打赏本站
微信
 支付宝
支付宝

支付宝
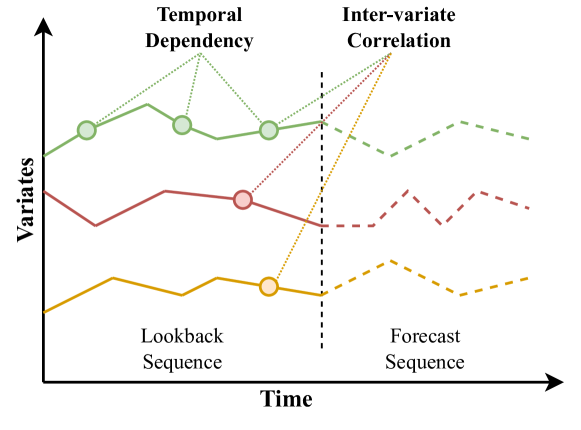
在时间序列预测 (TSF) 领域,Transformer 始终表现出强大的性能,因为它能够关注全局上下文并有效捕获时间范围内的长期依赖性,以及辨别多个变量之间的相关性。然而,由于 Transformer 模型的效率低下以及围绕其捕获依赖关系的能力的问题,改进 Transformer 架构的持续努力仍在继续。最近,状态空间模型(SSM),例如 ...
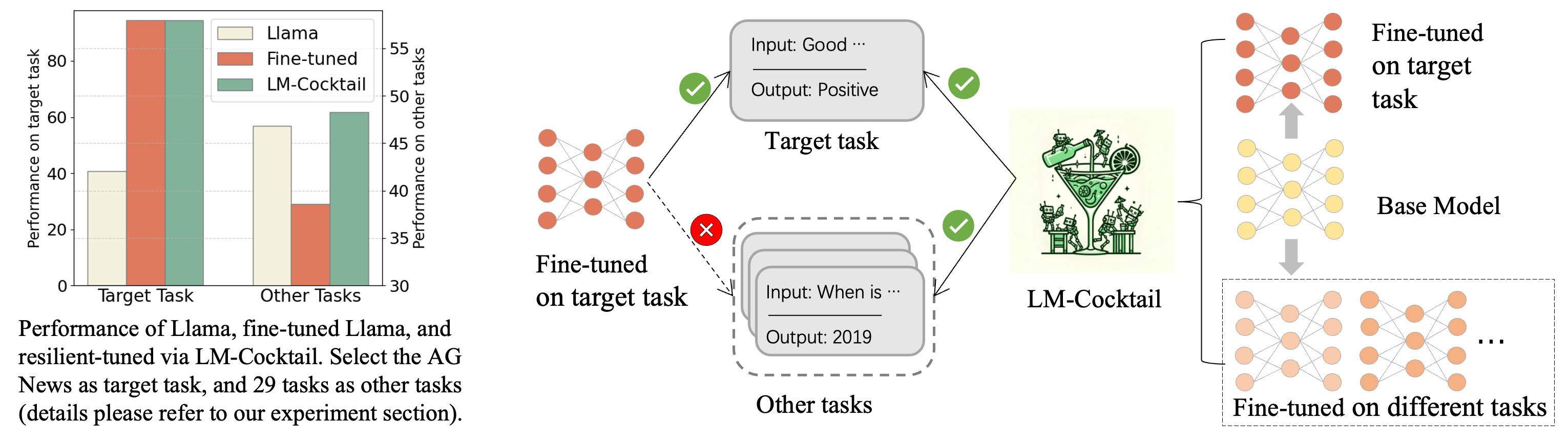
预训练的语言模型不断进行微调,以更好地支持下游应用程序。然而,此操作可能会导致超出目标域的一般任务的性能显着下降。为了克服这个问题,我们提出了 LM-Cocktail,它使微调后的模型能够在总体角度上保持弹性 ...
现实世界的应用程序通常需要大量共享一致主题的 3D 资源。虽然从文本或图像创建一般 3D 内容已经取得了显着的进步,但按照输入 3D 示例的共享主题合成定制 3D 资产仍然是一个开放且具有挑战性的问题。在这项工作中,我们提出了 ThemeStation,这是一种用于主题感知 3D 到 3D 生成的新颖方法 ...

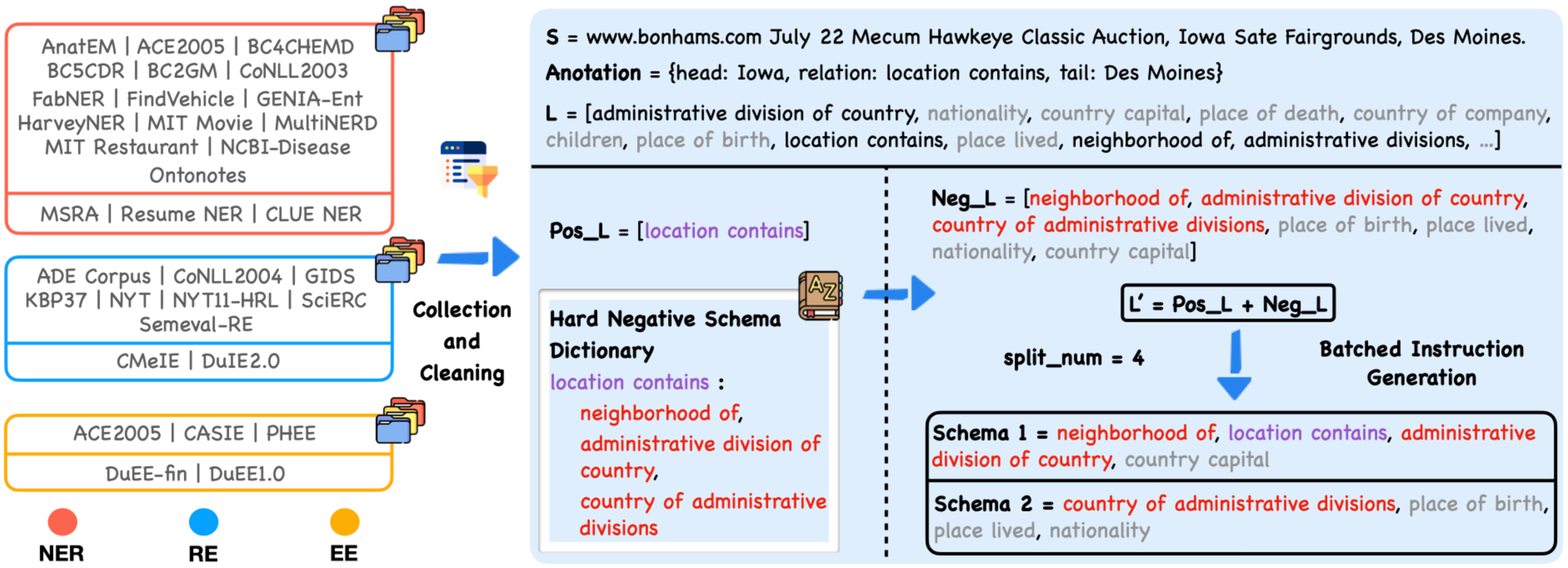
大型语言模型(LLM)在各个领域都展现出巨大的潜力;然而,它们在信息提取(IE)方面表现出显着的性能差距。需要注意的是,高质量的教学数据是提升LLM专业能力的关键,而目前的IE数据集往往规模小、碎片化、缺乏标准化模式。为此,我们引入了IEPile,一个综合性双语(英文和中文)IE指令语料库,其中包含约0. ...
与人类偏好保持一致可以防止大型语言模型 (LLM) 生成误导性或有毒内容,同时需要高成本的人类反馈。假设人类注释资源有限,有两种不同的分配方式可供考虑:更多样化的提示或更多样化的待标记响应。尽管如此,它们的影响之间还没有直接的比较 ...

在处理 3D 面部数据时,提高保真度并避免恐怖谷效应在很大程度上取决于准确的 3D 面部表情捕捉。由于此类方法成本高昂且 2D 视频广泛可用,因此最近的方法主要集中在如何执行单目 3D 面部跟踪。然而,由于网络架构、训练和评估过程的限制,这些方法通常无法捕捉精确的面部运动 ...

最近使用神经辐射场(NeRF)进行音频驱动的头部说话合成的工作取得了令人印象深刻的成果。然而,由于 NeRF 隐式表示导致的姿势和表情控制不足,这些方法仍然存在一些局限性,例如不同步或不自然的嘴唇运动,以及视觉抖动和伪影。在本文中,我们提出了 GaussianTalker,一种基于 3D 高斯分布的音频驱动头部说话合成的新方法 ...

在一次性设置下进行面部表情迁移在研究界越来越受欢迎,重点关注表情的精确控制。现有技术在感知表情方面展示了令人信服的结果,但它们缺乏对极端头部姿势的鲁棒性。他们还难以准确地重建背景细节,从而阻碍了真实感 ...
