Neural Machine Translation of Rare Words with Subword Units
摘要
神经网络机器翻译(NMT)模型通常使用固定词汇表,但翻译是一个开放词汇表问题。 以前的工作通过退回到一个字典来解决词汇表外单词的翻译问题。 在本文中,我们介绍一种更简单、更有效的方法,通过将稀有和未知单词编码为subword 单元序列,使 NMT 模型能够开放式词汇翻译。 这种方法基于直觉,即各种类型的单词可以通过比单词更小的单位进行翻译,例如名词(通过字符复制或音译)、复合词(通过成分翻译),同源词和借词(通过语音和形态变换)。 我们讨论不同分词技术的适用性,包括简单的字符n-gram模型和基于字节对编码压缩算法的分段,并且凭经验表明 subword 模型比回退字典基准模型有所改进,对于WMT 15 英语→德语和英语→俄语翻译任务分别提高BLEU 1.1和1.3 。
1 简介
神经机器翻译最近显示了令人印象深刻的结果(Kalchbrenner and Blunsom, 2013; Sutskever et al., 2014; Bahdanau et al., 2015)。 然而,罕见词的翻译是一个悬而未决的问题。 神经模型的词汇量通常限于30000-50000个单词,但翻译是一个开放词汇问题,特别是对于具有很多单词合成处理(如凝集和复合)的语言,翻译模型需要低于词汇水平的机制。 例如,考虑德语复合词Abwasser | behandlungs | anlange ‘sewage water treatment plant’,直观上分段、可变长度的表示比将该单词编码为固定长度的向量更有用。
对于单词级NMT模型,词汇外单词的翻译已通过对词典查找的回退来解决(Jean et al., 2015; Luong et al., 2015b)。 我们注意到这些技术做出的假设在实践中往往不成立。 例如,由于语言之间形态合成程度的差异,源词和目标词之间并不总是一对一的对应关系,就像在我们的介绍性复合示例中那样。 此外,单词级模型无法翻译或生成未见过的单词。 如(Jean et al., 2015; Luong et al., 2015b)所做的那样,将未知单词复制到目标文本中对于名词是一种合理策略,但通常需要形态变化和转写,特别是在字母表不同的情况下。
我们研究 subword 单元级别上运行的 NMT 模型。 我们的主要目标是在 NMT 网络本身中建立开放式词汇翻译模型,而不需要针对稀有单词的回退模型。 除了使翻译过程更简单之外,我们还发现,与大词汇模型和回退词典相比,subword 模型对于稀有词的翻译具有更高的准确性,并且能够有效地生成在训练中看不到的新词。 我们的分析表明神经网络能够从 subword 表示中学习复合和转写单词。
本文有两个主要贡献:
• 我们表明,通过 subword 单元编码(罕见)单词,可以进行开放式词汇神经网络机器翻译。 我们发现我们的架构比使用大型词汇表和回退词典(Jean et al., 2015; Luong et al., 2015b)更简单、更有效。
• 我们将字节对编码 (BPE) (Gage, 1994)(一种压缩算法)应用于分词任务。 BPE允许通过可变长度字符序列的固定大小的词汇表示开放词汇表,使其成为神经网络模型的非常合适的分词策略。
2 神经网络机器翻译
我们遵循Bahdanau et al. (2015)的神经机器翻译架构,我们将在这里简要总结一下。 但是,我们注意到我们的方法并不特定于此架构。
神经网络机器翻译系统被实现为具有递归神经网络的编码器-解码器网络。
编码器是具有门控循环单元的双向神经网络(Cho et al., 2014) ,其读取输入序列x = (x1, ..., xm) 并计算隐藏状态的正向序列 (h1→, ..., hm→)和反向序列(h1←, ..., hm←)。 隐藏状态 hj→ 和 hj← 将连接在一起以获得注解 hj。
解码器是递归神经网络,其预测目标序列 y= (y1, ..., yn)。 基于循环隐藏状态 si、先前预测的单词 yi−1 和上下文矢量 ci 来预测每个单词yi。 ci 被计算为注解 hj 的加权和。 通过对齐模型 αij 计算每个注解 hj 的权重,其模拟 yi 与 xj 对齐。 对齐模型是单层前馈神经网络,通过反向传播与网络的其余部分共同学习。
详细描述可以在((Bahdanau et al., 2015)中找到。 在具有随机梯度下降的平行语料库上执行训练。 翻译采用具有较小 beam size 的 beam search。
3 Subword 翻译
本文背后的主要动机是,某些单词的翻译是透明的,因为它们可以由一位称职的翻译人员翻译基于已知的 subword 单元(如语素或音素)翻译,即使它们对他或她来说是新颖的。 翻译可能透明的词类别包括:
• 命名实体。 在共享字母表的语言之间,通常可以将名称从源文本复制到目标文本。 可能需要转录或音译,尤其是在字母或音节不同的情况下。 例:
Barack Obama (English; German)
Барак Обама (Russian)
バラク・オバマ (ba-ra-ku o-ba-ma) (Japanese)
• 同源词和借词。 具有共同起源的同源词和借词可以在语言之间与常规方式不同,因此字符级翻译规则就足够了(Tiedemann, 2012)。 例:
claustrophobia (English)
Klaustrophobie (German)
Клаустрофобия (Klaustrofobiâ) (Russian)
• 形态复杂的单词。 包含多个语素的单词,例如通过复合、附加或变形形成的单词,可以通过单独翻译语素来翻译。 例:
solar system (English)
Sonnensystem (Sonne + System) (German)
Naprendszer (Nap + Rendszer) (Hungarian)
在我们的德国训练数据1中对100种罕见词符(不是50000种最常见类型)的分析中,大多数词符可能通过较小的单元从英语翻译。 我们找到56个复合词、21个名词、6 个借词具有共同的起源 (emancipate → emanzipieren),5 个明显的后缀 (sweetish ‘sweet’ + ‘-ish’ → süßlich ‘süß’ + ‘-lich’)、1 个数字和一个计算机语言标识。
我们的假设是,将稀有单词分割成适当的 subword 单元足以允许神经翻译网络学习透明翻译,并将这些知识概括为翻译和产生看不见的单词。2我们提供经验在第4节和第5节中支持这一假设。 首先,我们讨论不同的 subword 表示。
3.1 相关工作
对于统计机器翻译(SMT),未知单词的翻译已成为深入研究的主题。
大部分未知单词是名称,如果两种语言共享相同的字母表,则可以将其复制到目标文本中。 如果字母不同,则需要音译(Durrani et al., 2014)。 基于字符的翻译和基于短语的模型一起进行了研究,这种模型对于密切相关的语言尤其成功(Vilar et al., 2007; Tiedemann, 2009; Neubig et al., 2012)。
形态复杂的单词如复合词的分割被广泛用于SMT,并且已经研究了各种用于语素分割的算法(Nießen and Ney, 2000; Koehn and Knight, 2003; Virpioja et al., 2007; Stallard et al., 2012)。 通常用于基于短语的SMT的分割算法在分割决策中往往是保守的,而我们的目标是进行积极的分割,允许使用紧凑的网络词汇进行开放式词汇翻译,而不必诉诸回退词典。
subword 单元的最佳选择可以是任务特定的。 对于语音识别,已经使用了电话级别语言模型(Bazzi and Glass, 2000)。 Mikolov et al. (2012) 调查 subword 语言模型,并建议使用音节。 对于多语言分段任务,已经提出了多语言算法(Snyder and Barzilay, 2008)。 我们发现这些有趣,但在测试时不适用。
已经提出了各种技术来基于字符或语素产生固定长度的连续单词向量(Luong et al., 2013; Botha and Blunsom, 2014; Ling et al., 2015a; Kim et al., 2015)。 与我们的方法相似,将这些技术应用于NMT的努力没有发现比基于单词的方法有显着改进(Ling et al., 2015b)。 与我们的工作的一个技术差异是,attention 机制仍然在Ling et al. (2015b)的模型中的单词级别上运行,并且每个单词的表示是固定长度的。 我们期望注意机制受益于我们的可变长度表示:网络可以学习在每一步将 attention 集中在不同的 subword 单元上。 回想一下我们的介绍性示例 Abwasserbehandlungsanlange,对于这个单词 subword 字段分割避免了固定长度表示的信息瓶颈。
神经网络机器翻译与基于短语的方法的不同之处在于,有强烈的动机来最小化神经网络模型的词汇量,以增加时间和空间效率,并允许在没有回退模型的情况下进行翻译。 同时,我们还需要文本本身的紧凑表示,因为文本长度的增加会降低效率并增加神经网络模型需要传递信息的距离。
操纵词汇量大小和文本大小之间权衡的简单方法是使用未分段词的短列表,subword 单元用于罕见词。 作为替代方案,我们提出了一种基于字节对编码(BPE)的分割算法,它可以让我们学习一种能够提供良好文本压缩率的词汇表。
3.2 字节对编码(BPE)
字节对编码(BPE) (Gage, 1994)是一种简单的数据压缩技术,它迭代地用一个未使用的字节替换序列中最频繁的字节对。 我们将此算法用于分词。 我们不是合并频繁的字节对,而是合并字符或字符序列。
首先,我们用字符词汇表初始化符号词汇表,并将每个单词表示为一个字符序列,再加上一个特殊的词尾符号'·',这样我们就可以在翻译后恢复原始的标记化。 我们迭代地计算所有符号对,并用新符号“AB”替换最频繁对(‘A’, ‘B’)的每次出现。 每个合并操作都会生成一个代表字符n-gram的新符号。 频繁的字符n-gram(或整个单词)最终合并为单个符号,因此BPE不需要短的列表。 最终的符号词汇量大小等于初始词汇表的大小,加上合并操作的数量 — 后者是算法的唯一超参数。
为了提高效率,我们不考虑跨越单词边界的对。 因此,算法可以在从文本中提取的字典上运行,每个单词根据其频率取权重。 算法1中显示一个最小的Python实现。 实际上,我们通过索引所有符号对来增加效率,并逐步更新数据结构。

与其他压缩算法的主要区别在于,我们的符号序列仍然可以解释为 subword 单元,并且网络可以泛化以在这些 subword 单元的基础上翻译和产生(在训练时未见过的)新单词,而霍夫曼编码的提出是为NMT生成单词的可变长度编码(Chitnis and DeNero, 2015)。
图1显示了学习BPE操作的玩具示例。 在测试时,我们首先将单词拆分为字符序列,然后应用学习到的操作将字符合并为更大的已知符号。 这适用于任何单词,并允许具有固定符号词汇表的开放词汇网络。3 在我们的示例中,OOV“lower”将被分词为“low er·”。

图1:从字典{‘low’, ‘lowest’, ‘newer’, ‘wider’}学习到的BPE合并操作。
我们评估两种应用BPE的方法:学习两个独立的编码,一个用于源词汇,一个用于目标词汇,或者学习联合两个词汇的编码(我们称之为联合BPE)。 4 前者具有在文本和词汇量方面更紧凑的优点,并且具有更强的保证每个 subword 单元已在相应语言的训练文本中被看到,而后者提高了源词汇和目标词汇之间分词的一致性。 如果我们独立地应用BPE,则相同的名称可能在两种语言中被不同地分段,这使得神经网络模型更难以学习 subword 单元之间的映射。 为了提高英语和俄语之间分词的一致性,尽管有不同的字母表,我们将俄语词汇用ISO-9音译成拉丁字符,然后将BPE合并操作音译回西里尔语,将它们应用到俄语培训文本中,以学习联合BPE编码。5
4 评估
我们的目标是回答以下经验问题:
• 我们是否可以通过 subword 单元表示改进神经网络机器翻译中稀有和未见过的单词的翻译?
• 在词汇大小、文本大小和翻译质量方面,哪种 subword 分词的表现最佳?
我们对来自WMT 2015共享翻译任务的数据进行实验。 对于英语→德语,我们的训练集包含420万个句子对,或大约1亿个词符。 对于英语→俄语,训练集包含260万个句子对,或约5000万个词符。 我们使用 Moses 提供的脚本来 tokenize 和 truecase 数据(Koehn et al., 2007)。 我们使用newstest2013作为开发集,并在newstest2014和newstest2015上报告结果。
我们用BLEU报告结果(mteval-v13a.pl)和CHR F3(Popovi'c,2015),一个字符n-gram F 3得分被发现与人类判断相关,特别是对于翻译而言英语(Stanojevi'c等,2015)。 由于我们主要声明的是涉及罕见和未见过的单词的翻译,我们会报告这些单独的统计数据。 我们使用 unigram F1 指标, which we calculate as the harmonic mean of clipped unigram precision and recall.6
我们使用 Groundhog7 (Bahdanau et al., 2015) 进行所有的实验。 我们通常遵循先前工作的设置(Bahdanau et al., 2015; Jean et al., 2015)。 所有网络的隐藏层大小为1000,嵌入层大小为620。 依据Jean et al. (2015),我们只在内存中保留τ = 30000字的较短的单词列表。
在训练期间,我们使用Adadelta (Zeiler, 2012)、批次大小为80、并在周期之间重新洗乱训练集。 我们训练一个网络大约7天,然后采取最后保存的4个模型(模型每12小时保存一次),并继续训练每个固定嵌入层12小时(如 Jean et al., 2015所建议)。 我们为每个模型执行两次独立的训练,一次用5.0的梯度修剪(Pascanu et al., 2013),一次截止为1.0 — 后者在大多数情况下产生更好的单一模型。 我们报告在我们的开发集(newstest2013)上以及所有8个模型的集合中表现最佳的系统的结果。
我们使用 beam size 12 进行beam search,概率按句子长度归一化。 我们使用基于快速对齐的双语词典(Dyer et al., 2013)。 对于我们的基线,它作为稀有单词的回退字典。 我们还使用字典来加速所有实验的翻译,仅在过滤的候选翻译列表上执行softmax(like Jean et al. (2015),我们使用K = 30000; K′ = 10)。
4.1 Subword 统计
除了翻译质量我们将根据经验进行验证,我们的主要目标是通过紧凑的固定大小的 subword 词汇表来表示开放词汇,并允许有效的训练和解码。8
表1列出并行数据中德语的不同分词的统计数据。 一个简单的基线就是将单词分词为 n-grams 字符。9 n-grams 字符允许在序列长度(# token)和词汇量大小(# clales)之间进行不同的权衡,具体取决于 n 的选择。序列长度的增加很大;减少序列长度的一种方法是让 k 个最常见的单词类型不分词。 只有unigram表示才是真正的开放式词汇。 然而,unigram表示在初步实验中表现不佳,我们使用 bigram 表示报告翻译结果,这在经验上更好,但是在训练集词汇表的测试集中无法产生一些词符。
我们报告几种分词技术的统计数据,这些技术在以前的SMT研究中证明是有用的,包括基于频率的复合词分解(Koehn and Knight, 2003)、基于规则的连字符(Liang, 1983)和 Morfessor(Creutz and Lagus, 2002)。 我们发现他们只是适度减少了词汇量,并没有解决未知单词问题,因此我们发现它们不适合我们的开放式词汇翻译目标而没有后退词典。
BPE符合我们开放词汇的目标,学习到的合并操作可以应用于测试集,以获得没有未知符号的分词。10 它与字符级模型的主要区别在于BPE的更紧凑的表示允许更短的序列,并且注意模型在可变长度单元上运行。11 表1示出了具有59 500个合并操作的BPE,以及具有89 500个操作的联合BPE。
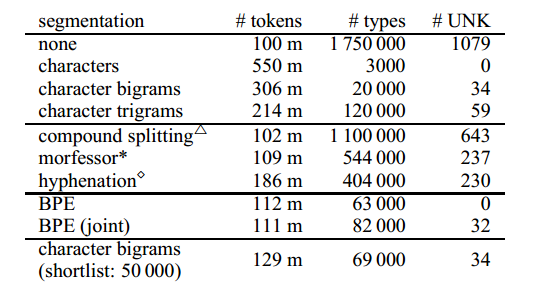
表1:具有不同分词技术的德语训练语料库的语料库统计。 #UNK:newstest2013中未知词符的数量。 △: (Koehn and Knight, 2003); *:(Creutz and Lagus, 2002); ⋄: (Liang, 1983).
在实践中,我们没有在NMT网络词汇表中包括不频繁的 subword 单元,因为在 subword 符号集中存在噪声,例如因为外国字母表中的字符。 因此,表2中的网络词汇表通常略小于表1中的类型数量。
4.2 翻译实验
英语→德语翻译结果如表2所示;英语→俄语结果见表3。
我们的基线WDict是一个带有回退字典的单词级别模型。 它与WUnk的不同之处在于后者不使用回退字典,而只是表示词汇外单词为UNK 12。 对于罕见和未见过的单词,回退字典改进了 unigram F1,尽管英语→俄语的改进较小,因为回退字典无法音译名称。
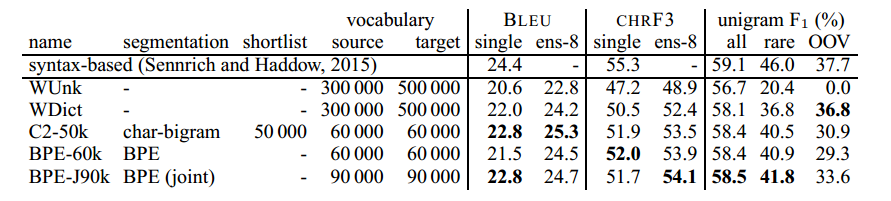
表2:newstest2015上的英语→德语翻译性能(BLEU、CHRF3和unigram F1)。 Ens-8:8种模型的集成。 最好的NMT系统以粗体显示。 Unigram F1(带有集成)计算所有单词(n = 44085),罕见单词(不在训练集中的前50 000中; n = 2900)和OOV(不在训练集中; n = 1168)。
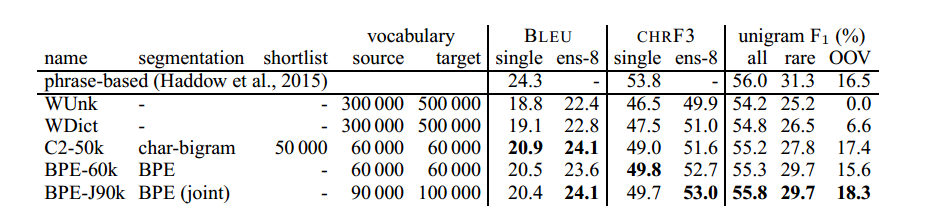
表3:newstest2015上的英语→俄语翻译性能(BLEU、CHRF3和unigram F1)。 Ens-8:8种模型的集成。 最好的NMT系统以粗体显示。 Unigram F1(带有合奏)计算所有单词(n = 55654),罕见单词(不在训练集中的前50 000中; n = 5442)和OOV(不在训练集中; n = 851)。
所有子字系统都在没有回退字典的情况下运行。 We first focus on unigram F1, where all systems improve over the baseline, especially for rare words (36.8%→41.8% for EN→DE; 26.5%→29.7% for EN→RU). 对于OOV,复制未知单词的基线策略适用于英语→德语。 但是,当字母不同时如英语→俄语,subword 模型的性能要好得多。
Unigram F 1分数表明学习词汇联盟(BPE-J90k)上的BPE符号比单独学习BPE符号(BPE-60k)更有效,并且比使用角色名单中的字符bigrams更有效。 50000个未分段的单词(C2-50k),但所有报告的子词分段都是可行的选择,并且优于后退词典基线。
我们的子词表示在罕见和看不见的单词的翻译中引起了很大的改进,但这些只占测试集的9-11%。 Since rare words tend to carry central information in a sentence, we suspect that BLEU and CHRF3 underestimate their effect on translation quality. Still, we also see improvements over the baseline in total unigram F1, as well as BLEU and CHRF3, and the subword ensembles outperform the WDict baseline by 0.3–1.3 BLEU and 0.6–2 CHRF3. 在BLEU和CHR F3之间存在一些不一致,我们认为BLEU具有精确偏差,而CHR F3是一种回忆偏差。
对于英语→德语,我们观察到最佳BLEU得分为25.3,C2-50k,但最好的CHR F3得分为54.1,BPE-J90k。 为了与该数据集上的(据我们所知)最佳非神经MT系统进行比较,我们报告了基于语法的SMT结果(Sennrich和Haddow,2015)。 我们观察到我们的最佳系统在BLEU方面优于基于语法的系统,但在CHR F3方面则不然。 关于其他神经系统,Luong等。 (2015a)在newstest2015报告BLEU得分为25.9,但我们注意到他们使用了8个独立训练的模型的集合,并且还报告了应用辍学的强大改进,我们没有使用。 我们相信,我们对稀有词汇翻译的改进与通过网络架构,训练算法或更好的集合中的其他改进可实现的改进是正交的。
对于英语→俄语,最先进的是Haddow等人的基于短语的系统。 (2015年)。 它比我们的WDict基线优于1.5 BLEU。 The subword models are a step towards closing this gap, and BPE-J90k yields an improvement of 1.3 BLEU, and 2.0 CHRF3, over WDict.
作为对我们翻译结果的进一步评论,我们要强调的是,性能变化仍然是NMT的一个开放性问题。 在我们的开发集中,我们观察到不同模型之间最多1个BLEU的差异。 对于单个系统,我们报告在dev(8个中)中表现最佳的模型的结果,其具有稳定效果,但是如何控制随机性在未来的研究中值得进一步关注。
5分析
5.1 Unigram准确性
我们的主要主张是,在单词级NMT模型中,罕见和未知单词的翻译很差,并且子词模型改进了这些单词类型的翻译。 为了进一步说明不同的子词分割对稀有和不可见词的翻译的影响,我们绘制了在训练集中按频率排序的目标词词。13为了分析词汇量的影响,我们还包括系统C2-3 / 500k,这是一个与WDict基线具有相同词汇量的系统,以及用于表示看不见的单词的字符双字母。
图2显示了newstest2015上英德集合系统的结果。 Unigram F1 of all systems tends to decrease for lower-frequency words. The baseline system has a spike in F1 for OOVs, i.e. words that do not occur in the training text. 这是因为大部分OOV都是名称,从源文本到目标文本的副本是英语→德语的好策略。
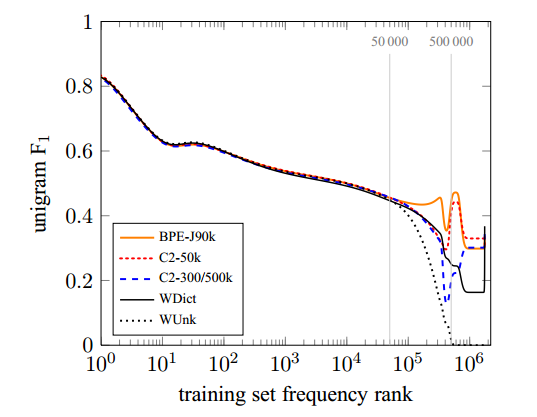
图2:针对不同NMT系统的训练集频率等级绘制的newstest2015上的英语→德语单词F 1。
目标词汇量为500000字的系统在翻译等级> 500000的单词方面差异很大。 退避字典是产生UNK的明显改进,但子字系统C2-3 / 500k实现了更好的性能。 请注意,后退字典产生的所有OOV都是从源复制的单词,通常是名称,而子字系统可以有效地形成新单词,如复合词。
For the 50000 most frequent words, the representation is the same for all neural networks, and all neural networks achieve comparable unigram F1 for this category. 对于频率等级50 000和500000之间的间隔,C2-3 / 500k和C2-50k之间的比较揭示了一个有趣的差异。 两个系统仅在候选名单的大小上有所不同,C2-3 / 500k表示此区间中的单词为单个单元,C2-50k表示通过子单元。 我们发现C2-3 / 500k的性能在很大程度上降低到频率等级500 000,此时模型切换到子字表示并恢复性能。 C2-50k的性能仍然更稳定。 我们将此归因于子字单元比单词稀疏的事实。 在我们的训练集中,频率等级50 000对应于训练数据中的频率60;频率等级为500 000,频率为2。 因为子字表示不那么稀疏,减小网络词汇量的大小,并通过子字单元表示更多单词,可以带来更好的性能。
F 1数字隐藏了系统之间的一些定性差异。 对于英语→德语,WDict产生的OOV很少(26.5%的召回率),但精度很高(60.6%),而子词系统的召回率更高,但精度更低。 我们注意到字符二元模型C2-50k产生的OOV字数最多,并且该类别的精度相对较低,为29.1%。 但是,它在召回时的表现优于后退词典(33.0%)。 由于分段不一致而遭受音译(或复制)错误的BPE-60k获得了稍微好一点的精确度(32.4%),但回忆率更差(26.6%)。 与BPE-60k相比,BPE-J90k的联合BPE编码提高了精度(38.6%)和召回率(29.8%)。
对于英语→俄语,未知名称很少被复制,通常需要音译。 因此,WDict基线对OOV的表现较差(9.2%的精确度; 5.2%的召回率),并且子词模型提高了精度和召回率(BPE-J90k的精度为21.9%,召回率为15.6%)。 完整的单字符F 1图如图3所示。
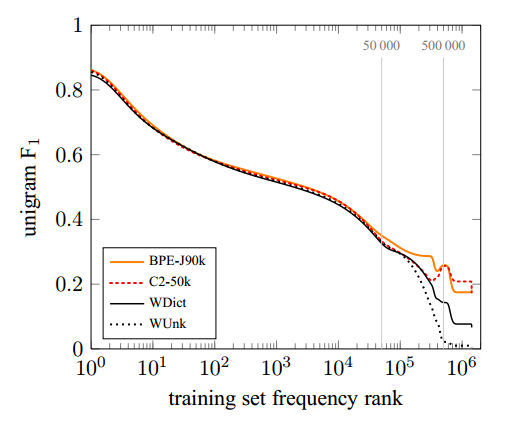
图3:newstest2015上的英语→俄语单词F 1由不同NMT系统的训练集频率等级绘制。
5.2手动分析
表4显示了英语→德语的翻译方向的两个翻译示例,英语→俄语的表5。 所有示例的基线系统都失败,要么删除内容(health),要么复制应翻译或音译的源词。 健康研究所的子词翻译表明,子词系统能够在过度分裂时学习翻译(研究→Fo | rs | ch | un | g),或者分词与词素边界不匹配:分词Forschungs | instituten在语言上更合理,更易于与英语研究机构对齐,而不是分词Forsch |在BPE-60k系统中,ungsinstitu | 10,但仍然会产生正确的翻译。 如果系统由于数据稀疏而无法学习翻译,例如asinine,应该翻译为dumm,我们看到翻译错误,但可能看似合理(部分)借词(asinine情况→Asinin-Situation)。
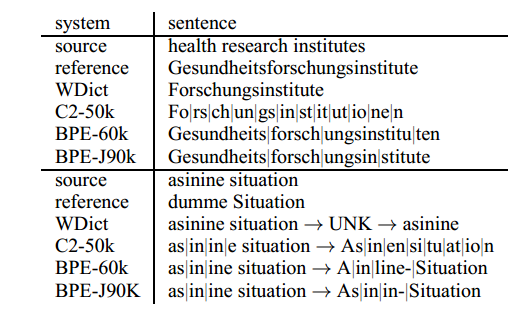
表4:英语→德语翻译示例。 “|”标记子字边界。
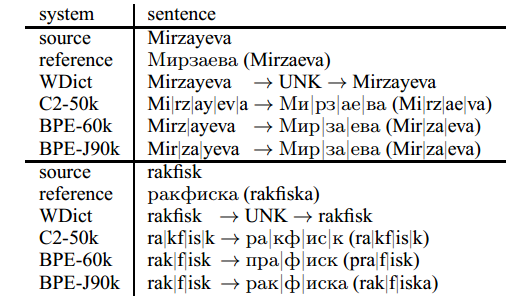
表5:英语→俄语翻译示例。 “|”标记子字边界。
英语→俄语示例表明子词系统能够进行音译。 然而,音译错误确实发生,或者是由于模糊的音译,或者是因为源文本和目标文本之间的不一致的分段,这使得系统难以学习音译映射。 请注意,BPE-60k系统对两个语言对(Mirz | ayeva→Мир|за|еваMir| za | eva)的编码Mirzayeva不一致。 此示例仍然正确翻译,但我们观察到BPE-60k系统中的字符虚假插入和删除。 一个例子是rakfisk的音译,其中插入了п并删除了к。 我们将这个错误追溯到训练数据中的翻译对,并且分段不一致,例如(p | rak | ri | ti→пра|крит|и(pra | krit | i)),错误地学习了翻译(rak→пра)。 联合BPE系统(BPE-J90k)的分割更加一致(pra | krit | i→пра|крит|и(pra | krit | i))。
6 结论
本文的主要贡献在于,我们通过将稀有和未见过的单词表示为一个 subword 序列来表明神经网络机器翻译系统能够进行开放式词汇翻译。14 这比使用一个回退字典翻译模型既简单又有效。 我们引入用于分词的字节对编码的变体,其能够使用可变长度 subword 单元的紧凑符号词汇来编码开放词汇表。 通过BPE 分词和简单的字符二元分词,我们显示比基线的性能有所提升。
我们的分析表明,通过我们的基线NMT系统,不仅词汇外单词,而且罕见的词汇表单词也很难翻译,并且减少子词模型的词汇量大小实际上可以提高性能。 在这项工作中,我们对词汇量的选择有些武断,主要是与先前的工作相比较。 未来研究的一个途径是学习翻译任务的最佳词汇量,我们期望自动依赖于语言对和训练数据量。 我们还相信,双语通知的分段算法还有潜力创建更多可对齐的子字单元,尽管分段算法不能在运行时依赖目标文本。
虽然相对有效性将取决于语言特定因素,如词汇量大小,但我们认为子词分割适用于大多数语言对,从而无需大型NMT词汇表或退避模型。
致谢
我们感谢Maja Popovic 实现CHRF,我们用它来验证我们的重新实现。 The research presented in this publication was conducted in cooperation with Samsung Electronics Polska sp. z o.o. Samsung R&D Institute Poland. 该项目获得了欧盟“地平线2020”研究和创新计划的拨款,资助协议为645452(QT21)。
1主要是议会程序和网络爬行数据。
2并非我们生成的每个细分都是透明的。 虽然我们预计不透明分段没有性能优势,即单元无法独立转换的分段,但我们的NMT模型显示出对过度分裂的稳健性。
3在测试时未知的唯一符号是未知字符,或者训练文本中所有出现的符号已合并为较大符号的符号,如“safeguar”,其中我们的训练文本中的所有出现都合并为“safeguard” 。 我们在测试时没有观察到这样的符号,但是通过递归地反转特定的合并直到所有符号都已知,可以很容易地解决该问题。
4在实践中,我们简单地连接训练集的源侧和目标侧以学习联合BPE。
5由于俄语培训文本中还包含使用拉丁字母的单词,因此我们也应用拉丁语BPE操作。
6 剪裁的 unigram 精度基本上是1-gram BLEU,没有brevity penalty。
7 github.com/sebastien-j/LV_groundhog
8编码器 - 解码器架构的时间复杂度至少与序列长度成线性关系,而过度分裂会损害效率。
9 我们的 n-grams 字符不会跨越单词边界。 我们用特殊字符标记 subword 是否为最终单词,这样我们就可以恢复原始的词符。
10联合BPE可以产生未知的段,因为它们仅出现在英语培训文本中,但这些很少见(0.05%的测试令牌)。
11我们在第3.1节强调了词级关注的局限性。 在光谱的另一端,角色水平对齐不太理想(Tiedemann,2009)。
12 我们将UNK用于模型词汇表之外的单词,对于那些未在训练文本中出现的单词使用OOV。
13我们使用相同的训练集频率执行单词的分级,并将bezier平滑应用于图形。
14 分词算法的源代码可在 https://github.com/rsennrich/subword-nmt 获得。