以克服这种与长度相关的问题。 但是,BLEU考虑多个参考译文,每个参考译文可以使用不同的单词选择来翻译相同的源词。 此外,一个好的候选翻译只会使用(recall )这些可能的选择之一,但不是全部。 实际上,recall 所有选择会导致翻译不好。 下面是一个例子。
例4:
候选翻译1: I always invariably perpetually do.
候选翻译2: I always do.
参考翻译1: I always do.
参考翻译2: I invariably do.
参考翻译3: I perpetually do.
第一个候选翻译包含参考翻译中的更多单词,但显然比第二个候选翻译更差。 因此,在所有参考单词集合上计算的recall 不是一个好的指标。 不可否认,人们可以调整参考翻译以发现同义词并计算对概念而不是单词的recall。 但是,考虑到参考翻译的长度不同并且单词顺序和语法不同,这种计算很复杂。
2.2.2 句子简短惩罚
比参考翻译更长的候选翻译已经被修正的n-gram精度指标所惩罚:没有必要再次惩罚它们。 因此,我们引入一个乘法简洁惩罚因子。 有了这种简洁惩罚,高分候选翻译现在必须与参考翻译的长度、单词选择和单词顺序相匹配。 注意,这种简洁惩罚和修正的n-gram精度长度效应都不直接考虑源长度;相反,它们考虑目标语言中的参考翻译长度范围。
当候选翻译的长度与任何一个参考翻译的长度相同时,我们希望简短惩罚为1.0。 例如,如果有三个参考翻译的长度为12、15和17个单词,并且候选翻译是简洁的12个单词,我们希望简短惩罚为1。 我们将最接近的参考语句长度称为“最佳匹配长度。”
还有一个考虑因素:如果我们逐句计算出简短惩罚并对罚分进行平均,那么短句的长度偏差就会受到严厉的惩罚。 相反,我们计算整个语料库的简洁惩罚,以允许句子级别的一些自由。 我们首先通过对语料库中每个候选句子的最佳匹配长度求和来计算测试语料库的有效参考长度r。 我们选择简短惩罚为一个衰减指数r/c,其中c是候选翻译语料库的总长度。
2.3 BLEU细节
我们采用测试语料库的修正精度得分的几何平均值,然后将结果乘以指数简洁惩罚因子。 目前,案例折叠是在计算精度之前执行的唯一文本规范化。
我们首先计算修正的n-gram精度的几何平均值pn,使用直到长度N的n-gram和正权重wn求和为一个。
接下来,令c为候选翻译的长度,r为有效参考语料库长度。 我们计算简洁惩罚BP,
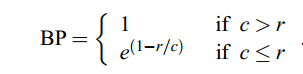
然后

排名行为用log 表示更加明显,

在我们的基准中,我们使用 N=4 及均匀权重 wn=1/N。
3 BLEU评估
BLEU指标的范围从0到1。 除非翻译与参考翻译完全相同,否则很少有翻译获得1分。 因此,即使是人工翻译也不一定得1分。 值得注意的是,每个句子的参考翻译越多,得分就越高。 因此,必须谨慎对待具有不同参考翻译数量的评估进行“粗略”比较:在大约500个句子的测试语料库(40个一般新闻故事)中,人工翻译对四个参考文献得分为0.3468,对两个参考文献得分为0.2571 。 表1显示了5个系统的在该测试语料库中对两个参考翻译的BLEU得分。
MT系统S2和S3在此指标中非常接近。 因此,出现了几个问题:
表1:500个句子的BLEU

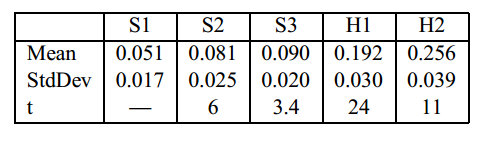
表2:20个文本块的成对 t 统计量
• BLEU指标的差异是否可靠?
• BLEU分数的差异是什么?
• 如果我们要选择另一组500个句子,我们仍然会判断S3比S2好吗?
为了回答这些问题,我们将测试语料库分成20个块,每个块有25个句子,并分别计算这些块上的BLEU指标。 因此,对于每个系统,我们得到20个BLEU指标。 我们计算了表2中显示的均值、方差和配对t统计量。 t 统计量将每个系统与表中的左邻居进行比较。 例如,对于S1和S2对,t=6。
请注意,表1中的数字是总计500个句子的BLEU度量,但表2中的平均值是25个句子的聚合上的BLEU度量的平均值。 正如所料,这两组结果对于每个系统都是接近的,并且仅受小的有限块大小效应的影响。 由于1.7或更高的配对t统计量显着性为95%,因此系统得分之间的差异在统计上非常显着。 报告的25个语句块的方差是500个语句语料库等大量测试集的方差的上限。
我们需要多少参考翻译? 我们模拟了一个单参考翻译测试语料库,通过随机选择4个参考翻译中的一个作为40个故事中每个故事的单一参考翻译。 通过这种方式,我们确保了一定程度的风格变化。 系统保持与多个参考翻译相同的排名顺序。 这个结果表明,如果翻译不是全部来自同一个翻译,我们可以使用带有单个参考翻译的大型测试语料库。
4 人工评估
我们有两组人工评判人员。 第一组称为单语组,由10名母语为英语的人组成。 第二组称为双语组,由10名以中国人为母语的人组成,他们过去几年一直住在美国。 没有一个人工评判人员是专业翻译。 这些人员在我们的500个语句的测试语料库中随机抽取的中文语句中评判我们的5个标准系统。 我们将每个源句与其5个翻译中的每一个进行配对,总共250对中文源和英语翻译。 我们准备了一个网页,随机排序这些翻译对,以分散每个源句的五个翻译。 所有评委都使用同一个网页,并以相同的顺序查看句子对。 他们将每个翻译评分从1(非常差)到5(非常好)。 单语组只根据翻译的可读性和流畅性做出判断。
正如所料,一些评估人员比其他评估人员更自由。 有些句子比其他句子更容易翻译。 为了说明评估人员与语句之间的内在差异,我们比较了每个评估人员对系统之间语句的评分。 我们在相邻系统之间进行了四次成对t检验比较,按其总平均得分排序。
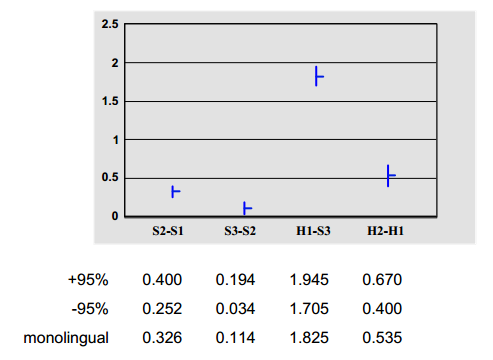
4.1 单语组成对判断
图3显示了两个连续系统的得分和平均值的95%置信区间之间的平均差异。 我们看到S2比S1好一点(通过5分制的平均意见得分差异为0.326),而S3被判断为更好(0.114)。 Both differences are significant at the 95% level.7 The human H1 is much better than the best system, though a bit worse than human H2. 这并不奇怪,因为H1不是中文或英文的母语,而H2是母语为英语的人。 同样,人类翻译之间的差异显着超过95%。
图3:单语判断 - 成对差分比较
4.2 双语组成对判断
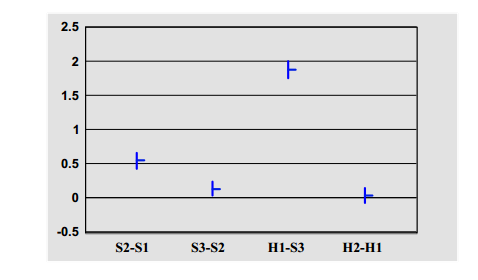
图4显示了双语组的相同结果。 他们还发现S3稍微好于S2(置信度为95%)虽然他们判断人类翻译更接近(95%置信度无法区分),这表明双语者更倾向于关注充分性而不是流利性。
图4:双语判断 - 成对差异比较
5 BLEU与人类评估
图5显示了作为5个系统的两个参考翻译的BLEU分数的函数的单语组分数的线性回归。 高相关系数0.99表明BLEU很好地跟踪人类判断。 特别有趣的是BLEU如何区分S2和S3,它们非常接近。 图6显示了双语组的可比回归结果。 相关系数为0.96。
图5:BLEU预测单语判断
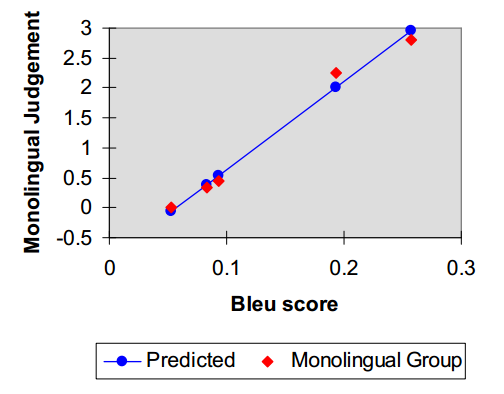
图6:BLEU预测双语判断

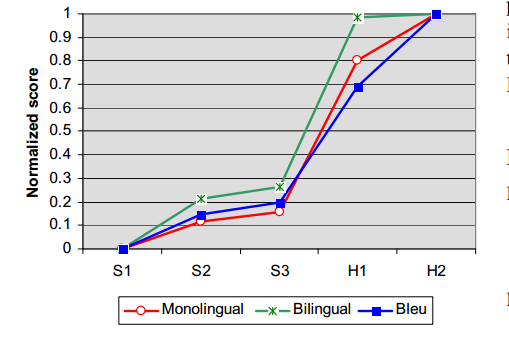
我们现在将最差系统作为参考点,并将BLEU分数与剩余系统相对于最差系统的人类判断分数进行比较。 我们采用了BLEU,单语组和5个系统的双语组分,并按相应的范围(5个系统的最大和最小分数)对它们进行线性标准化。 标准化分数如图7所示。 该图说明了BLEU评分与单语组之间的高度相关性。 特别感兴趣的是BLEU估计S2和S3之间的微小差异以及S3和H1之间的较大差异的准确性。 该图还突出了MT系统和人类翻译员之间的相对大的间隙。8此外,我们推测,双语组判断H1相对于H2非常宽容因为单语组能发现它们翻译流利性之间的差别。
图7:BLEU与双语和单语评判人员
六,结论
我们相信BLEU将通过允许研究人员快速掌握有效的建模思想来加速MT研发周期。 我们的观点通过最近对BLEU与人类判断相关的统计分析得到了加强,这些判断与代表3种不同语言家族的四种完全不同的语言(阿拉伯语,汉语,法语,西班牙语)翻译成英语(Papineni et al。,2002)! BLEU的优势在于它通过在测试语料库中平均个别句子判断错误而不是试图为每个句子判断出确切的人类判断来与人类判断高度相关:数量导致质量。
最后,由于MT和摘要都可以被视为从文本上下文生成自然语言,因此我们认为BLEU可以适用于评估摘要或类似的NLG任务。
致谢这项工作得到了国防高级研究计划局的部分支持,并由SPAWAR根据合同号进行监督。 N66001-99-2-8916。 本材料中包含的观点和调查结果均为作者的观点和结果,并不一定反映政府的政策立场,也不应推断出官方认可。
我们非常感谢BBN的John Makhoul对几何意义的评论以及与NIST的George Doddington的讨论。 我们特别要感谢在单语和双语评判席上工作的同事,他们坚持不懈地判断中英文MT系统的输出。
1 因此,我们将我们的方法称为bilingual evaluation understudy,BLEU。
2 Countclip=min(Count, Max_Ref_Count)。 换句话说,如果需要,截断每个单词的计数,使其不超过该单词在任何单个引用翻译中观察到的最大计数。
3 为了阅读方便,我们对计算修正后的精度比较重要的单词加上了下划线。
4 BLEU只需要在测试语料库中进行平均时匹配人类判断;个别句子的分数通常会因人类判断而异。 例如,如果所有参考翻译都读作“economy of East Asia”,那么产生流利短语“East Asian economy”的系统将受到较长n-gram精度的严重惩罚。BLEU成功的关键是所有系统都得到了处理类似地,使用具有不同风格的多个人工翻译器,因此这种效果在系统之间的比较中消除。
5 如果任何一个修正后的精度消失,则几何平均值会很极端,但在合理大小的测试语料库中这应该是极为罕见的事件(对于Nmax ≤ 4)。
6 使用几何平均值而不是使用算术平均值得出的最佳结果也会产生与人类评判相比略强的相关性。
7 95%置信区间来自t检验,假设数据来自具有N个自由度的T分布。 N在350到470之间变化,因为一些评委在评估中跳过了一些句子。 因此,分布接近于高斯分布。
8 跨越这一中英翻译的鸿沟似乎是当前最先进系统面临的重大挑战。
参考文献
E.H. Hovy. 1999. Toward finely differentiated evaluation metrics for machine translation. In Proceedings of the Eagles Workshop on Standards and Evaluation, Pisa,Italy.
Kishore Papineni, Salim Roukos, Todd Ward, John Henderson, and Florence Reeder. 2002. Corpus-based comprehensive and diagnostic MT evaluation: Initial Arabic, Chinese, French, and Spanish results. In Proceedings of Human Language Technology 2002, SanDiego, CA. To appear.
Florence Reeder. 2001. Additional mt-eval references.Technical report, International Standards for Language Engineering, Evaluation Working Group. http://issco-www.unige.ch/projects/isle/taxonomy2/
J.S. White and T. O’Connell. 1994. The ARPA MT evaluation methodologies: evolution, lessons, and future approaches. In Proceedings of the First Conference of the Association for Machine Translation in the Americas, pages 193–205, Columbia, Maryland.