去噪自动编码器(dA)¶
Note
本节假设读者已经阅读过使用逻辑回归分析MNIST数字和多层感知器。此外,它使用以下Theano函数和概念:T.tanh、共享变量、基本算术操作、T.grad、随机数,floatX。如果你打算在GPU上运行代码还需阅读GPU。
Note
The code for this section is available for download here.
去噪自动编码器(dA)是经典自动编码器的扩展,它在[Vincent08]中引入,用于深层网络的构建块。我们将以自动编码器的简短讨论开始教程。
自动编码器¶
See section 4.6 of [Bengio09] for an overview of auto-encoders. 自动编码器接受输入![\mathbf{x} \in [0,1]^d](_images/math/4376c3a3f1fc147f4ceccdbf56585351047a502e.png) 并且通过确定性映射首先将其(利用编码器)映射到一个隐藏表示
并且通过确定性映射首先将其(利用编码器)映射到一个隐藏表示![\mathbf{y} \in [0,1]^{d'}](_images/math/be3a6a50757f86aca7f15bbdea1163da6eacb3fa.png) ,即:
,即:
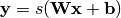
其中 是非线性的,例如sigmoid。然后将潜在表示
是非线性的,例如sigmoid。然后将潜在表示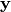 或编码映射回(使用解码器)一个重构
或编码映射回(使用解码器)一个重构 ,它具有与
,它具有与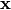 相同的形状。The mapping happens through a similar transformation, e.g.:
相同的形状。The mapping happens through a similar transformation, e.g.:
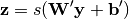
(这里,上标符号不表示矩阵转置。)应被视为的预测,给定编码。Optionally, the weight matrix 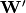 of the reverse mapping may be constrained to be the transpose of the forward mapping:
of the reverse mapping may be constrained to be the transpose of the forward mapping: 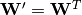 . 这被称为绑定权重。优化该模型的参数(即
. 这被称为绑定权重。优化该模型的参数(即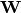 、
、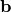 、
、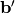 ,如果不使用绑定权重还有),使得平均重构误差最小化。
,如果不使用绑定权重还有),使得平均重构误差最小化。
重构误差可以以许多方式测量,这取决于给定编码时对输入分布的适当假设。The traditional squared error  , can be used. 如果输入被解释为位向量或位概率的向量,则可以使用重构的交叉熵:
, can be used. 如果输入被解释为位向量或位概率的向量,则可以使用重构的交叉熵:
![L_{H} (\mathbf{x}, \mathbf{z}) = - \sum^d_{k=1}[\mathbf{x}_k \log
\mathbf{z}_k + (1 - \mathbf{x}_k)\log(1 - \mathbf{z}_k)]](_images/math/c28b6e7949ec8857a86bf8f7e3f68242c96c4312.png)
有个希望是编码是一个分布式表示,它捕获数据中主要变化因子的坐标。这类似于主成分上的投影将捕获数据中的主要变化因子的方式。实际上,如果存在一个线性隐藏层(编码)并且使用均方误差准则来训练网络,则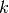 个隐藏单元学习投影输入的开始个数据的主成分。If the hidden layer is non-linear, the auto-encoder behaves differently from PCA, with the ability to capture multi-modal aspects of the input distribution. 当构建深度自动编码器[Hinton06]时,考虑堆叠多个编码器(及其相应的解码器)时,不用PCA变得更加重要。
个隐藏单元学习投影输入的开始个数据的主成分。If the hidden layer is non-linear, the auto-encoder behaves differently from PCA, with the ability to capture multi-modal aspects of the input distribution. 当构建深度自动编码器[Hinton06]时,考虑堆叠多个编码器(及其相应的解码器)时,不用PCA变得更加重要。
Because is viewed as a lossy compression of , it cannot be a good (small-loss) compression for all . 优化使其成为训练样本的良好压缩,并且希望用于其它输入,而不是用于任意输入。这是自动编码器概括的意义:它从与训练样本相同的分布给出测试样本上的低重构误差,但是通常在从输入空间随机选择的采样上具有高重构误差。
我们希望使用Theano以类的形式实现一个自动编码器,它可以在以后用于构造一个堆叠自动编码器。The first step is to create shared variables for the parameters of the autoencoder , and . (Since we are using tied weights in this tutorial, 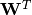 will be used for ):
will be used for ):
def __init__(
self,
numpy_rng,
theano_rng=None,
input=None,
n_visible=784,
n_hidden=500,
W=None,
bhid=None,
bvis=None
):
"""
Initialize the dA class by specifying the number of visible units (the
dimension d of the input ), the number of hidden units ( the dimension
d' of the latent or hidden space ) and the corruption level. The
constructor also receives symbolic variables for the input, weights and
bias. Such a symbolic variables are useful when, for example the input
is the result of some computations, or when weights are shared between
the dA and an MLP layer. When dealing with SdAs this always happens,
the dA on layer 2 gets as input the output of the dA on layer 1,
and the weights of the dA are used in the second stage of training
to construct an MLP.
:type numpy_rng: numpy.random.RandomState
:param numpy_rng: number random generator used to generate weights
:type theano_rng: theano.tensor.shared_randomstreams.RandomStreams
:param theano_rng: Theano random generator; if None is given one is
generated based on a seed drawn from `rng`
:type input: theano.tensor.TensorType
:param input: a symbolic description of the input or None for
standalone dA
:type n_visible: int
:param n_visible: number of visible units
:type n_hidden: int
:param n_hidden: number of hidden units
:type W: theano.tensor.TensorType
:param W: Theano variable pointing to a set of weights that should be
shared belong the dA and another architecture; if dA should
be standalone set this to None
:type bhid: theano.tensor.TensorType
:param bhid: Theano variable pointing to a set of biases values (for
hidden units) that should be shared belong dA and another
architecture; if dA should be standalone set this to None
:type bvis: theano.tensor.TensorType
:param bvis: Theano variable pointing to a set of biases values (for
visible units) that should be shared belong dA and another
architecture; if dA should be standalone set this to None
"""
self.n_visible = n_visible
self.n_hidden = n_hidden
# create a Theano random generator that gives symbolic random values
if not theano_rng:
theano_rng = RandomStreams(numpy_rng.randint(2 ** 30))
# note : W' was written as `W_prime` and b' as `b_prime`
if not W:
# W is initialized with `initial_W` which is uniformely sampled
# from -4*sqrt(6./(n_visible+n_hidden)) and
# 4*sqrt(6./(n_hidden+n_visible))the output of uniform if
# converted using asarray to dtype
# theano.config.floatX so that the code is runable on GPU
initial_W = numpy.asarray(
numpy_rng.uniform(
low=-4 * numpy.sqrt(6. / (n_hidden + n_visible)),
high=4 * numpy.sqrt(6. / (n_hidden + n_visible)),
size=(n_visible, n_hidden)
),
dtype=theano.config.floatX
)
W = theano.shared(value=initial_W, name='W', borrow=True)
if not bvis:
bvis = theano.shared(
value=numpy.zeros(
n_visible,
dtype=theano.config.floatX
),
borrow=True
)
if not bhid:
bhid = theano.shared(
value=numpy.zeros(
n_hidden,
dtype=theano.config.floatX
),
name='b',
borrow=True
)
self.W = W
# b corresponds to the bias of the hidden
self.b = bhid
# b_prime corresponds to the bias of the visible
self.b_prime = bvis
# tied weights, therefore W_prime is W transpose
self.W_prime = self.W.T
self.theano_rng = theano_rng
# if no input is given, generate a variable representing the input
if input is None:
# we use a matrix because we expect a minibatch of several
# examples, each example being a row
self.x = T.dmatrix(name='input')
else:
self.x = input
self.params = [self.W, self.b, self.b_prime]
Note that we pass the symbolic input to the autoencoder as a parameter. 这是为了我们可以连接自动编码器的层以形成深网络:层的符号输出(上面的)将是层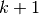 的符号输入。
的符号输入。
现在我们可以将潜在表示和重构信号的计算表示为:
def get_hidden_values(self, input):
""" Computes the values of the hidden layer """
return T.nnet.sigmoid(T.dot(input, self.W) + self.b)
def get_reconstructed_input(self, hidden):
"""Computes the reconstructed input given the values of the
hidden layer
"""
return T.nnet.sigmoid(T.dot(hidden, self.W_prime) + self.b_prime)
使用这些函数,我们可以如下计算随机梯度下降一个步骤的cost和updates:
def get_cost_updates(self, corruption_level, learning_rate):
""" This function computes the cost and the updates for one trainng
step of the dA """
tilde_x = self.get_corrupted_input(self.x, corruption_level)
y = self.get_hidden_values(tilde_x)
z = self.get_reconstructed_input(y)
# note : we sum over the size of a datapoint; if we are using
# minibatches, L will be a vector, with one entry per
# example in minibatch
L = - T.sum(self.x * T.log(z) + (1 - self.x) * T.log(1 - z), axis=1)
# note : L is now a vector, where each element is the
# cross-entropy cost of the reconstruction of the
# corresponding example of the minibatch. We need to
# compute the average of all these to get the cost of
# the minibatch
cost = T.mean(L)
# compute the gradients of the cost of the `dA` with respect
# to its parameters
gparams = T.grad(cost, self.params)
# generate the list of updates
updates = [
(param, param - learning_rate * gparam)
for param, gparam in zip(self.params, gparams)
]
return (cost, updates)
现在可以定义一个函数,对它进行迭代应用将更新参数W、b和b_prime,使得重构cost近似最小化。
da = dA(
numpy_rng=rng,
theano_rng=theano_rng,
input=x,
n_visible=28 * 28,
n_hidden=500
)
cost, updates = da.get_cost_updates(
corruption_level=0.,
learning_rate=learning_rate
)
train_da = theano.function(
[index],
cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size]
}
)
start_time = timeit.default_timer()
############
# TRAINING #
############
# go through training epochs
for epoch in range(training_epochs):
# go through trainng set
c = []
for batch_index in range(n_train_batches):
c.append(train_da(batch_index))
print('Training epoch %d, cost ' % epoch, numpy.mean(c, dtype='float64'))
end_time = timeit.default_timer()
training_time = (end_time - start_time)
print(('The no corruption code for file ' +
os.path.split(__file__)[1] +
' ran for %.2fm' % ((training_time) / 60.)), file=sys.stderr)
image = Image.fromarray(
tile_raster_images(X=da.W.get_value(borrow=True).T,
img_shape=(28, 28), tile_shape=(10, 10),
tile_spacing=(1, 1)))
image.save('filters_corruption_0.png')
# start-snippet-3
#####################################
# BUILDING THE MODEL CORRUPTION 30% #
#####################################
rng = numpy.random.RandomState(123)
theano_rng = RandomStreams(rng.randint(2 ** 30))
da = dA(
numpy_rng=rng,
theano_rng=theano_rng,
input=x,
n_visible=28 * 28,
n_hidden=500
)
cost, updates = da.get_cost_updates(
corruption_level=0.3,
learning_rate=learning_rate
)
train_da = theano.function(
[index],
cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size]
}
)
start_time = timeit.default_timer()
############
# TRAINING #
############
# go through training epochs
for epoch in range(training_epochs):
# go through trainng set
c = []
for batch_index in range(n_train_batches):
c.append(train_da(batch_index))
print('Training epoch %d, cost ' % epoch, numpy.mean(c, dtype='float64'))
end_time = timeit.default_timer()
training_time = (end_time - start_time)
print(('The 30% corruption code for file ' +
os.path.split(__file__)[1] +
' ran for %.2fm' % (training_time / 60.)), file=sys.stderr)
# end-snippet-3
# start-snippet-4
image = Image.fromarray(tile_raster_images(
X=da.W.get_value(borrow=True).T,
img_shape=(28, 28), tile_shape=(10, 10),
tile_spacing=(1, 1)))
image.save('filters_corruption_30.png')
# end-snippet-4
os.chdir('../')
if __name__ == '__main__':
test_dA()
如果除了最小化重建误差之外没有约束,可以期望具有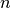 个输入和(或更大)个维度编码的自动编码器来学习身份函数,仅将输入映射到其拷贝。这样的自动编码器不会将测试样本(依据训练的分布)与其他输入配置区分开。
个输入和(或更大)个维度编码的自动编码器来学习身份函数,仅将输入映射到其拷贝。这样的自动编码器不会将测试样本(依据训练的分布)与其他输入配置区分开。
令人惊讶的是,在[Bengio07]中报道的实验表明,在实践中,当使用随机梯度下降训练时,具有比输入更多隐藏单元(称为过完备)的非线性自动编码器产生有用的表示。(Here, “useful” means that a network taking the encoding as input has low classification error.)
简单的解释是带有提前停止的随机梯度下降类似于参数的L2正则化。为了实现连续输入的完美重构,具有非线性隐藏单元的单隐层自动编码器(正如在上面的代码中)在第一(编码)层中需要非常小的权重,以使得非线性隐藏单元到它们的线性区域中,并且在第二(解码)层中具有非常大的权重。使用二元输入,还需要非常大的权重来完全最小化重建误差。因为隐式或显式正则化使得难以达到大权重解决方案,所以优化算法找到的编码只对类似于训练集中的样本工作得很好,这就是我们想要的。It means that the representation is exploiting statistical regularities present in the training set, rather than merely learning to replicate the input.
还存在其他方法,通过该方法可以防止具有比输入更多的隐藏单元的自动编码器学习恒等函数,在其隐藏表示中捕获对输入有用的东西。One is the addition of sparsity (forcing many of the hidden units to be zero or near-zero). 稀疏性已经被许多[Ranzato07] [Lee08]文献非常成功地利用。Another is to add randomness in the transformation from input to reconstruction. This technique is used in Restricted Boltzmann Machines (discussed later in Restricted Boltzmann Machines (RBM)), as well as in Denoising Auto-Encoders, discussed below.
去噪自动编码器¶
The idea behind denoising autoencoders is simple. 为了迫使隐藏层发现更鲁棒的特征并且防止它简单地学习身份,我们训练自动编码器以从它的损坏版本重建输入。
The denoising auto-encoder is a stochastic version of the auto-encoder. Intuitively, a denoising auto-encoder does two things: try to encode the input (preserve the information about the input), and try to undo the effect of a corruption process stochastically applied to the input of the auto-encoder. The latter can only be done by capturing the statistical dependencies between the inputs. The denoising auto-encoder can be understood from different perspectives (the manifold learning perspective, stochastic operator perspective, bottom-up – information theoretic perspective, top-down – generative model perspective), all of which are explained in [Vincent08]. See also section 7.2 of [Bengio09] for an overview of auto-encoders.
在[Vincent08]中,随机破坏过程随机设置一些输入为0(多达一半)。因此,对于随机选择的丢失模式的子集,去噪自动编码器试图从未被破坏(即非丢失)的值预测被破坏(即丢失)的值。Note how being able to predict any subset of variables from the rest is a sufficient condition for completely capturing the joint distribution between a set of variables (this is how Gibbs sampling works).
To convert the autoencoder class into a denoising autoencoder class, all we need to do is to add a stochastic corruption step operating on the input. The input can be corrupted in many ways, but in this tutorial we will stick to the original corruption mechanism of randomly masking entries of the input by making them zero. The code below does just that :
def get_corrupted_input(self, input, corruption_level):
"""This function keeps ``1-corruption_level`` entries of the inputs the
same and zero-out randomly selected subset of size ``coruption_level``
Note : first argument of theano.rng.binomial is the shape(size) of
random numbers that it should produce
second argument is the number of trials
third argument is the probability of success of any trial
this will produce an array of 0s and 1s where 1 has a
probability of 1 - ``corruption_level`` and 0 with
``corruption_level``
The binomial function return int64 data type by
default. int64 multiplicated by the input
type(floatX) always return float64. To keep all data
in floatX when floatX is float32, we set the dtype of
the binomial to floatX. As in our case the value of
the binomial is always 0 or 1, this don't change the
result. This is needed to allow the gpu to work
correctly as it only support float32 for now.
"""
return self.theano_rng.binomial(size=input.shape, n=1,
p=1 - corruption_level,
dtype=theano.config.floatX) * input
在堆叠自动编码器类(堆叠自动编码器)中,dA类的权重必须与对应的Sigmoid层的权重共享。For this reason, the constructor of the dA also gets Theano variables pointing to the shared parameters. 如果这些参数保留为None,那么将构造新的参数。
The final denoising autoencoder class becomes :
class dA(object):
"""Denoising Auto-Encoder class (dA)
A denoising autoencoders tries to reconstruct the input from a corrupted
version of it by projecting it first in a latent space and reprojecting
it afterwards back in the input space. Please refer to Vincent et al.,2008
for more details. If x is the input then equation (1) computes a partially
destroyed version of x by means of a stochastic mapping q_D. Equation (2)
computes the projection of the input into the latent space. Equation (3)
computes the reconstruction of the input, while equation (4) computes the
reconstruction error.
.. math::
\tilde{x} ~ q_D(\tilde{x}|x) (1)
y = s(W \tilde{x} + b) (2)
x = s(W' y + b') (3)
L(x,z) = -sum_{k=1}^d [x_k \log z_k + (1-x_k) \log( 1-z_k)] (4)
"""
def __init__(
self,
numpy_rng,
theano_rng=None,
input=None,
n_visible=784,
n_hidden=500,
W=None,
bhid=None,
bvis=None
):
"""
Initialize the dA class by specifying the number of visible units (the
dimension d of the input ), the number of hidden units ( the dimension
d' of the latent or hidden space ) and the corruption level. The
constructor also receives symbolic variables for the input, weights and
bias. Such a symbolic variables are useful when, for example the input
is the result of some computations, or when weights are shared between
the dA and an MLP layer. When dealing with SdAs this always happens,
the dA on layer 2 gets as input the output of the dA on layer 1,
and the weights of the dA are used in the second stage of training
to construct an MLP.
:type numpy_rng: numpy.random.RandomState
:param numpy_rng: number random generator used to generate weights
:type theano_rng: theano.tensor.shared_randomstreams.RandomStreams
:param theano_rng: Theano random generator; if None is given one is
generated based on a seed drawn from `rng`
:type input: theano.tensor.TensorType
:param input: a symbolic description of the input or None for
standalone dA
:type n_visible: int
:param n_visible: number of visible units
:type n_hidden: int
:param n_hidden: number of hidden units
:type W: theano.tensor.TensorType
:param W: Theano variable pointing to a set of weights that should be
shared belong the dA and another architecture; if dA should
be standalone set this to None
:type bhid: theano.tensor.TensorType
:param bhid: Theano variable pointing to a set of biases values (for
hidden units) that should be shared belong dA and another
architecture; if dA should be standalone set this to None
:type bvis: theano.tensor.TensorType
:param bvis: Theano variable pointing to a set of biases values (for
visible units) that should be shared belong dA and another
architecture; if dA should be standalone set this to None
"""
self.n_visible = n_visible
self.n_hidden = n_hidden
# create a Theano random generator that gives symbolic random values
if not theano_rng:
theano_rng = RandomStreams(numpy_rng.randint(2 ** 30))
# note : W' was written as `W_prime` and b' as `b_prime`
if not W:
# W is initialized with `initial_W` which is uniformely sampled
# from -4*sqrt(6./(n_visible+n_hidden)) and
# 4*sqrt(6./(n_hidden+n_visible))the output of uniform if
# converted using asarray to dtype
# theano.config.floatX so that the code is runable on GPU
initial_W = numpy.asarray(
numpy_rng.uniform(
low=-4 * numpy.sqrt(6. / (n_hidden + n_visible)),
high=4 * numpy.sqrt(6. / (n_hidden + n_visible)),
size=(n_visible, n_hidden)
),
dtype=theano.config.floatX
)
W = theano.shared(value=initial_W, name='W', borrow=True)
if not bvis:
bvis = theano.shared(
value=numpy.zeros(
n_visible,
dtype=theano.config.floatX
),
borrow=True
)
if not bhid:
bhid = theano.shared(
value=numpy.zeros(
n_hidden,
dtype=theano.config.floatX
),
name='b',
borrow=True
)
self.W = W
# b corresponds to the bias of the hidden
self.b = bhid
# b_prime corresponds to the bias of the visible
self.b_prime = bvis
# tied weights, therefore W_prime is W transpose
self.W_prime = self.W.T
self.theano_rng = theano_rng
# if no input is given, generate a variable representing the input
if input is None:
# we use a matrix because we expect a minibatch of several
# examples, each example being a row
self.x = T.dmatrix(name='input')
else:
self.x = input
self.params = [self.W, self.b, self.b_prime]
def get_corrupted_input(self, input, corruption_level):
"""This function keeps ``1-corruption_level`` entries of the inputs the
same and zero-out randomly selected subset of size ``coruption_level``
Note : first argument of theano.rng.binomial is the shape(size) of
random numbers that it should produce
second argument is the number of trials
third argument is the probability of success of any trial
this will produce an array of 0s and 1s where 1 has a
probability of 1 - ``corruption_level`` and 0 with
``corruption_level``
The binomial function return int64 data type by
default. int64 multiplicated by the input
type(floatX) always return float64. To keep all data
in floatX when floatX is float32, we set the dtype of
the binomial to floatX. As in our case the value of
the binomial is always 0 or 1, this don't change the
result. This is needed to allow the gpu to work
correctly as it only support float32 for now.
"""
return self.theano_rng.binomial(size=input.shape, n=1,
p=1 - corruption_level,
dtype=theano.config.floatX) * input
def get_hidden_values(self, input):
""" Computes the values of the hidden layer """
return T.nnet.sigmoid(T.dot(input, self.W) + self.b)
def get_reconstructed_input(self, hidden):
"""Computes the reconstructed input given the values of the
hidden layer
"""
return T.nnet.sigmoid(T.dot(hidden, self.W_prime) + self.b_prime)
def get_cost_updates(self, corruption_level, learning_rate):
""" This function computes the cost and the updates for one trainng
step of the dA """
tilde_x = self.get_corrupted_input(self.x, corruption_level)
y = self.get_hidden_values(tilde_x)
z = self.get_reconstructed_input(y)
# note : we sum over the size of a datapoint; if we are using
# minibatches, L will be a vector, with one entry per
# example in minibatch
L = - T.sum(self.x * T.log(z) + (1 - self.x) * T.log(1 - z), axis=1)
# note : L is now a vector, where each element is the
# cross-entropy cost of the reconstruction of the
# corresponding example of the minibatch. We need to
# compute the average of all these to get the cost of
# the minibatch
cost = T.mean(L)
# compute the gradients of the cost of the `dA` with respect
# to its parameters
gparams = T.grad(cost, self.params)
# generate the list of updates
updates = [
(param, param - learning_rate * gparam)
for param, gparam in zip(self.params, gparams)
]
return (cost, updates)
合在一起¶
It is easy now to construct an instance of our dA class and train it.
# allocate symbolic variables for the data
index = T.lscalar() # index to a [mini]batch
x = T.matrix('x') # the data is presented as rasterized images
#####################################
# BUILDING THE MODEL CORRUPTION 30% #
#####################################
rng = numpy.random.RandomState(123)
theano_rng = RandomStreams(rng.randint(2 ** 30))
da = dA(
numpy_rng=rng,
theano_rng=theano_rng,
input=x,
n_visible=28 * 28,
n_hidden=500
)
cost, updates = da.get_cost_updates(
corruption_level=0.3,
learning_rate=learning_rate
)
train_da = theano.function(
[index],
cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size]
}
)
start_time = timeit.default_timer()
############
# TRAINING #
############
# go through training epochs
for epoch in range(training_epochs):
# go through trainng set
c = []
for batch_index in range(n_train_batches):
c.append(train_da(batch_index))
print('Training epoch %d, cost ' % epoch, numpy.mean(c, dtype='float64'))
end_time = timeit.default_timer()
training_time = (end_time - start_time)
print(('The 30% corruption code for file ' +
os.path.split(__file__)[1] +
' ran for %.2fm' % (training_time / 60.)), file=sys.stderr)
为了感知学习到的网络,我们将绘制出filter(由权重矩阵定义)。Bear in mind, however, that this does not provide the entire story, since we neglect the biases and plot the weights up to a multiplicative constant (weights are converted to values between 0 and 1).
要绘制我们的filter,我们需要tile_raster_images(参见绘制样本和filter)的帮助,所以我们鼓励读者学习它。还使用Python图像库的帮助,以下代码行将filter保存为图像:
image = Image.fromarray(tile_raster_images(
X=da.W.get_value(borrow=True).T,
img_shape=(28, 28), tile_shape=(10, 10),
tile_spacing=(1, 1)))
image.save('filters_corruption_30.png')

