打赏本站
微信
 支付宝
支付宝

支付宝
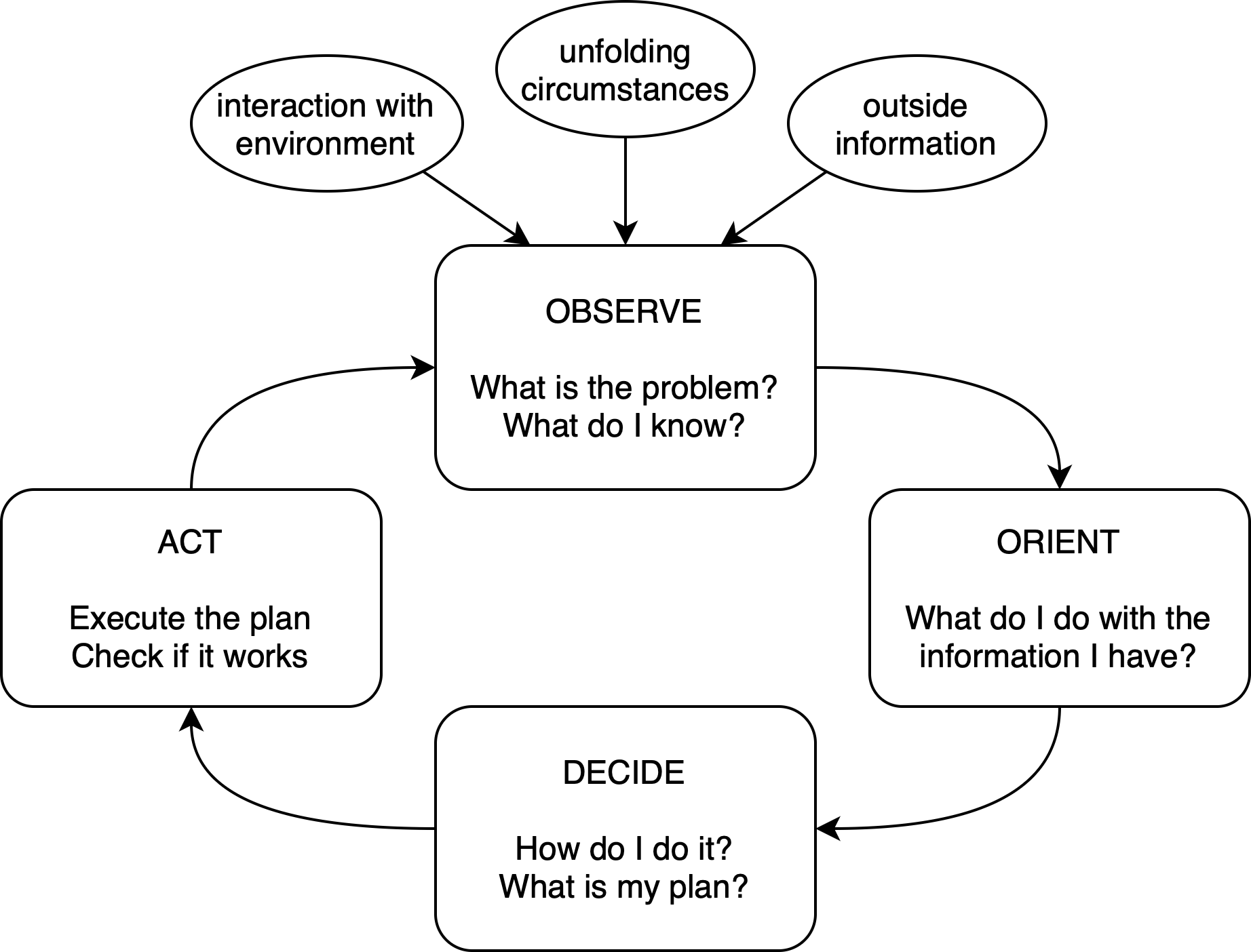
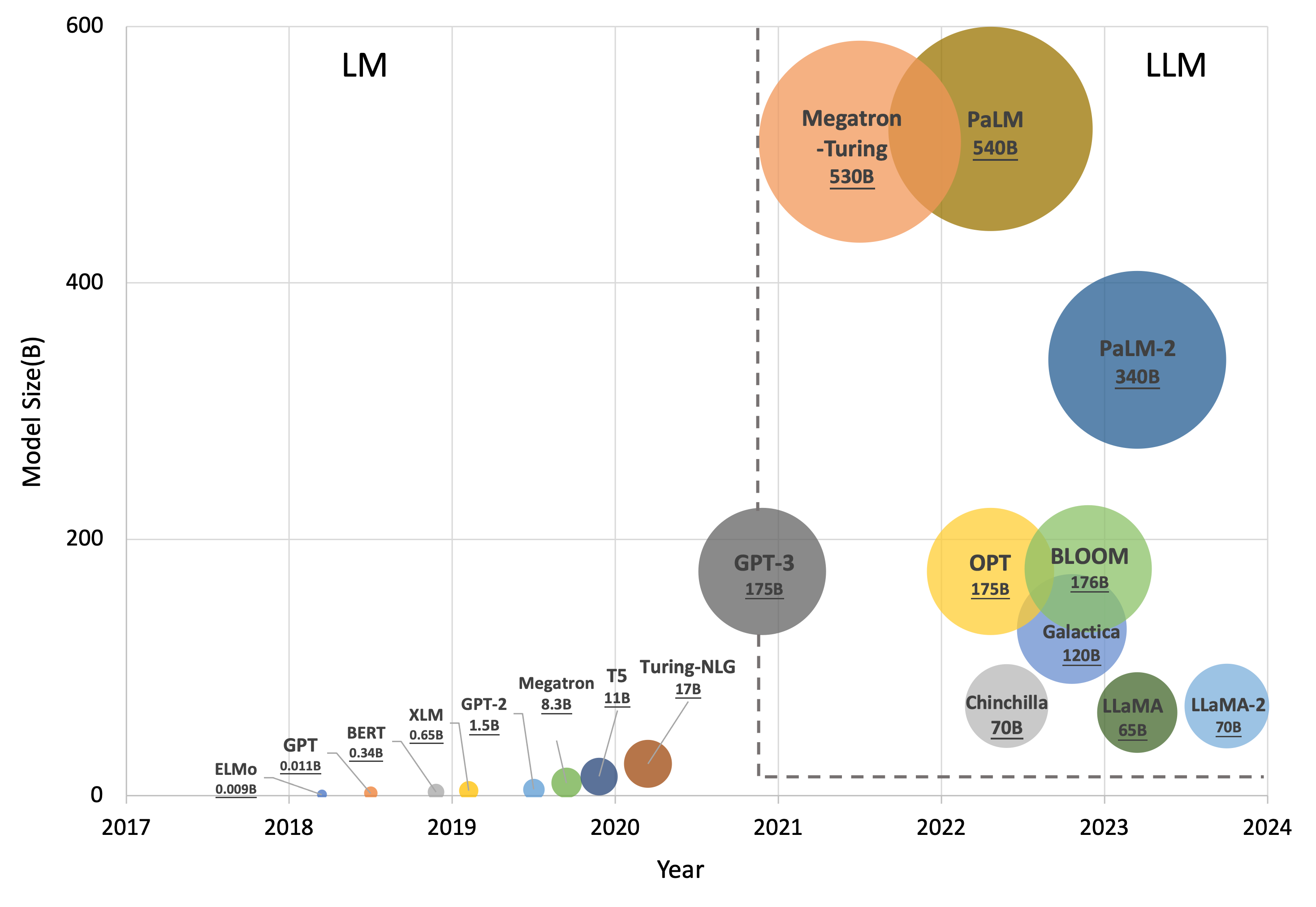
由于大型语言模型 (LLM) 在众多下游 NLP 任务中表现出的非凡功效,文本分类未来研究的价值遇到了挑战和不确定性。在这个开放式语言建模的时代,任务界限逐渐消失,一个紧迫的问题出现了:在 LLM 的充分帮助下,我们在文本分类方面是否取得了重大进展?为了回答这个问题,我们提出了 RGPT,这是一种自适应增强框架,旨在通过循环集成一组强基础学习器来生成专门的文本分类 LLM。基础学习器是通过自适应调 ...
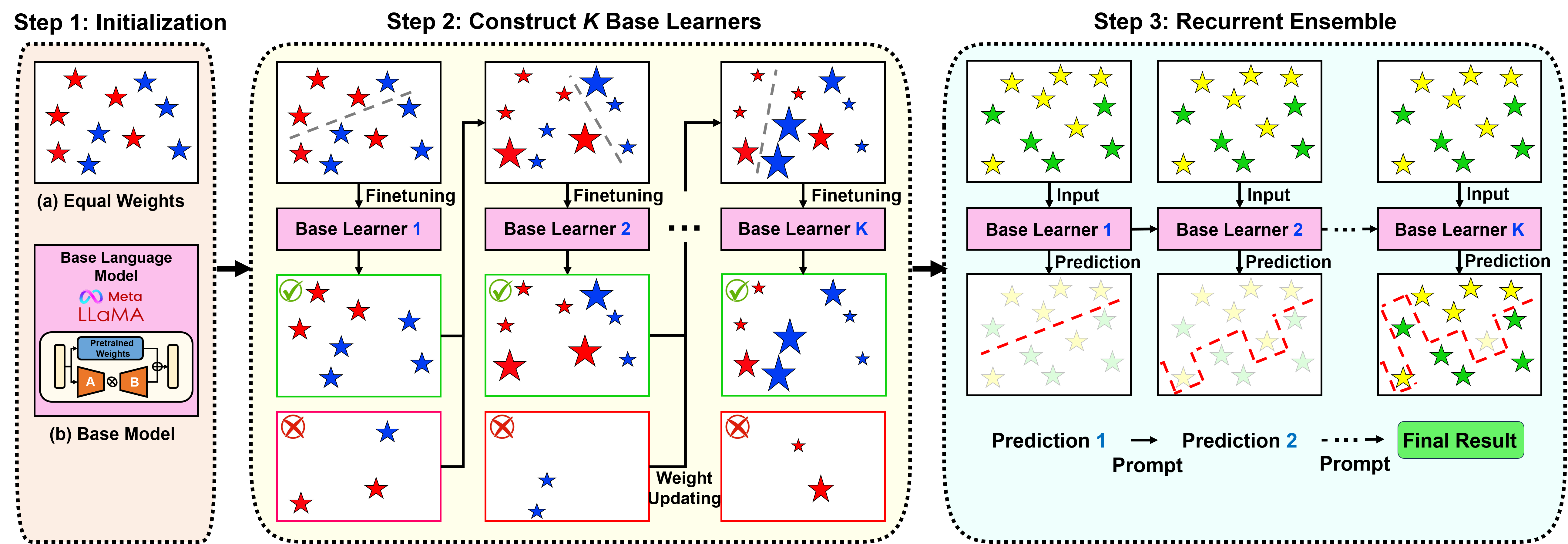
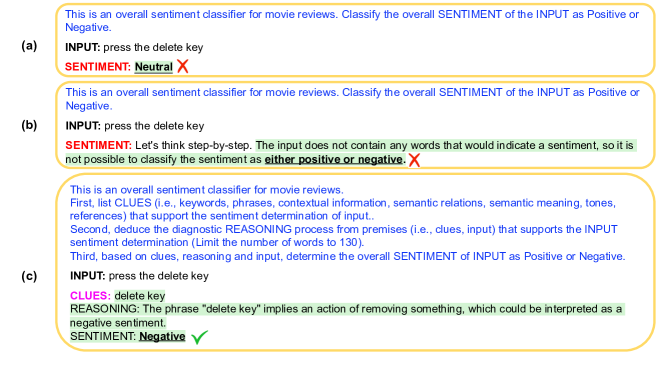
尽管 GPT-3 等大规模语言模型 (LLM) 取得了显着的成功,但它们在文本分类任务中的性能仍然明显低于微调模型。这是由于(1)缺乏解决复杂语言现象的推理能力(例如, ...
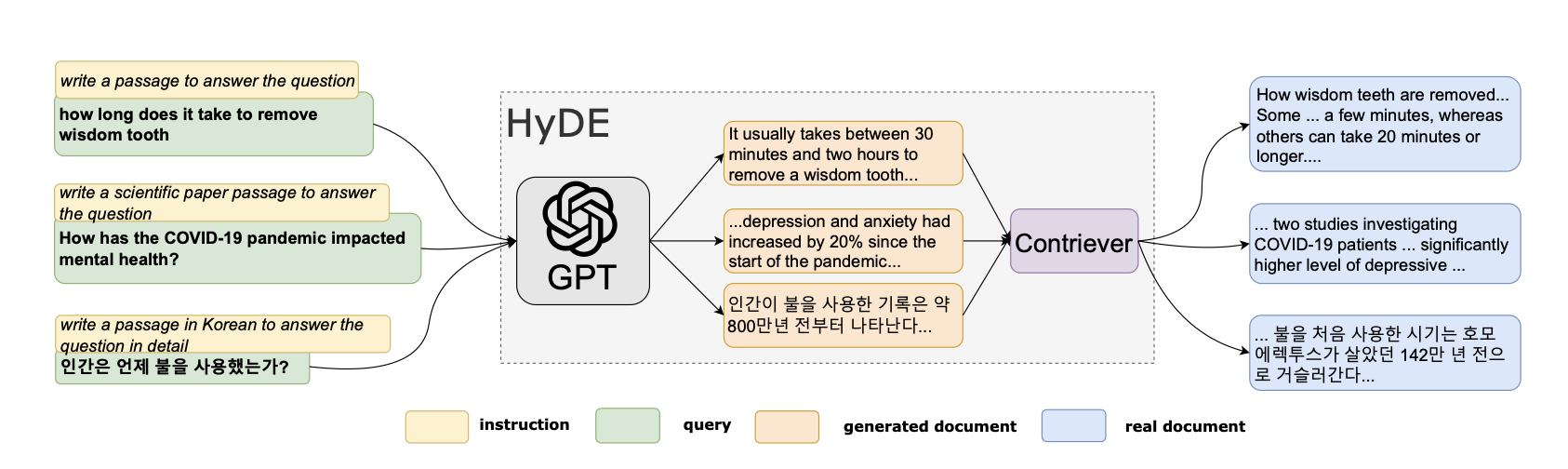
现有的开放域问答(QA)模型不适合实时使用,因为它们需要针对每个输入查询按需处理多个长文档。在本文中,我们介绍了与查询无关的文档短语可索引表示,它可以大大加快开放域 QA 的速度,并允许我们达到长尾目标。特别是,我们的密集稀疏短语编码有效地捕获了短语的句法、语义和词汇信息,并消除了上下文文档的管道过滤 ...

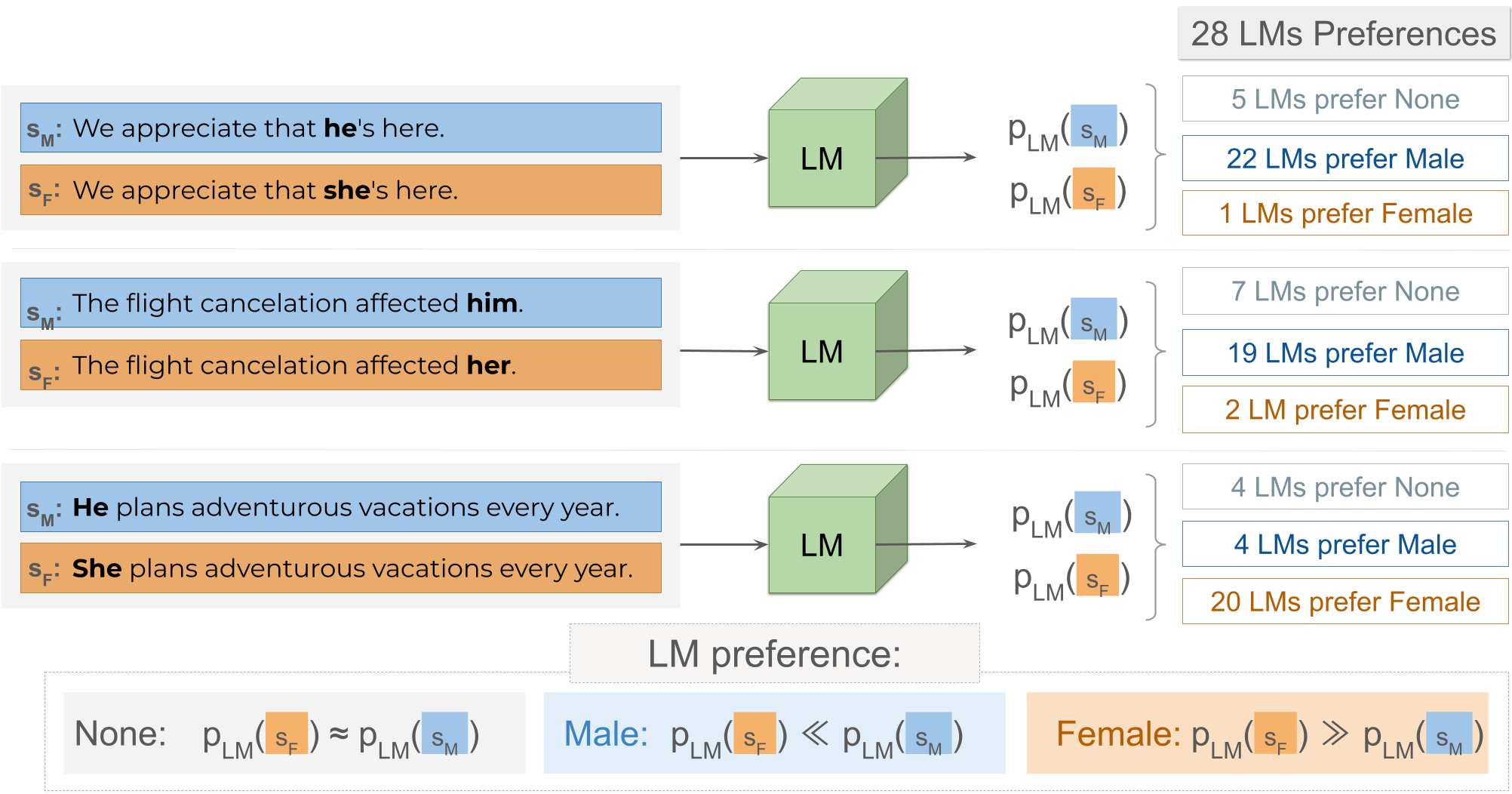
性别偏见研究在揭示大型语言模型中的不良行为、揭露与职业和情感相关的严重性别刻板印象方面发挥着关键作用。先前工作中的一个关键观察结果是,由于训练数据中存在的性别相关性,模型强化了刻板印象。在本文中,我们重点关注训练数据的影响尚不清楚的偏见,并解决以下问题:语言模型在非刻板印象环境中是否仍然表现出性别偏见?为此,我们引入了 UnStereoEval (USE),这是一个专为调查无刻板印象场景中的性别偏 ...
即使 BERT 等预训练语言编码器在许多任务中共享,问答、文本分类和回归模型的输出层也有显着不同。跨度解码器经常用于问答、固定类、文本分类的分类层以及回归任务的相似性评分层。我们表明这种区别是没有必要的,并且所有三者都可以统一为跨度提取。统一的跨度提取方法可以在多个问答、文本分类和回归基准的补充监督预训练、低数据和多任务学习实验中带来优异或相当的性能 ...

大型语言模型 (LLM) 在医疗保健领域的使用既令人兴奋又令人担忧,因为它们能够有效地响应具有一定专业知识的自由文本查询。本次调查概述了当前开发的医疗保健 LLM 的能力,并阐述了其开发流程,旨在概述从传统预训练语言模型(PLM)到 LLM 的发展路线图。具体来说,我们首先探讨 LLM 在提高各种医疗保健应用程序的效率和有效性方面的潜力,强调其优点和局限性 ...
大型语言模型 (LLM) 生成准确响应的有效性在很大程度上依赖于所提供输入的质量,特别是在采用检索增强生成 (RAG) 技术时。 RAG 通过寻找最相关的文本块作为查询基础来增强 LLM 。尽管近年来 LLM 的回答质量取得了显着进步,但用户仍然可能会遇到不准确或不相关的答案;这些问题通常源于 RAG 的次优文本块检索,而不是 LLM 的固有能力 ...
本文研究了特定领域模型微调和推理机制对由大型语言模型 (LLM) 和检索增强生成 (RAG) 驱动的问答 (Q&A) 系统性能的影响。使用 FinanceBench SEC 财务申报数据集,我们观察到,对于 RAG,将微调嵌入模型与微调 LLM 相结合可实现比通用模型更好的准确性,并且微调嵌入模型带来的收益相对较大。此外,在 RAG 之上采用推理迭代可以实现更大的性能飞跃,使问答系统更接近人类专家 ...