Hearts强化学习的特征构建
Nathan R. Sturtevant and Adam M. White
Department of Computer Science
University of Alberta
Edmonton, AB, Canada T6G 2E8
{nathanst, awhite}@cs.ualberta.ca
摘要
时间差异(TD)学习已被用于学习各种双人游戏中的强大评估功能。 TD-gammon说明了游戏树搜索和学习方法的组合如何在十五子棋中取得大师级水平。 在这项工作中,我们基于随机线性回归和TD学习,开发了一个4人游戏Hearts的玩家。 使用游戏一小部分基本特征,我们将特征详尽地组合到一个更具表现力的游戏状态表示中。 我们的初步结果基于学习各种特征的组合并在自己和基于搜索的玩家中训练。 我们简单的学习程序能够击败最好的基于搜索的Hearts程序。
1 引言和背景
学习算法有可能降低构建和调整复杂系统的难度。 但是,通常需要大量的工作来调整针对特定问题和域的每种学习方法。 我们在这里描述用于构建程序来玩Hearts游戏的方法。 该计划明显强于先前建立的专家调整计划。
1.1 Hearts
Hearts是一款基于技巧的纸牌游戏,通常由四名玩家和一副52张牌组成。 在比赛开始之前,每张牌手面朝下发出13张牌。 在所有玩家看到他们的牌之后,第一个玩家在牌桌上面朝上玩牌(领牌)。 其他球员按顺序排列,如果可能的话,可以按照领先的方式进行同样的比赛。 当所有玩家都玩过时,玩过最高牌的玩家将获胜或获胜。 这名玩家将所打的牌面朝下放入他的一堆技巧中,然后引领下一招。 这一直持续到所有牌都被播放为止。
Hearts的目标是尽可能少的点。 玩家根据所采用的技巧中的牌来获取积分。 心中的每张牌(♥)值得一分,黑桃王后(Q ♠)值13。 如果一名球员拿下所有26分,也称为射击月球,则他们获得0分,其他玩家各获得26分。
在游戏开始之前,玩家之间传递卡片,确定谁先领先,确定何时可以领导心脏,以及根据游戏提供额外积分,心脏规则有很多变化。 在这项工作中,我们使用了一个简单的规则变化:没有卡片传递,并且没有限制何时可以播放卡片。
Hearts是一款不完全信息游戏,因为玩家无法看到对手的牌。 使用蒙特卡洛搜索、对对手手牌进行采样并使用完全信息技术解决,纸牌游戏中的不完全信息已经被成功处理。 虽然这种方法有一些已知的局限性[1],但它在实践中非常有效。 最强大的桥接程序GIB [2]基于蒙特卡罗搜索。 这种方法也用于Sturtevant的论文工作中的Hearts [3]。 我们没有学习玩Hearts的不完美信息游戏,而是建立了一个学习玩游戏完美信息版本的程序。 然后我们将此作为蒙特卡洛玩家的基础,该玩家可以玩完整的游戏。
1.2 与Hearts相关的研究
关于Hearts游戏的学习和搜索算法已有多项研究。 因为Hearts是一个多人游戏(超过两个玩家),所以不能使用minimax搜索。 相反,maxn[4]是用于玩多人游戏的通用算法。
Perkins [5]基于max n搜索开发了两种基于搜索的多人不完全信息游戏方法。 第一种搜索方法根据每个玩家的移动可用性和值构建了一个max n树。 第二种方法最大化了蒙特卡罗生成的搜索树的max n值。 由此产生的玩家对人类和基于规则的玩家产生了低到中等水平的游戏。
最强大的计算机心脏程序之一[3],使用高效的多人游戏修剪算法,加上蒙特卡罗搜索和手动调整评估功能。 当针对一个着名的商业节目1进行测试时,它平均每手击败该节目1.8点,每场比赛20分。 Hearts游戏并没有“解决”:这个程序仍然比人类弱。 我们使用这个程序作为专家来训练本文的一些实验。 在本文的其余部分,我们将完整的程序称为不完全信息专家(IIE),并将基础解算器称为完美信息专家(PIE)。
时间差(TD)学习方法对Hearts的第一个应用之一是[6]。 然而,这些结果相当薄弱。 由此产生的计划能够击败随机计划,并在一场小型比赛中击败其他学习球员。 但是,它无法击败基于蒙特卡洛的球员。 Fujita等人已经做了几项关于将强化学习(RL)算法应用于Hearts游戏的研究。 在他们最近的工作[7]中,Fujita等人将游戏建模为部分可观察的马尔可夫决策过程(POMDP),其中代理可以观察游戏状态,但是状态的其他维度,例如对手的手,是不可观察。 他们使用一步历史,根据之前的动作选择模型构建了对手动作选择启发式的新模型。 虽然他们学到的球员比以前的球员表现更好,并且还击败了基于规则的球员,但很难知道学习算法和结果球员的真正实力。 这是由于训练游戏数量有限以及最终学习者缺乏验证。 Fujita等人的工作与我们的不同之处在于它们低估了特征选择问题,这是我们学习代理人所展示的高水平游戏的关键因素。
Finally, Furnkranz et al [8] have done initial work using RL techniques to employ an operational advice system to play hearts. 与TD学习一起使用神经网络来学习从状态抽象和动作选择建议到许多移动选择启发法的映射。 这使得他们的系统可以使用一小部分功能(15)和很少的培训来学习策略。 然而,这项工作仍处于初步阶段,由此产生的玩家仅对构建学习系统的操作建议系统的贪婪行动选择表现出微小的改进。
1.3 强化学习
在强化学习中,代理通过选择各种状态中的动作来与环境交互,以最大化环境给予它的标量奖励的总和。 例如,在心中,状态由游戏中每个玩家持有并由其携带的牌组成,并且每当你用一个点上的点数时分配负奖励。 环境包括其他玩家以及游戏规则。
RL方法与大脑中发生的认知过程有很强的联系,并且在Robocup足球[9],工业电梯控制[10]和步步高[10]中证明是有效的。 这些学习算法能够简单地通过在高维度且有时连续有价值的状态和动作空间中与环境的试验和错误交互来获得接近最优的策略。

图。1。 学习使用TD(λ)给出游戏历史
所有上述例子都使用TD学习[10]。 在最简单的TD学习形式中,代理存储每个州V(s)的估计奖励的标量值。 代理选择导致具有最高实用程序的状态的操作。 在表格的情况下,值函数表示为由状态索引的数组。 在剧集的每个决策点或步骤,代理根据观察到的奖励更新价值功能。 TD使用自举,其中代理使用当前时间步骤上接收的奖励以及当前状态值与前一时间步的状态值之间的差异来更新其状态值。 TD(λ)根据指数衰减更新所有先前遇到的状态值,指数衰减由λ确定。 在这项工作中使用的用于TD学习的伪代码在图1中给出,其中他的游戏历史和<是在一集结束时的奖励(获得的分数)。
1.4 函数逼近
保证TD(λ)在表格情况下收敛到最优解,其中可以为每个状态存储唯一值。 许多有趣的问题,例如Hearts,具有限制性大的数字状态。 给定一副52张牌,每个玩家获得13张牌,在游戏中有52个!/ 13!4 = 5.4×10 28可能的牌。 事实上,这只是状态空间实际大小的下限,因为它没有考虑我们在玩游戏时可能遇到的状态。 无论如何,我们不能将这么多的状态存储在记忆中,即使我们可以,也没有时间在每个州进行访问和训练。
因此,我们需要一些方法来近似游戏的状态。 通常,这是通过选择一组近似于环境状态的特征来完成的。 函数逼近器必须将这些特征映射到环境中每个状态的值函数。 这推广了对类似状态的学习并提高了学习速度,但可能会引入泛化错误,因为这些特征不能完全代表状态空间。
最简单的函数逼近器之一是线性感知器。 感知器将状态值函数计算为其输入特征的加权和。 权重w根据公式更新:
w ← w + α·errors·φs
given the current state s, current state output error errors , which is provided by TD learning, and the features of the current state, φs .
因为感知器的输出是其输入的线性函数,所以它只能学习线性可分离的函数。 最有趣的问题需要从特征到状态值的非线性映射。 在许多情况下,人们将使用更复杂的函数逼近器,例如神经网络,径向基函数,CMAC瓦片编码或基于内核的回归。 这些方法可以表示各种非线性函数。我们采用的另一种方法是使用具有更复杂特征集的简单函数逼近器。 我们使用线性函数逼近有几个原因:线性回归易于实现,学习速率与特征数量成线性关系,学习的网络权重更容易分析。 我们的结果表明,线性函数逼近能够学习并有效地发挥Hearts的不完美信息游戏。
我们通过一个简单的例子说明了附加特征如何允许线性函数逼近器解决非线性任务:考虑基于两个输入学习XOR函数的任务。 双输入感知器无法学习此功能,因为XOR不能线性分离。 但是,如果我们只是使用额外输入(前两个输入的逻辑AND)来增加网络输入,则网络可以学习最佳权重。 事实上,n个点的所有子集在n - 1维空间中始终是线性可分的。 因此,给定足够的特征,非线性问题可以具有精确的线性解。
2 学习玩Hearts
在描述我们在Hearts中学习的努力之前,我们研究了步步高的特征,使其成为TD学习的理想领域。 在步步高中,除了捕获之外,碎片总是被迫向前移动,因此游戏不能永远运行。 每个玩家可用的一组动作由掷骰子确定,这意味着即使从相同的位置,学习玩家也可能被迫在每个游戏中遵循不同的游戏线,这与诸如国际象棋之类的确定性游戏不同。游戏很容易重复。 因此,自我游戏在步步高中运作良好。
Hearts有一些类似的属性。 每位玩家在每场比赛中完成13次动作,这意味着我们无需等待很长时间即可获得与比赛相关的精确奖励。 因此,我们可以快速生成和播放大量的训练游戏。 此外,扑克牌是随机发放的,因此与十五子棋一样,玩家被迫在每场比赛中探索不同的比赛线路。 Hearts的另一个有用特性是,即使是技术很差的玩家偶尔也能获得好牌。 因此,我们保证会看到好戏的例子。
Hearts和步步高之间的一个关键区别是步步高中的棋盘位置值往往是独立的。 然而,在Hearts中,任何卡的价值都与其他牌的价值相关。 例如,当2-9♥已经打出时,打出10♥是一个很好的出牌。 但是,如果它们没有打出,这是一个很差的出牌。 这使得玩游戏所需的特征变得复杂。
2.1 特征生成
鉴于我们使用的是简单函数逼近器,我们需要一组丰富的功能。 在Hearts游戏和一般的纸牌游戏中,有许多非常简单的功能可以随时访问。 例如,我们可以为每个玩家手中持有的每张牌以及他们拍摄的每张牌都设置一个二进制功能(例如,如果玩家1拥有2 ♥,则第一个特征为真,如果玩家1有3 ♥等,则第二个为真。 这将为每个玩家提供总共104个功能,并为所有玩家提供416个功能。 这组功能完全指定了一个游戏,所以理论上它应该足够学习,给定一个适当强大的函数逼近器和学习算法。
但是,考虑一个简单的问题,如:“玩家1是否有最低的心脏?”基于这些简单的功能回答这个问题是非常困难的,因为最低的心脏是由已经玩过的牌决定的。 如果我们想要表达上面描述的简单特征,它会看起来像:“[玩家1有2 ♥]或[玩家1有3 ♥ AND Player 2没有2 ♥ AND Player 3没有2 ♥ AND Player 4没有2 ♥]或者[玩家1有4 ♥ ...]“。 虽然这种完全组合可以通过非线性函数逼近器来学习,但它不太可能。
另一种自动组合基本游戏功能的方法是GLEM [11]。 GLEM测量基本特征组的重要性,构建学习权重的互斥集。 这种方法非常适合许多棋盘游戏。 但是,正如我们上面所说明的那样,玩纸牌游戏所需的功能非常复杂且不容易学习。 可以使用类似的原则来改进我们的方法,但我们还没有详细考虑它们。
我们的方法是定义一组有用的功能,我们称之为原子功能。 这些功能是完美的信息功能,因此它们取决于其他玩家所持有的卡。 然后,我们通过将这些原子特征组合在一起来构建更高级别 用于学习的一组原子特征可以在附录A中找到。
尝试手动构建原子特征的所有有用组合将是乏味的,容易出错且耗时的。 相反,我们采取更蛮力的方法。 给定一组原子特征,我们通过详尽地采用原子特征的所有成对AND组合来生成新特征。 显然,我们可以通过添加OR运算和否定来进一步采取这一点。 但是,为了限制功能增长,我们目前只考虑AND运算符。
2.2 学习参数
对于此处描述的所有实验,我们使用TD学习如下。 λ的值设定为0.75。 我们首先使用单个学习玩家以及从Sturtevant的论文工作[3](PIE和IIE)中获取的三个专家搜索玩家,或者我们学习的网络的三个副本进行自我游戏,来制作和玩一个Heart游戏。 在大多数实验中,我们报告了在没有蒙特卡罗的情况下针对学习网络播放手动调整评估函数(PIE)的结果。 因此,专家级玩家的搜索和评估功能充分利用了所提供的完美信息(玩家的手),并且是我们完美信息学习玩家的公平对手。 使用max n算法选择移动,前瞻深度为1到4,基于当前技巧剩余的牌数。 在搜索树中备份值时,我们使用自己的网络作为对手的评估函数。
为了简化学习网络,我们仅在当前技巧中没有卡片的状态下评估游戏。 我们没有在已经播放过所有积分的州学习。 在玩游戏之后,我们计算了学习玩家的奖励,然后在游戏中倒退,使用TD学习来更新我们的目标输出并训练我们的感知器来预测每一步的目标输出。 我们没有尝试使用更复杂的方法进行训练,如TDLeaf [12]。
2.3学会避免Q ♠
我们的第一个学习任务是预测我们是否会采用Q ♠。 我们训练感知器返回0到13之间的输出,即游戏中Q ♠的值。 In practice, we cut the output off with a lower bound of 0 + ℰ and an upper bound of 13 − ℰ so that the search algorithm could always distinguish between states where we expected to take the Q♠versus states where we already had taken the Q♠, preferring those where we had not yet taken the queen. 感知器学习率设置为1 /(13×个活动特征)。
我们使用附录A中列出的60个基本功能作为游戏的原子功能。 然后,我们建立了这些原子特征的成对,三向和四向组合。 这些特征的成对组合产生1,830个总特征,原子特征的三个组合导致34,280个总特征,并且四个特征组合导致523,685个总特征。 但是,许多这些功能是相互排斥的,永远不会发生。 我们在±1 / numfeatures之间随机初始化特征权重。

图2。 学习不使用原子特征的各种组合来获取Q♠。 盈亏平衡点位于3.25
训练期间学习者的平均得分如图2所示。 该学习曲线是相对于PIE的性能。 除了四个方面的功能外,我们针对专家计划进行了五次20万场比赛的训练。 然后在每次运行和超过5,000个游戏窗口之间平均得分。 每手得分13分,均匀匹配的球员每手将获得3.25分。 图中的水平线表示学习和专家课程之间的收支平衡点。
These results demonstrate that the atomic features alone were insufficient for learning to avoid taking the Q♠. 成对和三向特征也不足,但仅比原子特征更好。 然而,四个特征组合足以击败专家计划。
表格1。 功能预测我们可以避免Q♠。

表2。 功能预测我们将采取Q♠。

表1中显示了最好地预测避免Q 的特征。 该播放器实际上使用所有原子,成对,三和四个特征,因此该表中的一些最佳特征仅具有三个原子特征。 权重是负面的,因为它们会降低我们在游戏中的预期得分。
关于这些功能有几点需要注意。 首先,我们可以看到最高加权特征也是新手玩家很快学会的:如果Q ♠的玩家没有其他黑桃并且我们可以领先黑桃,我们保证不会采取Q ♠ T1>。 在这种情况下,引导铲子将迫使Q ♠到另一个玩家身上。
因为我们已经生成了所有四个特征组合,并且此特征仅需要指定三个原子特征,我们最终会在添加额外原子特征的情况下重复多次重复相同的原子特征。 排名为2,4和5的功能是第一个功能的副本,添加了一个额外的原子功能。 排名第148位的特征应该看起来很奇怪,但是我们会在查看预测我们将采用Q ♠的特征时解释它。
表2列出了最佳预测Q ♠的特征。 这些功能稍微不那么直观。 我们可能期望从表2中的表1中找到对称版本的特征(例如, 我们有一个Q ♠并且领先的玩家有黑桃。 此功能属于前300个(超过500,000个)功能之中,但不在前五个功能中。
表2的有趣之处在于功能之间的相互作用。 同样,我们看到构成排名第二的特征的原子特征是排名最高的特征的子集。 实际上,这两个原子特征在前20,000个特征中出现了259次。 它们作为特征的一部分出现92次,这降低了我们采用Q ♠的机会,而它们增加了167次的可能性。 我们可以用它来解释所学的内容:让Q ♠只有一个其他的spade在我们手中意味着我们可能会采用Q ♠(特征2 in表2)。 If we also have the lead (feature 1 in Table 2), we are even more likely to take the Q♠. But, if someone else has the lead, and they do not have spades (feature 148 in Table 1), we are much less likely to take the Q♠.
The ability to do this analysis is one of the benefits of putting the complexity into the features instead of the function approximator. If we rely on a more complicated function approximator to learn weights, it is very difficult to analyze the resulting network. Because we have simple weights on more complicated features it is much easier to analyze what has been learned.
2.4 Learning to Avoid Hearts
We used similar methods to predict how many hearts we would take within a game, and learned this independently of the Q♠. One important difference between the Q♠ and points taken from hearts is that the Q♠ is taken by one player all at once, while hearts are gradually taken throughout the course of the game. To handle this, we removed 14 Q♠specific features and added 42 new atomic features to the 60 atomic features used for learning the Q♠. The new features were the number of points (0-13) taken by ourselves, the number of points taken (0-13) by all of our opponents combined, and the number of points (0-13) left to be taken in the game.
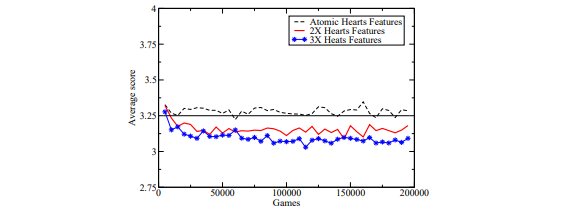
Fig. 3. Learning to not take the Hearts using various combinations of atomic features
Given these atomic features, we then trained with the atomic (88), pair- wise (3,916) and three-wise (109,824) combinations of features. As before, we present the results averaged over five training runs (200,000 games each) and then smoothed over a window of 5,000 games. The learning graph for this train- ing is in Figure 3. An interesting feature of these curves is that, unlike learning the Q♠, we are already significantly beating the expert with the two-wise features set. It appears that learning to avoid taking hearts is a bit easier than avoiding the Q♠. However, when we go from two-wise to three-wise features, the increase in performance is much less. Because of this, we did not try all four-wise combinations of features.
2.5 Learning Both Hearts and the Q♠
Given two programs that separately learned partial components of the full game of Hearts, the final task is to combine them together. We did this by extracting the most useful features learned in each separate task, and then combined them to learn to play the full game. The final learning program used the top 2,000 features from learning to avoid hearts and the top 10,000 features used when learning to avoid the Q♠.
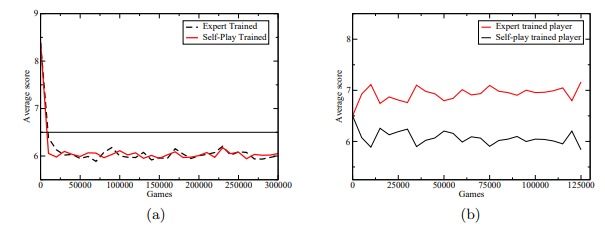
Fig. 4. (a) Performance of expert-trained and self-trained player against the expert. (b) Performance of self-trained and expert-trained programs against each other.
We tried training this program in two ways: first, by playing against PIE, and second, by self-play. During this training shooting the moon was disabled. The first results are plotted in Figure 4(a). Instead of plotting the learning curve, which is uninteresting for self-play, we instead plot the performance of the learned network against the expert program. We did this by playing games between the networks that were saved during training and the expert program. For two player types there are 16 ways to place those types into a four-player game, however two of these ways contain all learning or all expert players. 100 games were played for each of the 14 possible arrangements for a total of 1400 hands played for each data point in the curve. There are 26 points in the full game, so the break-even point, indicated by a horizontal line, falls at 6.5 points. Both the self-trained player and the expert-trained player learn to beat the expert by the same rate, about 1 point per hand.
In Figure 4(b) we show the results from taking corresponding networks trained by self-play and expert-play and playing them in tournaments against each other. (Again, 1400 games for each player type.) Although both of these programs beat PIE program by the same margin, the program trained by self play managed to beat PIE by a large margin; again about 1 point per hand.
While we cannot provide a decisive explanation for why this occurs, we speculate that the player which only trains against the expert does not sufficiently explore different lines of play, and so does not learn to play well in certain situations of the game where the previous expert always made mistakes. The program trained by self-play, then, is able to exploit this weakness.
2.6 Imperfect Information Play
Given the learned perfect-information player, we then played it against IIE. For these tests, shooting the moon was enabled. Both programs used 20 Monte-Carlo models and analyzed the first trick of the game in each model (up to 4-ply). When just playing single hands, the learned player won 56.9% of the hands with an average score of 6.35 points per hand, while the previous expert program averaged 7.30 points per hand. When playing full games (repeated hands to 100 points), the learned player won 63.8% of the games with an average score of 69.8 points per game as opposed to 81.1 points per game for IIE.
3 Conclusions and Future Work
The work presented in this paper presents a significant step in learning to play the game of Hearts and in learning for multi-player games in general. We have shown that a search-based player with a learned evaluation function can learn to play Hearts using a simple linear function approximator and TD-learning with either expert-based training or self-play. Furthermore, our learned player beat one of the best-known programs in the world in the imperfect information version of Hearts.
There are several areas of interest for future research. First, we would like to extend this work to the imperfect information game to see if the Monte-Carlo based player can be beat. Next, there is a question of the search algorithm used for training and play. There are weaknesses in maxnanalysis that soft-maxn[13] addresses; the paranoid algorithm [14] could be used as well.
Our ultimate goal is to play the full game of Hearts well at an expert level, which includes passing cards between players and learning to prevent other play-ers from shooting the moon. It is unclear if just learning methods can achieve this or if other specialized algorithms may be used to tasks such as shooting the moon. But, this work is the first step in this direction.
Acknowledgments
We would like to thank Rich Sutton, Mark Ring and Anna Koop for their feedback and suggestions regarding this work. This work was supported by Alberta’s iCORE, the Alberta Ingenuity Center for Machine Learning and NSERC.
A Atomic Features Used to Learn the Q♠
Unless explicitly stated, all features refer to cards in our hand. The phrase “to start” refers to the initial cards dealt. “Exit” means we have a card guaranteed not to take a trick. “Short” means we have no cards in a suit. “Backers” are the J-2♠. “Leader” and “Q♠player” refers to another player besides ourself.
