


Note
Click here to download the full example code
Sequence-to-Sequence Modeling with nn.Transformer and TorchText¶
This is a tutorial on how to train a sequence-to-sequence model that uses the nn.Transformer module.
PyTorch 1.2 release includes a standard transformer module based on the
paper Attention is All You
Need. The transformer model
has been proved to be superior in quality for many sequence-to-sequence
problems while being more parallelizable. The nn.Transformer module
relies entirely on an attention mechanism (another module recently
implemented as nn.MultiheadAttention) to draw global dependencies
between input and output. The nn.Transformer module is now highly
modularized such that a single component (like nn.TransformerEncoder
in this tutorial) can be easily adapted/composed.
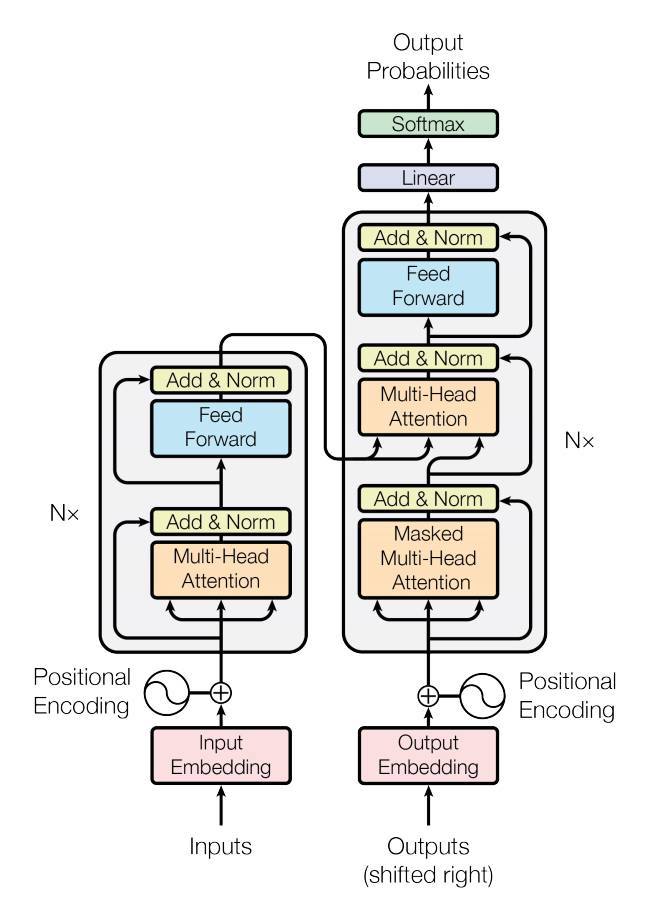
Define the model¶
In this tutorial, we train nn.TransformerEncoder model on a
language modeling task. The language modeling task is to assign a
probability for the likelihood of a given word (or a sequence of words)
to follow a sequence of words. A sequence of tokens are passed to the embedding
layer first, followed by a positional encoding layer to account for the order
of the word (see the next paragraph for more details). The
nn.TransformerEncoder consists of multiple layers of
nn.TransformerEncoderLayer. Along with the input sequence, a square
attention mask is required because the self-attention layers in
nn.TransformerEncoder are only allowed to attend the earlier positions in
the sequence. For the language modeling task, any tokens on the future
positions should be masked. To have the actual words, the output
of nn.TransformerEncoder model is sent to the final Linear
layer, which is followed by a log-Softmax function.
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class TransformerModel(nn.Module):
def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):
super(TransformerModel, self).__init__()
from torch.nn import TransformerEncoder, TransformerEncoderLayer
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(ninp, dropout)
encoder_layers = TransformerEncoderLayer(ninp, nhead, nhid, dropout)
self.transformer_encoder = TransformerEncoder(encoder_layers, nlayers)
self.encoder = nn.Embedding(ntoken, ninp)
self.ninp = ninp
self.decoder = nn.Linear(ninp, ntoken)
self.init_weights()
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src):
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.encoder(src) * math.sqrt(self.ninp)
src = self.pos_encoder(src)
output = self.transformer_encoder(src, self.src_mask)
output = self.decoder(output)
return output
PositionalEncoding module injects some information about the
relative or absolute position of the tokens in the sequence. The
positional encodings have the same dimension as the embeddings so that
the two can be summed. Here, we use sine and cosine functions of
different frequencies.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
Load and batch data¶
The training process uses Wikitext-2 dataset from torchtext. The
vocab object is built based on the train dataset and is used to numericalize
tokens into tensors. Starting from sequential data, the batchify()
function arranges the dataset into columns, trimming off any tokens remaining
after the data has been divided into batches of size batch_size.
For instance, with the alphabet as the sequence (total length of 26)
and a batch size of 4, we would divide the alphabet into 4 sequences of
length 6:
These columns are treated as independent by the model, which means that
the dependence of G and F can not be learned, but allows more
efficient batch processing.
import torchtext
from torchtext.data.utils import get_tokenizer
TEXT = torchtext.data.Field(tokenize=get_tokenizer("basic_english"),
init_token='<sos>',
eos_token='<eos>',
lower=True)
train_txt, val_txt, test_txt = torchtext.datasets.WikiText2.splits(TEXT)
TEXT.build_vocab(train_txt)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def batchify(data, bsz):
data = TEXT.numericalize([data.examples[0].text])
# Divide the dataset into bsz parts.
nbatch = data.size(0) // bsz
# Trim off any extra elements that wouldn't cleanly fit (remainders).
data = data.narrow(0, 0, nbatch * bsz)
# Evenly divide the data across the bsz batches.
data = data.view(bsz, -1).t().contiguous()
return data.to(device)
batch_size = 20
eval_batch_size = 10
train_data = batchify(train_txt, batch_size)
val_data = batchify(val_txt, eval_batch_size)
test_data = batchify(test_txt, eval_batch_size)
Out:
downloading wikitext-2-v1.zip
extracting
Functions to generate input and target sequence¶
get_batch() function generates the input and target sequence for
the transformer model. It subdivides the source data into chunks of
length bptt. For the language modeling task, the model needs the
following words as Target. For example, with a bptt value of 2,
we’d get the following two Variables for i = 0:

It should be noted that the chunks are along dimension 0, consistent
with the S dimension in the Transformer model. The batch dimension
N is along dimension 1.
bptt = 35
def get_batch(source, i):
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].view(-1)
return data, target
Initiate an instance¶
The model is set up with the hyperparameter below. The vocab size is equal to the length of the vocab object.
ntokens = len(TEXT.vocab.stoi) # the size of vocabulary
emsize = 200 # embedding dimension
nhid = 200 # the dimension of the feedforward network model in nn.TransformerEncoder
nlayers = 2 # the number of nn.TransformerEncoderLayer in nn.TransformerEncoder
nhead = 2 # the number of heads in the multiheadattention models
dropout = 0.2 # the dropout value
model = TransformerModel(ntokens, emsize, nhead, nhid, nlayers, dropout).to(device)
Run the model¶
CrossEntropyLoss is applied to track the loss and SGD implements stochastic gradient descent method as the optimizer. The initial learning rate is set to 5.0. StepLR is applied to adjust the learn rate through epochs. During the training, we use nn.utils.clip_grad_norm_ function to scale all the gradient together to prevent exploding.
criterion = nn.CrossEntropyLoss()
lr = 5.0 # learning rate
optimizer = torch.optim.SGD(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
import time
def train():
model.train() # Turn on the train mode
total_loss = 0.
start_time = time.time()
ntokens = len(TEXT.vocab.stoi)
for batch, i in enumerate(range(0, train_data.size(0) - 1, bptt)):
data, targets = get_batch(train_data, i)
optimizer.zero_grad()
output = model(data)
loss = criterion(output.view(-1, ntokens), targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
total_loss += loss.item()
log_interval = 200
if batch % log_interval == 0 and batch > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches | '
'lr {:02.2f} | ms/batch {:5.2f} | '
'loss {:5.2f} | ppl {:8.2f}'.format(
epoch, batch, len(train_data) // bptt, scheduler.get_lr()[0],
elapsed * 1000 / log_interval,
cur_loss, math.exp(cur_loss)))
total_loss = 0
start_time = time.time()
def evaluate(eval_model, data_source):
eval_model.eval() # Turn on the evaluation mode
total_loss = 0.
ntokens = len(TEXT.vocab.stoi)
with torch.no_grad():
for i in range(0, data_source.size(0) - 1, bptt):
data, targets = get_batch(data_source, i)
output = eval_model(data)
output_flat = output.view(-1, ntokens)
total_loss += len(data) * criterion(output_flat, targets).item()
return total_loss / (len(data_source) - 1)
Loop over epochs. Save the model if the validation loss is the best we’ve seen so far. Adjust the learning rate after each epoch.
best_val_loss = float("inf")
epochs = 3 # The number of epochs
best_model = None
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train()
val_loss = evaluate(model, val_data)
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.2f} | '
'valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model = model
scheduler.step()
Out:
| epoch 1 | 200/ 2981 batches | lr 5.00 | ms/batch 124.93 | loss 7.99 | ppl 2949.14
| epoch 1 | 400/ 2981 batches | lr 5.00 | ms/batch 122.26 | loss 6.78 | ppl 878.40
| epoch 1 | 600/ 2981 batches | lr 5.00 | ms/batch 121.36 | loss 6.37 | ppl 582.49
| epoch 1 | 800/ 2981 batches | lr 5.00 | ms/batch 123.27 | loss 6.23 | ppl 505.39
| epoch 1 | 1000/ 2981 batches | lr 5.00 | ms/batch 122.21 | loss 6.11 | ppl 450.76
| epoch 1 | 1200/ 2981 batches | lr 5.00 | ms/batch 122.75 | loss 6.09 | ppl 441.42
| epoch 1 | 1400/ 2981 batches | lr 5.00 | ms/batch 122.13 | loss 6.05 | ppl 422.40
| epoch 1 | 1600/ 2981 batches | lr 5.00 | ms/batch 124.62 | loss 6.05 | ppl 425.40
| epoch 1 | 1800/ 2981 batches | lr 5.00 | ms/batch 126.22 | loss 5.96 | ppl 386.09
| epoch 1 | 2000/ 2981 batches | lr 5.00 | ms/batch 127.20 | loss 5.96 | ppl 388.86
| epoch 1 | 2200/ 2981 batches | lr 5.00 | ms/batch 127.03 | loss 5.85 | ppl 346.01
| epoch 1 | 2400/ 2981 batches | lr 5.00 | ms/batch 127.34 | loss 5.90 | ppl 364.58
| epoch 1 | 2600/ 2981 batches | lr 5.00 | ms/batch 128.40 | loss 5.90 | ppl 365.37
| epoch 1 | 2800/ 2981 batches | lr 5.00 | ms/batch 129.84 | loss 5.80 | ppl 331.25
-----------------------------------------------------------------------------------------
| end of epoch 1 | time: 387.28s | valid loss 5.78 | valid ppl 323.73
-----------------------------------------------------------------------------------------
| epoch 2 | 200/ 2981 batches | lr 4.75 | ms/batch 128.02 | loss 5.79 | ppl 327.90
| epoch 2 | 400/ 2981 batches | lr 4.75 | ms/batch 128.10 | loss 5.77 | ppl 320.35
| epoch 2 | 600/ 2981 batches | lr 4.75 | ms/batch 130.64 | loss 5.60 | ppl 271.34
| epoch 2 | 800/ 2981 batches | lr 4.75 | ms/batch 129.98 | loss 5.64 | ppl 280.59
| epoch 2 | 1000/ 2981 batches | lr 4.75 | ms/batch 131.43 | loss 5.59 | ppl 268.89
| epoch 2 | 1200/ 2981 batches | lr 4.75 | ms/batch 132.91 | loss 5.62 | ppl 276.06
| epoch 2 | 1400/ 2981 batches | lr 4.75 | ms/batch 129.21 | loss 5.63 | ppl 277.27
| epoch 2 | 1600/ 2981 batches | lr 4.75 | ms/batch 128.28 | loss 5.66 | ppl 287.70
| epoch 2 | 1800/ 2981 batches | lr 4.75 | ms/batch 130.00 | loss 5.58 | ppl 266.11
| epoch 2 | 2000/ 2981 batches | lr 4.75 | ms/batch 130.06 | loss 5.62 | ppl 275.50
| epoch 2 | 2200/ 2981 batches | lr 4.75 | ms/batch 131.11 | loss 5.51 | ppl 246.58
| epoch 2 | 2400/ 2981 batches | lr 4.75 | ms/batch 129.66 | loss 5.60 | ppl 269.79
| epoch 2 | 2600/ 2981 batches | lr 4.75 | ms/batch 130.27 | loss 5.59 | ppl 267.55
| epoch 2 | 2800/ 2981 batches | lr 4.75 | ms/batch 128.42 | loss 5.51 | ppl 248.02
-----------------------------------------------------------------------------------------
| end of epoch 2 | time: 400.31s | valid loss 5.57 | valid ppl 263.33
-----------------------------------------------------------------------------------------
| epoch 3 | 200/ 2981 batches | lr 4.51 | ms/batch 130.83 | loss 5.55 | ppl 258.11
| epoch 3 | 400/ 2981 batches | lr 4.51 | ms/batch 129.35 | loss 5.54 | ppl 255.92
| epoch 3 | 600/ 2981 batches | lr 4.51 | ms/batch 129.45 | loss 5.36 | ppl 213.36
| epoch 3 | 800/ 2981 batches | lr 4.51 | ms/batch 128.86 | loss 5.42 | ppl 225.10
| epoch 3 | 1000/ 2981 batches | lr 4.51 | ms/batch 128.21 | loss 5.38 | ppl 216.61
| epoch 3 | 1200/ 2981 batches | lr 4.51 | ms/batch 129.17 | loss 5.42 | ppl 225.47
| epoch 3 | 1400/ 2981 batches | lr 4.51 | ms/batch 128.17 | loss 5.45 | ppl 231.99
| epoch 3 | 1600/ 2981 batches | lr 4.51 | ms/batch 128.30 | loss 5.48 | ppl 240.22
| epoch 3 | 1800/ 2981 batches | lr 4.51 | ms/batch 127.26 | loss 5.41 | ppl 223.74
| epoch 3 | 2000/ 2981 batches | lr 4.51 | ms/batch 128.67 | loss 5.44 | ppl 230.29
| epoch 3 | 2200/ 2981 batches | lr 4.51 | ms/batch 128.46 | loss 5.33 | ppl 206.34
| epoch 3 | 2400/ 2981 batches | lr 4.51 | ms/batch 127.41 | loss 5.41 | ppl 223.09
| epoch 3 | 2600/ 2981 batches | lr 4.51 | ms/batch 134.35 | loss 5.42 | ppl 225.49
| epoch 3 | 2800/ 2981 batches | lr 4.51 | ms/batch 128.57 | loss 5.35 | ppl 210.62
-----------------------------------------------------------------------------------------
| end of epoch 3 | time: 397.84s | valid loss 5.52 | valid ppl 250.16
-----------------------------------------------------------------------------------------
Evaluate the model with the test dataset¶
Apply the best model to check the result with the test dataset.
test_loss = evaluate(best_model, test_data)
print('=' * 89)
print('| End of training | test loss {:5.2f} | test ppl {:8.2f}'.format(
test_loss, math.exp(test_loss)))
print('=' * 89)
Out:
=========================================================================================
| End of training | test loss 5.43 | test ppl 228.85
=========================================================================================
Total running time of the script: ( 33 minutes 24.345 seconds)