TensorFlow是进行大规模数值计算的强大库。 它擅长的任务之一是实施和培训深度神经网络。 在本教程中,我们将学习TensorFlow模型的基本构建模块,同时构建深度卷积MNIST分类器。
本介绍假定您熟悉神经网络和MNIST数据集。 如果你没有他们的背景,请查看初学者介绍。 确保在开始之前安装TensorFlow。
本教程的第一部分解释在mnist_softmax.py代码中所发生的事情,它是Tensorflow模型的基本实现。 第二部分展示了一些提高准确度的方法。
您可以将本教程中的每个代码片段复制并粘贴到Python环境中,或者您可以从mnist_deep.py下载完全实施的深网。
我们将在本教程中完成的任务:
基于查看图像中的每个像素,创建一个softmax回归函数,该函数是识别MNIST数字的模型
使用Tensorflow训练模型来识别数字,方法是让其“查看”成千上万个示例(并运行我们的第一个Tensorflow会话来完成)
使用我们的测试数据检查模型的精度
构建、训练和测试一个多层卷积神经网络以改善结果
在我们创建模型之前,我们将首先加载MNIST数据集,然后开始一个TensorFlow会话。
如果你在本教程的代码中复制和粘贴,请从这两行代码开始,它们将自动下载并读取数据:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)这里,mnist是一个轻量级的类,它将训练、验证和测试集存储为NumPy数组。 它还提供了一个函数来迭代数据minibatches,我们将在下面使用它。
TensorFlow依靠高效的C++后端来进行计算。 与此后端的连接称为会话。 TensorFlow程序的常见用法是首先创建一个图,然后在会话中启动它。
这里我们使用便捷的InteractiveSession类,它使得TensorFlow更加灵活地构建你的代码。 它允许你将执行图的操作进行交织以构建一个计算图。 在IPython等交互式上下文中工作时,这特别方便。 如果你不使用InteractiveSession,则应在开始会话之前构建整个计算图并启动这个图。
import tensorflow as tf
sess = tf.InteractiveSession()为了在Python中进行有效的数值计算,我们通常使用像NumPy这样的库,这些库执行昂贵的操作,例如Python之外的矩阵乘法,使用以另一种语言实现的高效代码。 不幸的是,每次操作都会返回Python,但仍然会有很多开销。 如果您想要在GPU上运行计算或以分布式方式运行计算,则这种开销尤其糟糕,因为在这种情况下,传输数据的成本很高。
TensorFlow也在Python之外进行繁重的工作,但为了避免这种开销,它需要更进一步。 TensorFlow不是只独立于Python运行一个单一的昂贵操作,而是让我们描述完全一个完全在Python之外运行的交互操作的图。 这种方法类似于Theano或Torch中使用的方法。
因此,Python代码的作用是构建这个外部计算图,并指定应该运行计算图的哪些部分。 有关详细信息,请参阅TensorFlow 入门中的计算图部分。
在本节中,我们将建立一个单线性层的softmax回归模型。 在下一节中,我们将扩展到具有多层卷积网络的softmax回归的情况。
我们通过创建输入图片和目标输出类别的节点来开始构建计算图。
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])这里x和y _不是特定的值。 相反,它们各自是一个占位符 — 当我们要求TensorFlow运行计算时,我们将输入一个值。
输入图片x将由2维浮点数张量组成。 这里,我们赋给它一个为[None, 784]的形状 ,其中784是单个平坦化28乘28像素MNIST图像的维数,None表示对应于批量大小的第一维可以是任何大小。 目标输出类别y _也将由二维张量组成,其中每行是一个one-hot 10维向量,指示对应的MNIST图像属于哪个数字类别(零到九)。
虽然placeholder的shape参数是可选的,但它允许TensorFlow自动捕获不一致的张量形状导致的错误。
我们现在为我们的模型定义权重W和偏置b。 我们可以想象,像其他输入一样处理这些信息,但是TensorFlow有一个更好的处理方式:Variable。 一个Variable是位于TensorFlow计算图中的一个值。 它可以被使用,甚至被计算修改。 在机器学习应用中,人们通常让模型的参数为Variable。
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))我们将调用中每个参数的初始值传递给tf.Variable。 在这种情况下,我们将W和b初始化为满零的张量。 W是一个784x10矩阵(因为我们有784个输入特征和10个输出),而b是一个10维向量(因为我们有10个类别)。
在变量可以在会话中使用之前,它们必须使用该会话进行初始化。 这一步将获得已经指定的初始值(在这种情况下,张量满了零),并将它们分配给每个变量。 这可以一次完成所有变量:
sess.run(tf.global_variables_initializer())我们现在可以实现我们的回归模型。 它只需要一行! 我们将向量化的输入图片x乘以权重矩阵W,添加偏置b。
y = tf.matmul(x,W) + b我们可以轻松地指定一个损失函数。 损失表明模型在一个样本上的预测有多糟糕;在这些样本之间训练时我们尝试尽量减少所有这些样本的损失。 在这里,我们的损失函数是目标和应用于模型预测的softmax激活函数之间的交叉熵。 和初学者教程一样,我们使用稳定公式:
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))请注意,tf.nn.softmax_cross_entropy_with_logits内部将softmax用于模型的非归一化预测结果并对类别求和,tf.reduce_mean取所有这些和的平均值。
现在我们已经定义了我们的模型和训练损失函数,使用TensorFlow进行训练非常简单。 因为TensorFlow知道整个计算图,它可以使用自动微分来找出相对于每个变量的损失的梯度。 TensorFlow有多种内置优化算法。 对于这个例子,我们将使用最陡的梯度下降,步长为0.5,下降交叉熵。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)TensorFlow实际上在这一行中做了什么是为计算图添加新的操作。 这些操作包括计算梯度,计算参数更新步骤以及将更新步骤应用于参数。
返回的操作train_step,在运行时,将梯度下降更新应用于参数。 训练模型可以通过重复运行train_step来完成。
for _ in range(1000):
batch = mnist.train.next_batch(100)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})我们在每次训练迭代中加载100个训练样例。 然后我们使用feed_dict运行操作,并用feed_dict以训练样本替换placeholder张量x和y_。 请注意,你可以使用feed_dict替换计算图中的任何张量 — 不仅限于placeholder。
我们的模型有多好?
首先我们要弄清楚我们在哪里预测了正确的标签。 tf.argmax是一个非常有用的函数,它为沿着某个轴的张量中的最高条目提供索引。 例如,tf.argmax(y,1)是我们的模型认为对每个输入最有可能的标签,而tf.argmax(y_,1)是真实的标签。 我们可以使用tf.equal来检查我们的预测是否符合事实。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))这给了我们一个布尔的列表。 为了确定哪些分数是正确的,我们转换为浮点数,然后取平均值。 例如,[True,False,True,True]将成为[1,0,1,1],它将变为0.75。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))最后,我们可以评估我们对测试数据的准确性。 这应该是大约92%正确。
print(accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels}))在MNIST上获得92%的准确性是不好的。 几乎是非常差。 在本节中,我们将修复它,从一个非常简单的模型跳到中等复杂:一个小的卷积神经网络。 这将使我们达到约99.2%的准确度 — 不是最先进的技术但已经相当好。
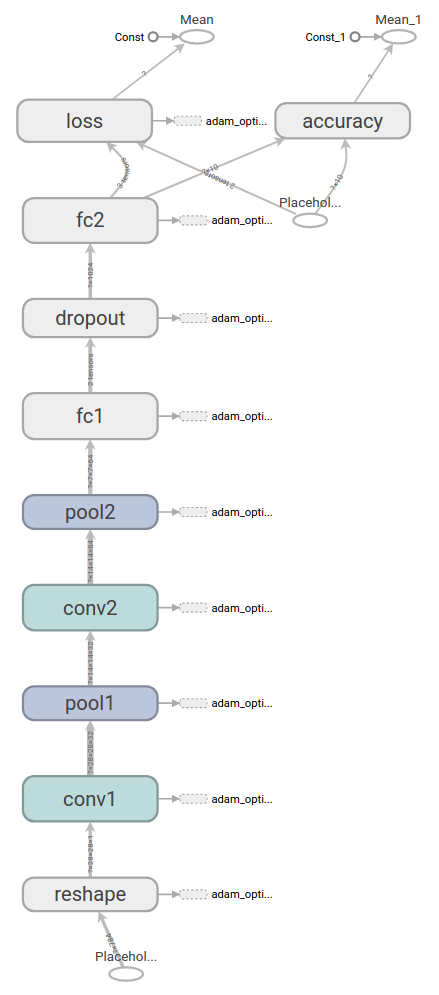
这是一张用TensorBoard创建的关于我们将要构建的模型的图表:
要创建这个模型,我们需要创建很多权重和偏见。 一般应该用少量的噪音来初始化权重用于symmetry breaking,并防止0梯度。 由于我们使用ReLU神经元,所以初始化它们为一个微小的正值偏置也是一个很好的做法,以避免“死神经元”。 为了不用在构建模型时反复进行,我们创建两个方便的函数。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)TensorFlow还为卷积和池化操作提供了很大的灵活性。 我们如何处理边界? 我们的步幅是多少? 在这个例子中,我们总是选择香草版本。 我们的卷积使用一个步长,并填充零,以便输出与输入大小相同。 我们的池是2×2块上的普通的最大化池。 为了使代码更清洁,我们也将这些操作抽象为函数。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')我们现在可以实现我们的第一层。 它将由卷积组成,接着是最大化池化。 卷积将为每个5x5个patch计算32个特征。 其权重张量将具有[5, 5, 1, 32]的形状。 前两个维度是patch大小,下一个是输入通道的数量,最后一个是输出通道的数量。 我们还将为每个输出通道分配一个偏置矢量。
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])要应用这层,我们首先将x重塑为4d张量,第二和第三维对应于图像的宽度和高度,最后的维度对应于颜色通道的数量。
x_image = tf.reshape(x, [-1, 28, 28, 1])然后,使用权重张量卷积x_image,添加偏置,应用ReLU函数,最后使用max pool。 max_pool_2x2方法会将图像大小减小到14x14。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)为了构建一个深层次的网络,我们多堆叠几层这种类型。 第二层将为每个5x5 patch提供64个特征。
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)现在图像尺寸已经减小到7x7,我们添加了一个具有1024个神经元的完全连接图层,以允许在整个图像上进行处理。 我们从池化层将张量重塑成一批向量,乘以权重矩阵,添加偏置并应用ReLU。
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)为了减少过度拟合,我们将在读出层之前应用dropout。 我们创建一个placeholder,以便在dropout时保留神经元的输出。 这样可以让我们在训练过程中改变dropout,并在测试过程中将其关闭。 TensorFlow的tf.nn.dropout op会自动处理缩放神经元输出以及屏蔽它们,所以dropout不需要任何额外的缩放。1
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)最后,我们添加一层,就像上面softmax回归层一样。
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2这个模型有多好? 为了训练和评估它,我们将使用与上述简单的一层SoftMax网络几乎相同的代码。
不同之处在于:
我们将用更复杂的ADAM优化器替换最陡梯度下降优化器。
我们将在feed_dict中添加附加参数keep_prob来控制dropout率。
在训练过程中,我们将每隔100次迭代添加日志记录。
我们也将使用tf.Session而不是tf.InteractiveSession。 这更好地分离了创建图(模型specification)的过程和评估图(模型拟合)的过程。 它通常会使代码更简洁。 tf.Session在with代码块中创建,在该代码块退出后它将自动销毁。
请随意运行这段代码。 请注意,它会执行20,000次训练迭代,并且可能需要一段时间(可能长达半小时),具体取决于你的处理器。
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print('test accuracy %g' % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))运行此代码后的最终测试集精度应为约99.2%。
我们已经学会了如何使用TensorFlow快速轻松地构建,培训和评估相当复杂的深度学习模型。
1: For this small convolutional network, performance is actually nearly identical with and without dropout. Dropout通常在减少过拟合方面非常有效,但是在训练非常大的神经网络时最有用。 ↩
