Tensor的基本功能¶
Theano支持任何类型的Python对象,但它的重点是支持符号矩阵表达式。当你输入
>>> x = T.fmatrix()
x是一个TensorVariable实例。T.fmatrix对象本身是TensorType的实例。Theano知道x是什么类型的变量,因为x.type指回T.fmatrix。
本章介绍创建张量变量的各种方法、TensorVariable和TensorType的属性和方法,以及Theano对张量变量支持的各种基本符号数学和算术。
创建¶
Theano提供一个预定义张量类型的列表,可用于创建张量变量。可以命名变量以方便调试,并且所有这些构造函数接受可选的name参数。例如,以下每个语句都产生一个TensorVariable实例,来表示名为'myvar'的0维整数类型的ndarray:
>>> x = scalar('myvar', dtype='int32')
>>> x = iscalar('myvar')
>>> x = TensorType(dtype='int32', broadcastable=())('myvar')
可选dtype的变量定义函数 ¶
下面是在你的代码中创建符号变量的最简单且通常是首选的方法。By default, they produce floating-point variables (with dtype determined by config.floatX, see floatX) so if you use these constructors it is easy to switch your code between different levels of floating-point precision.
-
theano.tensor.scalar(name=None, dtype=config.floatX)[source]¶ Return a Variable for a 0-dimensional ndarray
-
theano.tensor.vector(name=None, dtype=config.floatX)[source]¶ Return a Variable for a 1-dimensional ndarray
-
theano.tensor.row(name=None, dtype=config.floatX)[source]¶ Return a Variable for a 2-dimensional ndarray in which the number of rows is guaranteed to be 1.
-
theano.tensor.col(name=None, dtype=config.floatX)[source]¶ Return a Variable for a 2-dimensional ndarray in which the number of columns is guaranteed to be 1.
-
theano.tensor.matrix(name=None, dtype=config.floatX)[source]¶ Return a Variable for a 2-dimensional ndarray
各种类型的所有构造函数¶
The following TensorType instances are provided in the theano.tensor module. They are all callable, and accept an optional name argument. So for example:
from theano.tensor import *
x = dmatrix() # creates one Variable with no name
x = dmatrix('x') # creates one Variable with name 'x'
xyz = dmatrix('xyz') # creates one Variable with name 'xyz'
| Constructor | dtype | ndim | shape | broadcastable |
|---|---|---|---|---|
| bscalar | int8 | 0 | () | () |
| bvector | int8 | 1 | (?,) | (False,) |
| brow | int8 | 2 | (1,?) | (True, False) |
| bcol | int8 | 2 | (?,1) | (False, True) |
| bmatrix | int8 | 2 | (?,?) | (False, False) |
| btensor3 | int8 | 3 | (?,?,?) | (False, False, False) |
| btensor4 | int8 | 4 | (?,?,?,?) | (False, False, False, False) |
| btensor5 | int8 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| wscalar | int16 | 0 | () | () |
| wvector | int16 | 1 | (?,) | (False,) |
| wrow | int16 | 2 | (1,?) | (True, False) |
| wcol | int16 | 2 | (?,1) | (False, True) |
| wmatrix | int16 | 2 | (?,?) | (False, False) |
| wtensor3 | int16 | 3 | (?,?,?) | (False, False, False) |
| wtensor4 | int16 | 4 | (?,?,?,?) | (False, False, False, False) |
| wtensor5 | int16 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| iscalar | int32 | 0 | () | () |
| ivector | int32 | 1 | (?,) | (False,) |
| irow | int32 | 2 | (1,?) | (True, False) |
| icol | int32 | 2 | (?,1) | (False, True) |
| imatrix | int32 | 2 | (?,?) | (False, False) |
| itensor3 | int32 | 3 | (?,?,?) | (False, False, False) |
| itensor4 | int32 | 4 | (?,?,?,?) | (False, False, False, False) |
| itensor5 | int32 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| lscalar | int64 | 0 | () | () |
| lvector | int64 | 1 | (?,) | (False,) |
| lrow | int64 | 2 | (1,?) | (True, False) |
| lcol | int64 | 2 | (?,1) | (False, True) |
| lmatrix | int64 | 2 | (?,?) | (False, False) |
| ltensor3 | int64 | 3 | (?,?,?) | (False, False, False) |
| ltensor4 | int64 | 4 | (?,?,?,?) | (False, False, False, False) |
| ltensor5 | int64 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| dscalar | float64 | 0 | () | () |
| dvector | float64 | 1 | (?,) | (False,) |
| drow | float64 | 2 | (1,?) | (True, False) |
| dcol | float64 | 2 | (?,1) | (False, True) |
| dmatrix | float64 | 2 | (?,?) | (False, False) |
| dtensor3 | float64 | 3 | (?,?,?) | (False, False, False) |
| dtensor4 | float64 | 4 | (?,?,?,?) | (False, False, False, False) |
| dtensor5 | float64 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| fscalar | float32 | 0 | () | () |
| fvector | float32 | 1 | (?,) | (False,) |
| frow | float32 | 2 | (1,?) | (True, False) |
| fcol | float32 | 2 | (?,1) | (False, True) |
| fmatrix | float32 | 2 | (?,?) | (False, False) |
| ftensor3 | float32 | 3 | (?,?,?) | (False, False, False) |
| ftensor4 | float32 | 4 | (?,?,?,?) | (False, False, False, False) |
| ftensor5 | float32 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| cscalar | complex64 | 0 | () | () |
| cvector | complex64 | 1 | (?,) | (False,) |
| crow | complex64 | 2 | (1,?) | (True, False) |
| ccol | complex64 | 2 | (?,1) | (False, True) |
| cmatrix | complex64 | 2 | (?,?) | (False, False) |
| ctensor3 | complex64 | 3 | (?,?,?) | (False, False, False) |
| ctensor4 | complex64 | 4 | (?,?,?,?) | (False, False, False, False) |
| ctensor5 | complex64 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
| zscalar | complex128 | 0 | () | () |
| zvector | complex128 | 1 | (?,) | (False,) |
| zrow | complex128 | 2 | (1,?) | (True, False) |
| zcol | complex128 | 2 | (?,1) | (False, True) |
| zmatrix | complex128 | 2 | (?,?) | (False, False) |
| ztensor3 | complex128 | 3 | (?,?,?) | (False, False, False) |
| ztensor4 | complex128 | 4 | (?,?,?,?) | (False, False, False, False) |
| ztensor5 | complex128 | 5 | (?,?,?,?,?) | (False, False, False, False, False) |
多元构造函数¶
There are several constructors that can produce multiple variables at once. These are not frequently used in practice, but often used in tutorial examples to save space!
iscalars, lscalars, fscalars, dscalarsReturn one or more scalar variables.
ivectors, lvectors, fvectors, dvectorsReturn one or more vector variables.
irows, lrows, frows, drowsReturn one or more row variables.
icols, lcols, fcols, dcols返回一个或多个列变量。
imatrices, lmatrices, fmatrices, dmatricesReturn one or more matrix variables.
每个多元构造函数接受一个整数或多个字符串。如果提供一个整数,该方法将返回对应数目的变量,如果提供字符串,它将为每个字符串创建一个变量,使用字符串作为变量的名称。For example:
from theano.tensor import *
x, y, z = dmatrices(3) # creates three matrix Variables with no names
x, y, z = dmatrices('x', 'y', 'z') # creates three matrix Variables named 'x', 'y' and 'z'
自定义张量类型¶
如果你想构造一个具有非标准broadcasting模式或更大维数的张量变量,你需要创建你自己的TensorType实例。你可以通过传递dtype和broadcasting模式到构造函数创建这样的实例。For example, you can create your own 6-dimensional tensor type
>>> dtensor6 = TensorType('float64', (False,)*6)
>>> x = dtensor6()
>>> z = dtensor6('z')
你也可以重新定义一些已经提供的类型,它们会正确交互:
>>> my_dmatrix = TensorType('float64', (False,)*2)
>>> x = my_dmatrix() # allocate a matrix variable
>>> my_dmatrix == dmatrix
True
See TensorType for more information about creating new types of Tensor.
从Python对象转换¶
另一种创建TensorVariable(更准确地说,应该是TensorSharedVariable)的方法是调用shared()
x = shared(numpy.random.randn(3,4))
This will return a shared variable whose .value is a numpy ndarray. 变量的维数和数据类型数从ndarray参数推断出来。shared 的参数不会被复制,随后的更改将反映在x.value中。
For additional information, see the shared() documentation.
最后,当你在算术表达式中将numpy ndarry或Python数字和TensorVariable实例一起使用时,结果将为TensorVariable。What happens to the ndarray or the number? Theano要求所有表达式的输入都是Variable实例,因此Theano会自动将它们封装在一个TensorConstant中。
Note
Theano对你在表达式中使用的任何ndarray生成一个拷贝,所以对ndarray的后续更改不会对Theano表达式产生任何影响。
对于numpy ndarrays,dtype已经给出,但是broadcastable模式必须推断出来。TensorConstant将被赋予一个匹配dtype的类型,以及一个broadcastable模式,其中每个维度为1的维是True。
对于python数字,broadcastable模式为(),但必须推断得到dtype。Python integers are stored in the smallest dtype that can hold them, so small constants like 1 are stored in a bscalar. 同样,如果fscalar足以完整保存它们,Python浮点存储在一个fscalar中,否则存储在一个dscalar中。
Note
When config.floatX==float32 (see config), then Python floats are stored instead as single-precision floats.
For fine control of this rounding policy, see theano.tensor.basic.autocast_float.
-
theano.tensor.as_tensor_variable(x, name=None, ndim=None)[source]¶ Turn an argument x into a TensorVariable or TensorConstant.
许多张量操作通过这个函数运行它们的参数作为预处理。它传递进TensorVariable实例,并尝试将其他对象封装到TensorConstant中。
When x is a Python number, the dtype is inferred as described above.
当x是列表或元组时,它通过numpy.asarray传递
如果ndim参数不是None,它必须是一个整数,如果有必要,输出将被broadcasted以具有这么多维度。
Return type: TensorVariableorTensorConstant
TensorType和TensorVariable¶
- class
theano.tensor.TensorType(Type)[source]¶ 用于标记表示numpy.ndarray值的Variable的Type类(numpy.ndarray的子类numpy.memmap也允许)。回到教程,教程的图形结构图中的紫色框是此类的一个实例。
-
broadcastable[source]¶ True/False值组成的一个元组,每个维度一个值。位置'i'为True表示在计算时,ndarray在第i个维度的大小为1。这样的维度被称为broadcastable维度(参见Theano和Numpy中的Broadcasting )。
Broadcastable的模式表示维度的数量以及特定维度是否必须具有长度1。
以下是将一些broadcastable模式映射到其意义的表格:
pattern interpretation [] scalar [True] 1D标量(长度为1的向量) [True, True] 2D scalar (1x1 matrix) [False] vector [False, False] matrix [False] * n nD tensor [True, False] row (1xN matrix) [False, True] column (Mx1 matrix) [False, True, False] A Mx1xP tensor (a) [True, False, False] A 1xNxP tensor (b) [False, False, False] A MxNxP tensor (pattern of a + b) 对于broadcasting为False的维度,此维度的长度可以为1或更大。对于broadcasting为True的维度,此维度的长度必须为1。
当元素级别的操作(如加法或减法)的两个参数具有不同数量的维度时,可broadcastable模式通过使用
True填充而向左扩展。例如,向量的模式[False]可以扩展为[True, False],并且将表现得像行(1xN矩阵)。In the same way, a matrix ([False, False]) would behave like a 1xNxP tensor ([True, False, False]).如果我们想创建一个类型来表示矩阵,当将它们相加到一起时,它们将在3维张量的中间维度上broadcast,我们将这样定义:
>>> middle_broadcaster = TensorType('complex64', [False, True, False])
-
dtype[source]¶ 一个字符串,表示此类型的变量所在的ndarray的数值类型。
The dtype attribute of a TensorType instance can be any of the following strings.
dtype domain bits 'int8'signed integer 8 'int16'signed integer 16 'int32'signed integer 32 'int64'signed integer 64 'uint8'unsigned integer 8 'uint16'unsigned integer 16 'uint32'unsigned integer 32 'uint64'unsigned integer 64 'float32'浮点数 32 'float64'浮点数 64 'complex64'复数 64 (two float32) 'complex128'复数 128 (two float64)
-
__init__(self, dtype, broadcastable)[source]¶ 如果你想使用一种没有预置的张量类型(例如,5D张量),你可以通过实例化
TensorType来建立一个合适的类型。
-
TensorVariable¶
- class
theano.tensor.TensorVariable(Variable, _tensor_py_operators)[source]¶ The result of symbolic operations typically have this type.
有关你将要调用的大多数属性和方法,请参见
_tensor_py_operators。
- class
theano.tensor.TensorConstant(Variable, _tensor_py_operators)[source]¶ Python和numpy数字封装在此类型中。
有关你将要调用的大多数属性和方法,请参见
_tensor_py_operators。
This type is returned by
shared()when the value to share is a numpy ndarray.有关你将要调用的大多数属性和方法,请参见
_tensor_py_operators。
- class
theano.tensor._tensor_py_operators[source]¶ 这是一个类,为Python操作符(参见运算符的支持)向TensorVariable、TensorConstant和TensorSharedVariable添加方便的属性、方法和支持。
-
type[source]¶ TensorType实例的一个引用,描述可能与此变量相关联的值的类型。
-
ndim[source]¶ The number of dimensions of this tensor.
TensorType.ndim的别名。
-
dtype[source]¶ 该张量的数值类型。
TensorType.dtype的别名。
-
reshape(shape, ndim=None)[source]¶ 返回reshaped后的张量的视图,类似numpy.reshape。如果shape是一个Variable参数,那么你可能需要使用可选的ndim参数来声明形状具有多少个元素,这样reshaped的变量将具有多少个维度。
See
reshape().
-
dimshuffle(*pattern)[source]¶ 返回该张量的一个视图,并且维度已经置换。通常,pattern包括整数0、1、... ndim-1以及任意数量字符‘x’,如果张量相应的维度应该broadcast。
pattern的几个例子及其效果:
- (‘x’) -> 将0d(标量)转换为1d向量
- (0, 1) -> 2d向量
- (1, 0) -> 对调第一维和第二维
- (‘x’, 0) -> 从1d向量生成一个行(N到1xN)
- (0, ‘x’) -> 从1d向量生成一个列(N到Nx1)
- (2, 0, 1) -> AxBxC到CxAxB
- (0, ‘x’, 1) -> AxB到Ax1xB
- (1, ‘x’, 0) -> AxB到Bx1xA
- (1,) -> 删除维度0。它必须是一个broadcastable的维度(1xA到A)
-
flatten(ndim=1)[source]¶ 以ndim维度返回此张量的视图,其中前ndim-1维的形状将与self相同,剩余维度的形状将被展开以适应来自自身的所有数据。
See
flatten().
-
T[source]¶ 转置这个张量。
>>> x = T.zmatrix() >>> y = 3+.2j * x.T
Note
In numpy and in Theano, the transpose of a vector is exactly the same vector! 使用reshape或dimshuffle将你的向量变成行或列矩阵。
{any,all}(axis=None, keepdims=False)
{sum,prod,mean}(axis=None, dtype=None, keepdims=False, acc_dtype=None)
{var,std,min,max,argmin,argmax}(axis=None, keepdims=False),
-
copy() Return a new symbolic variable that is a copy of the variable. Does not copy the tag.
__{abs,neg,lt,le,gt,ge,invert,and,or,add,sub,mul,div,truediv,floordiv}__这些元素级别操作通过Python语法支持。
-
argsort(axis=-1, kind='quicksort', order=None)[source] See theano.tensor.argsort.
-
choose(a, choices, out=None, mode='raise')[source]¶ Construct an array from an index array and a set of arrays to choose from.
clip(a_min, a_max)[source]Clip (limit) the values in an array.
-
dimshuffle(*pattern)[source] 对此变量的维度重新排序,可选择插入要被broadcasted的维度。
Parameters: 模式 - 整数与'x'(表示要broadcast的维度)混合的列表/元祖。 Examples
For example, to create a 3D view of a [2D] matrix, call
dimshuffle([0,'x',1]). 这将创建一个3D视图,且中间维度为将要broadcast的维度。要对该矩阵的转置矩阵执行相同的操作,请调用dimshuffle([1, 'x', 0])。注意事项
此函数支持以元组或可变长度参数传递的pattern(例如
a.dimshuffle(pattern)等价于a.dimshuffle(*pattern),pattern是一个整数与'x'字符混合的列表/元组)。See also
DimShuffle()
-
dtype[source] 这个张量的dtype。
-
imag[source]¶ 返回复数类型张量z的虚分量
Generalizes a scalar op to tensors.
All the inputs must have the same number of dimensions. When the Op is performed, for each dimension, each input’s size for that dimension must be the same. As a special case, it can also be 1 but only if the input’s broadcastable flag is True for that dimension. In that case, the tensor is (virtually) replicated along that dimension to match the size of the others.
The dtypes of the outputs mirror those of the scalar Op that is being generalized to tensors. In particular, if the calculations for an output are done inplace on an input, the output type must be the same as the corresponding input type (see the doc of scalar.ScalarOp to get help about controlling the output type)
Parameters: - scalar_op – An instance of a subclass of scalar.ScalarOp which works uniquely on scalars.
- inplace_pattern – A dictionary that maps the index of an output to the index of an input so the output is calculated inplace using the input’s storage. (Just like destroymap, but without the lists.)
- nfunc_spec – Either None or a tuple of three elements, (nfunc_name, nin, nout) such that getattr(numpy, nfunc_name) implements this operation, takes nin inputs and nout outputs. Note that nin cannot always be inferred from the scalar op’s own nin field because that value is sometimes 0 (meaning a variable number of inputs), whereas the numpy function may not have varargs.
Examples
Elemwise(add) # represents + on tensors (x + y) Elemwise(add, {0 : 0}) # represents the += operation (x += y) Elemwise(add, {0 : 1}) # represents += on the second argument (y += x) Elemwise(mul)(rand(10, 5), rand(1, 5)) # the second input is completed # along the first dimension to match the first input Elemwise(true_div)(rand(10, 5), rand(10, 1)) # same but along the # second dimension Elemwise(int_div)(rand(1, 5), rand(10, 1)) # the output has size (10, 5) Elemwise(log)(rand(3, 4, 5))
-
ndim[source] The rank of this tensor.
nonzero(return_matrix=False)[source]See theano.tensor.nonzero.
-
nonzero_values()[source] See theano.tensor.nonzero_values.
-
real[source]¶ Return real component of complex-valued tensor z
Generalizes a scalar op to tensors.
All the inputs must have the same number of dimensions. When the Op is performed, for each dimension, each input’s size for that dimension must be the same. As a special case, it can also be 1 but only if the input’s broadcastable flag is True for that dimension. In that case, the tensor is (virtually) replicated along that dimension to match the size of the others.
The dtypes of the outputs mirror those of the scalar Op that is being generalized to tensors. In particular, if the calculations for an output are done inplace on an input, the output type must be the same as the corresponding input type (see the doc of scalar.ScalarOp to get help about controlling the output type)
Parameters: - scalar_op – An instance of a subclass of scalar.ScalarOp which works uniquely on scalars.
- inplace_pattern – A dictionary that maps the index of an output to the index of an input so the output is calculated inplace using the input’s storage. (Just like destroymap, but without the lists.)
- nfunc_spec – Either None or a tuple of three elements, (nfunc_name, nin, nout) such that getattr(numpy, nfunc_name) implements this operation, takes nin inputs and nout outputs. Note that nin cannot always be inferred from the scalar op’s own nin field because that value is sometimes 0 (meaning a variable number of inputs), whereas the numpy function may not have varargs.
Examples
Elemwise(add) # represents + on tensors (x + y) Elemwise(add, {0 : 0}) # represents the += operation (x += y) Elemwise(add, {0 : 1}) # represents += on the second argument (y += x) Elemwise(mul)(rand(10, 5), rand(1, 5)) # the second input is completed # along the first dimension to match the first input Elemwise(true_div)(rand(10, 5), rand(10, 1)) # same but along the # second dimension Elemwise(int_div)(rand(1, 5), rand(10, 1)) # the output has size (10, 5) Elemwise(log)(rand(3, 4, 5))
repeat(repeats, axis=None)[source]See theano.tensor.repeat.
-
reshape(shape, ndim=None)[source] Return a reshaped view/copy of this variable.
Parameters: - shape – Something that can be converted to a symbolic vector of integers.
- ndim – The length of the shape. Passing None here means for Theano to try and guess the length of shape.
- :param .. warning:: This has a different signature than numpy’s: ndarray.reshape!
- In numpy you do not need to wrap the shape arguments in a tuple, in theano you do need to.
-
round(mode='half_away_from_zero')[source] See theano.tensor.round.
-
sort(axis=-1, kind='quicksort', order=None)[source] See theano.tensor.sort.
-
squeeze()[source]¶ Remove broadcastable dimensions from the shape of an array.
It returns the input array, but with the broadcastable dimensions removed. This is always x itself or a view into x.
-
swapaxes(axis1, axis2)[source]¶ Return ‘tensor.swapaxes(self, axis1, axis2).
If a matrix is provided with the right axes, its transpose will be returned.
-
transfer(target)[source]¶ If target is ‘cpu’ this will transfer to a TensorType (if not already one). Other types may define additional targets.
Parameters: target (str) – The desired location of the output variable
-
Shaping和Shuffling¶
要重新排序变量的尺寸,要插入或删除broadcastable的维,请参阅_tensor_py_operators.dimshuffle()。
-
theano.tensor.reshape(x, newshape, ndim=None)[source]¶ Parameters: - x(任何TensorVariable (或兼容的)) —— 要reshape的变量
- newshape(lvector(或兼容的)) —— x的新形状
- ndim(可选) —— newshape的值将具有的长度。如果它为
None,则reshape()将从newshape推断它。
Return type: x的dtype型的变量,但维度为ndim
Note
这个函数可以在某些情况下推断符号newshape的长度,但如果不能而且你没有提供ndim,那么这个函数将引发异常。
-
theano.tensor.shape_padleft(x, n_ones=1)[source]¶ Reshape x by left padding the shape with n_ones 1s. Note that all this new dimension will be broadcastable. To make them non-broadcastable see the
unbroadcast().Parameters: x (any TensorVariable (or compatible)) – variable to be reshaped
-
theano.tensor.shape_padright(x, n_ones=1)[source]¶ Reshape x by right padding the shape with n_ones 1s. Note that all this new dimension will be broadcastable. To make them non-broadcastable see the
unbroadcast().Parameters: x (any TensorVariable (or compatible)) – variable to be reshaped
-
theano.tensor.shape_padaxis(t, axis)[source]¶ Reshape t by inserting 1 at the dimension axis. Note that this new dimension will be broadcastable. To make it non-broadcastable see the
unbroadcast().Parameters: - x (any TensorVariable (or compatible)) – variable to be reshaped
- axis (int) – axis where to add the new dimension to x
Example:
>>> tensor = theano.tensor.tensor3() >>> theano.tensor.shape_padaxis(tensor, axis=0) InplaceDimShuffle{x,0,1,2}.0 >>> theano.tensor.shape_padaxis(tensor, axis=1) InplaceDimShuffle{0,x,1,2}.0 >>> theano.tensor.shape_padaxis(tensor, axis=3) InplaceDimShuffle{0,1,2,x}.0 >>> theano.tensor.shape_padaxis(tensor, axis=-1) InplaceDimShuffle{0,1,2,x}.0
-
theano.tensor.unbroadcast(x, *axes)[source]¶ 使输入不能在指定的轴上broadcast。
例如,addbroadcast(x, 0)将使x的第一个维度broadcastable。When performing the function, if the length of x along that dimension is not 1, a ValueError will be raised.
这里我们应用这个操作是为了不污染图,特别是在gpu优化期间
Parameters: - x(tensor_like) —— 输入的theano张量。
- axis(一个整数或一个可迭代对象,例如整数组成的列表或元组) —— 张量x沿着这个维度应当unbroadcastable。If the length of x along these dimensions is not 1, a ValueError will be raised.
Returns: 一个theano张量,沿着指定的维度unbroadcastable。
Return type:
-
theano.tensor.addbroadcast(x, *axes)[source]¶ Make the input broadcastable in the specified axes.
For example, addbroadcast(x, 0) will make the first dimension of x broadcastable. When performing the function, if the length of x along that dimension is not 1, a ValueError will be raised.
这里我们应用这个操作是为了不污染图,特别是在gpu优化期间
Parameters: - x(tensor_like) —— 输入的theano张量。
- axis(一个整数或一个可迭代对象,例如整数组成的列表或元组) —— 张量x沿着这个维度应当broadcastable。If the length of x along these dimensions is not 1, a ValueError will be raised.
Returns: 一个theano张量,它沿着指定的维度broadcastable。
Return type:
-
theano.tensor.patternbroadcast(x, broadcastable)[source]¶ 使输入采用特定的broadcasting模式。
Broadcastable must be iterable. 例如,patternbroadcast(x, (True, False))将使得第一个维度broadcastable,第二个维不可broadcastable,因此x现在是一个行。
这里我们应用这个操作是为了不污染图,特别是在gpu优化期间。
Parameters: - x(tensor_like) —— 输入的theano张量。
- broadcastable(一个可迭代对象,例如布尔值组成的列表或元组)—— 一组布尔值,表示某个维度是否应该broadcastable。If the length of x along these dimensions is not 1, a ValueError will be raised.
Returns: 一个theano张量,它沿着指定的维度unbroadcastable 。
Return type:
-
theano.tensor.flatten(x, outdim=1)[source]¶ Similar to
reshape(), but the shape is inferred from the shape of x.Parameters: - x (any TensorVariable (or compatible)) – variable to be flattened
- outdim (int) – the number of dimensions in the returned variable
Return type: 变量,dtype与x相同且维度为outdim
Returns: variable with the same shape as x in the leading outdim-1 dimensions, but with all remaining dimensions of x collapsed into the last dimension.
例如,如果我们用flatten(x, outdim=2)将形状为(2,3,4,5)的张量展平,那么我们将具有相同的(2-1=1)前导维度(2,),而其余维度被折叠。所以在这个例子中的输出将具有形状(2, 60)。
-
theano.tensor.tile(x, reps, ndim=None)[source]¶ Construct an array by repeating the input x according to reps pattern.
Tiles its input according to reps. The length of reps is the number of dimension of x and contains the number of times to tile x in each dimension.
See: numpy.tile documentation for examples. See: theano.tensor.extra_ops.repeatNote: Currently, reps must be a constant, x.ndim and len(reps) must be equal and, if specified, ndim must be equal to both.
-
theano.tensor.roll(x, shift, axis=None)[source]¶ Convenience function to roll TensorTypes along the given axis.
Syntax copies numpy.roll function.
Parameters: - x (tensor_like) – Input tensor.
- shift (int (symbolic or literal)) – The number of places by which elements are shifted.
- axis (int (symbolic or literal), optional) – The axis along which elements are shifted. By default, the array is flattened before shifting, after which the original shape is restored.
Returns: Output tensor, with the same shape as
x.Return type:
创建张量¶
-
theano.tensor.zeros_like(x, dtype=None)[source]¶ Parameters: - x —— 具有与输出形状相同的张量
- dtype —— data-type,可选。缺省情况下,它为x.dtype。
返回一个张量,具有x的形状并填充dtype类型的零。
-
theano.tensor.ones_like(x)[source]¶ Parameters: - x — 与输出形状相同的张量
- dtype — data-type,可选。默认情况下为x.dtype。
返回一个张量,形状与x相同,以dtype类型的1填充。
-
theano.tensor.zeros(shape, dtype=None)[source]¶ Parameters: - shape – a tuple/list of scalar with the shape information.
- dtype – the dtype of the new tensor. If None, will use floatX.
Returns a tensor filled with 0s of the provided shape.
-
theano.tensor.ones(shape, dtype=None)[source]¶ Parameters: - shape – a tuple/list of scalar with the shape information.
- dtype – the dtype of the new tensor. If None, will use floatX.
Returns a tensor filled with 1s of the provided shape.
-
theano.tensor.fill(a, b)[source]¶ Parameters: - a – tensor that has same shape as output
- b – theano scalar or value with which you want to fill the output
Create a matrix by filling the shape of a with b
-
theano.tensor.alloc(value, *shape)[source]¶ Parameters: - value – a value with which to fill the output
- shape – the dimensions of the returned array
Returns: 由value初始化并具有指定形状的N维张量。
-
theano.tensor.eye(n, m=None, k=0, dtype=theano.config.floatX)[source]¶ Parameters: - n – number of rows in output (value or theano scalar)
- m – number of columns in output (value or theano scalar)
- k – Index of the diagonal: 0 refers to the main diagonal, a positive value refers to an upper diagonal, and a negative value to a lower diagonal. It can be a theano scalar.
Returns: An array where all elements are equal to zero, except for the k-th diagonal, whose values are equal to one.
-
theano.tensor.identity_like(x)[source]¶ Parameters: x – tensor Returns: A tensor of same shape as x that is filled with 0s everywhere except for the main diagonal, whose values are equal to one. The output will have same dtype as x.
-
theano.tensor.stack(tensors, axis=0)[source]¶ Stack tensors in sequence on given axis (default is 0).
Take a sequence of tensors and stack them on given axis to make a single tensor. The size in dimension axis of the result will be equal to the number of tensors passed.
Parameters: - tensors – a list or a tuple of one or more tensors of the same rank.
- axis – the axis along which the tensors will be stacked. Default value is 0.
Returns: A tensor such that rval[0] == tensors[0], rval[1] == tensors[1], etc.
Examples:
>>> a = theano.tensor.scalar() >>> b = theano.tensor.scalar() >>> c = theano.tensor.scalar() >>> x = theano.tensor.stack([a, b, c]) >>> x.ndim # x is a vector of length 3. 1 >>> a = theano.tensor.tensor4() >>> b = theano.tensor.tensor4() >>> c = theano.tensor.tensor4() >>> x = theano.tensor.stack([a, b, c]) >>> x.ndim # x is a 5d tensor. 5 >>> rval = x.eval(dict((t, np.zeros((2, 2, 2, 2))) for t in [a, b, c])) >>> rval.shape # 3 tensors are stacked on axis 0 (3, 2, 2, 2, 2)
We can also specify different axis than default value 0
>>> x = theano.tensor.stack([a, b, c], axis=3) >>> x.ndim 5 >>> rval = x.eval(dict((t, np.zeros((2, 2, 2, 2))) for t in [a, b, c])) >>> rval.shape # 3 tensors are stacked on axis 3 (2, 2, 2, 3, 2) >>> x = theano.tensor.stack([a, b, c], axis=-2) >>> x.ndim 5 >>> rval = x.eval(dict((t, np.zeros((2, 2, 2, 2))) for t in [a, b, c])) >>> rval.shape # 3 tensors are stacked on axis -2 (2, 2, 2, 3, 2)
theano.tensor.stack(*tensors)[source]Warning
接口stack(*tensors)已废弃!使用stack(tensors, axis=0)。
Stack tensors in sequence vertically (row wise).
Take a sequence of tensors and stack them vertically to make a single tensor.
Parameters: tensors – one or more tensors of the same rank Returns: A tensor such that rval[0] == tensors[0], rval[1] == tensors[1], etc. >>> x0 = T.scalar() >>> x1 = T.scalar() >>> x2 = T.scalar() >>> x = T.stack(x0, x1, x2) >>> x.ndim # x is a vector of length 3. 1
-
theano.tensor.concatenate(tensor_list, axis=0)[source]¶ Parameters: - tensor_list (a list or tuple of Tensors that all have the same shape in the axes not specified by the axis argument.) – one or more Tensors to be concatenated together into one.
- axis (literal or symbolic integer) – Tensors will be joined along this axis, so they may have different
shape[axis]
>>> x0 = T.fmatrix() >>> x1 = T.ftensor3() >>> x2 = T.fvector() >>> x = T.concatenate([x0, x1[0], T.shape_padright(x2)], axis=1) >>> x.ndim 2
-
theano.tensor.stacklists(tensor_list)[source]¶ Parameters: tensor_list (an iterable that contains either tensors or other iterables of the same type as tensor_list (in other words, this is a tree whose leaves are tensors).) – tensors to be stacked together. Recursively stack lists of tensors to maintain similar structure.
This function can create a tensor from a shaped list of scalars:
>>> from theano.tensor import stacklists, scalars, matrices >>> from theano import function >>> a, b, c, d = scalars('abcd') >>> X = stacklists([[a, b], [c, d]]) >>> f = function([a, b, c, d], X) >>> f(1, 2, 3, 4) array([[ 1., 2.], [ 3., 4.]])
We can also stack arbitrarily shaped tensors. Here we stack matrices into a 2 by 2 grid:
>>> from numpy import ones >>> a, b, c, d = matrices('abcd') >>> X = stacklists([[a, b], [c, d]]) >>> f = function([a, b, c, d], X) >>> x = ones((4, 4), 'float32') >>> f(x, x, x, x).shape (2, 2, 4, 4)
-
theano.tensor.basic.choose(a, choices, out=None, mode='raise')[source]¶ Construct an array from an index array and a set of arrays to choose from.
First of all, if confused or uncertain, definitely look at the Examples - in its full generality, this function is less simple than it might seem from the following code description (below ndi = numpy.lib.index_tricks):
np.choose(a,c) == np.array([c[a[I]][I] for I in ndi.ndindex(a.shape)]).
But this omits some subtleties. Here is a fully general summary:
Given an
indexarray (a) of integers and a sequence of n arrays (choices), a and each choice array are first broadcast, as necessary, to arrays of a common shape; calling these Ba and Bchoices[i], i = 0,...,n-1 we have that, necessarily, Ba.shape == Bchoices[i].shape for each i. Then, a new array with shape Ba.shape is created as follows:- if mode=raise (the default), then, first of all, each element of a (and thus Ba) must be in the range [0, n-1]; now, suppose that i (in that range) is the value at the (j0, j1, ..., jm) position in Ba - then the value at the same position in the new array is the value in Bchoices[i] at that same position;
- if mode=wrap, values in a (and thus Ba) may be any (signed) integer; modular arithmetic is used to map integers outside the range [0, n-1] back into that range; and then the new array is constructed as above;
- if mode=clip, values in a (and thus Ba) may be any (signed) integer; negative integers are mapped to 0; values greater than n-1 are mapped to n-1; and then the new array is constructed as above.
Parameters: - a (int array) – This array must contain integers in [0, n-1], where n is the number of choices, unless mode=wrap or mode=clip, in which cases any integers are permissible.
- choices (sequence of arrays) – Choice arrays. a and all of the choices must be broadcastable to the same shape. If choices is itself an array (not recommended), then its outermost dimension (i.e., the one corresponding to choices.shape[0]) is taken as defining the
sequence. - out (array, optional) – If provided, the result will be inserted into this array. It should be of the appropriate shape and dtype.
- mode ({
raise(default),wrap,clip}, optional) – Specifies how indices outside [0, n-1] will be treated:raise: an exception is raisedwrap: value becomes value mod nclip: values < 0 are mapped to 0, values > n-1 are mapped to n-1
Returns: The merged result.
Return type: merged_array - array
Raises: ValueError - shape mismatch – If a and each choice array are not all broadcastable to the same shape.
归约¶
-
theano.tensor.max(x, axis=None, keepdims=False)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis or axes along which to compute the maximum Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor. Returns: maximum of x along axis - axis can be:
- None - in which case the maximum is computed along all axes (like numpy)
- an int - computed along this axis
- a list of ints - computed along these axes
-
theano.tensor.argmax(x, axis=None, keepdims=False)[source]¶ Parameter: x — 符号张量(或兼容的) Parameter: axis — 沿其计算最大值的索引的轴 Parameter: keepdims —(布尔)如果设置为True,则规约的轴将留在结果中作为大小为1的维。使用此选项,结果将相对原始张量正确broadcast 。 Returns: the index of the maximum value along a given axis - 如果axis = None,Theano 0.5rc1或更高版本:argmax则在扁平化的张量上计算(类似numpy)
- old:那么轴被假定为ndim(x)-1
-
theano.tensor.max_and_argmax(x, axis=None, keepdims=False)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis along which to compute the maximum and its index Parameter: keepdims - (boolean) If this is set to True, the axis which is reduced is left in the result as a dimension with size one. With this option, the result will broadcast correctly against the original tensor. Returns: the maxium value along a given axis and its index. - if axis=None, Theano 0.5rc1 or later: max_and_argmax over the flattened tensor (like numpy)
- older: then axis is assumed to be ndim(x)-1
-
theano.tensor.min(x, axis=None, keepdims=False)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis or axes along which to compute the minimum Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor. Returns: minimum of x along axis - axis can be:
- None - in which case the minimum is computed along all axes (like numpy)
- an int - computed along this axis
- a list of ints - computed along these axes
-
theano.tensor.argmin(x, axis=None, keepdims=False)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis along which to compute the index of the minimum Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor. Returns: the index of the minimum value along a given axis - if axis=None, Theano 0.5rc1 or later: argmin over the flattened tensor (like numpy)
- older: then axis is assumed to be ndim(x)-1
-
theano.tensor.sum(x, axis=None, dtype=None, keepdims=False, acc_dtype=None)[source]¶ Parameter: x - symbolic Tensor (or compatible)
Parameter: axis — 一个或多个轴,将沿着它(们)计算和
Parameter: dtype - The dtype of the returned tensor. If None, then we use the default dtype which is the same as the input tensor’s dtype except when:
- the input dtype is a signed integer of precision < 64 bit, in which case we use int64
- the input dtype is an unsigned integer of precision < 64 bit, in which case we use uint64
This default dtype does _not_ depend on the value of “acc_dtype”.
Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor.
Parameter: acc_dtype - The dtype of the internal accumulator. If None (default), we use the dtype in the list below, or the input dtype if its precision is higher:
- for int dtypes, we use at least int64;
- for uint dtypes, we use at least uint64;
- for float dtypes, we use at least float64;
- for complex dtypes, we use at least complex128.
Returns: x沿axis的和
- axis可以是:
- None — 在这种情况下,沿所有轴计算和(类似numpy)
- 一个int — 沿这个轴计算
- 一个int的列表 — 沿这些轴计算
-
theano.tensor.prod(x, axis=None, dtype=None, keepdims=False, acc_dtype=None, no_zeros_in_input=False)[source]¶ Parameter: x - symbolic Tensor (or compatible)
Parameter: axis - axis or axes along which to compute the product
Parameter: dtype - The dtype of the returned tensor. If None, then we use the default dtype which is the same as the input tensor’s dtype except when:
- the input dtype is a signed integer of precision < 64 bit, in which case we use int64
- the input dtype is an unsigned integer of precision < 64 bit, in which case we use uint64
This default dtype does _not_ depend on the value of “acc_dtype”.
Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor.
Parameter: acc_dtype - The dtype of the internal accumulator. If None (default), we use the dtype in the list below, or the input dtype if its precision is higher:
- for int dtypes, we use at least int64;
- for uint dtypes, we use at least uint64;
- for float dtypes, we use at least float64;
- for complex dtypes, we use at least complex128.
Parameter: no_zeros_in_input - The grad of prod is complicated as we need to handle 3 different cases: without zeros in the input reduced group, with 1 zero or with more zeros.
This could slow you down, but more importantly, we currently don’t support the second derivative of the 3 cases. So you cannot take the second derivative of the default prod().
To remove the handling of the special cases of 0 and so get some small speed up and allow second derivative set
no_zeros_in_inputstoTrue. It defaults toFalse.It is the user responsibility to make sure there are no zeros in the inputs. If there are, the grad will be wrong.
Returns: product of every term in x along axis
- axis can be:
- None - in which case the sum is computed along all axes (like numpy)
- an int - computed along this axis
- a list of ints - computed along these axes
-
theano.tensor.mean(x, axis=None, dtype=None, keepdims=False, acc_dtype=None)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis or axes along which to compute the mean Parameter: dtype - The dtype to cast the result of the inner summation into. For instance, by default, a sum of a float32 tensor will be done in float64 (acc_dtype would be float64 by default), but that result will be casted back in float32. Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor. Parameter: acc_dtype - The dtype of the internal accumulator of the inner summation. This will not necessarily be the dtype of the output (in particular if it is a discrete (int/uint) dtype, the output will be in a float type). If None, then we use the same rules as sum().Returns: mean value of x along axis - axis can be:
- None - in which case the mean is computed along all axes (like numpy)
- an int - computed along this axis
- a list of ints - computed along these axes
-
theano.tensor.var(x, axis=None, keepdims=False)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis or axes along which to compute the variance Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor. Returns: variance of x along axis - axis can be:
- None - in which case the variance is computed along all axes (like numpy)
- an int - computed along this axis
- a list of ints - computed along these axes
-
theano.tensor.std(x, axis=None, keepdims=False)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis or axes along which to compute the standard deviation Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor. Returns: variance of x along axis - axis can be:
- None - in which case the standard deviation is computed along all axes (like numpy)
- an int - computed along this axis
- a list of ints - computed along these axes
-
theano.tensor.all(x, axis=None, keepdims=False)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis or axes along which to apply ‘bitwise and’ Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor. Returns: bitwise and of x along axis - axis can be:
- None - in which case the ‘bitwise and’ is computed along all axes (like numpy)
- an int - computed along this axis
- a list of ints - computed along these axes
-
theano.tensor.any(x, axis=None, keepdims=False)[source]¶ Parameter: x - symbolic Tensor (or compatible) Parameter: axis - axis or axes along which to apply bitwise or Parameter: keepdims - (boolean) If this is set to True, the axes which are reduced are left in the result as dimensions with size one. With this option, the result will broadcast correctly against the original tensor. Returns: bitwise or of x along axis - axis can be:
- None - in which case the ‘bitwise or’ is computed along all axes (like numpy)
- an int - computed along this axis
- a list of ints - computed along these axes
-
theano.tensor.ptp(x, axis = None)[source]¶ Range of values (maximum - minimum) along an axis. The name of the function comes from the acronym for peak to peak.
Parameter: x Input tensor. Parameter: axis Axis along which to find the peaks. By default, flatten the array. Returns: A new array holding the result.
索引¶
Like NumPy, Theano distinguishes between basic and advanced indexing. Theano fully supports basic indexing (see NumPy’s indexing) and integer advanced indexing. We do not support boolean masks, as Theano does not have a boolean type (we use int8 for the output of logic operators).
NumPy with a mask:
>>> n = np.arange(9).reshape(3,3)
>>> n[n > 4]
array([5, 6, 7, 8])
Theano indexing with a “mask” (incorrect approach):
>>> t = theano.tensor.arange(9).reshape((3,3))
>>> t[t > 4].eval() # an array with shape (3, 3, 3)
Traceback (most recent call last):
...
TypeError: TensorType does not support boolean mask for indexing such as tensor[x==0].
Instead you can use non_zeros() such as tensor[(x == 0).nonzeros()].
If you are indexing on purpose with an int8, please cast it to int16.
获取像NumPy的一个Theano结果:
>>> t[(t > 4).nonzero()].eval()
array([5, 6, 7, 8])
索引赋值不支持。如果你想做像a[5] = b或a[5]+=b,请参阅theano.tensor.set_subtensor()和theano.tensor.inc_subtensor()。
-
theano.tensor.set_subtensor(x, y, inplace=False, tolerate_inplace_aliasing=False)[source]¶ Return x with the given subtensor overwritten by y.
Parameters: - x —— 等号操作左值的符号变量。
- y —— 等号操作右值的符号变量。
- tolerate_inplace_aliasing —— 请参阅inc_subtensor文档。
Examples
要得到numpy的表达式“r[10:] = 5”的等效操作,请键入
>>> r = ivector() >>> new_r = set_subtensor(r[10:], 5)
-
theano.tensor.inc_subtensor(x, y, inplace=False, set_instead_of_inc=False, tolerate_inplace_aliasing=False)[source]¶ 返回x,其给定的subtensor增加y。
Parameters: - x —— Subtensor操作的符号结果。
- y —— 给所讨论的subtensor增加的值。
- inplace —— 不要使用。Theano will do it when possible.
- set_instead_of_inc —— 如果为True,则改用set_subtensor。
- tolerate_inplace_aliasing —— 允许x和y是单个底层数组的视图,即使在原位工作。为了正确的结果,x和y不能是重叠的视图;如果它们重叠,则该操作的结果通常是不正确的。如果inplace= alse,则此值不起作用。
Examples
要复制numpy表达式“r[10:] += 5”,请键入
>>> r = ivector() >>> new_r = inc_subtensor(r[10:], 5)
运算符的支持¶
Many Python operators are supported.
>>> a, b = T.itensor3(), T.itensor3() # example inputs
算数运算¶
>>> a + 3 # T.add(a, 3) -> itensor3
>>> 3 - a # T.sub(3, a)
>>> a * 3.5 # T.mul(a, 3.5) -> ftensor3 or dtensor3 (depending on casting)
>>> 2.2 / a # T.truediv(2.2, a)
>>> 2.2 // a # T.intdiv(2.2, a)
>>> 2.2**a # T.pow(2.2, a)
>>> b % a # T.mod(b, a)
位级别的运算¶
>>> a & b # T.and_(a,b) bitwise and (alias T.bitwise_and)
>>> a ^ 1 # T.xor(a,1) bitwise xor (alias T.bitwise_xor)
>>> a | b # T.or_(a,b) bitwise or (alias T.bitwise_or)
>>> ~a # T.invert(a) bitwise invert (alias T.bitwise_not)
原位运算¶
原位运算符不支持。Theano的图优化将确定用于原位运算的中间值。如果你想更新shared variable的值,请考虑使用theano.function()的updates参数。
元素级别的运算¶
类型转换¶
-
theano.tensor.cast(x, dtype)[source]¶ 将任何张量x cast为相同形状的Tensor,但具有不同的数值类型dtype。
这不是reinterpret cast,而是类似于
numpy.asarray(x, dtype=dtype)的coersion cast。import theano.tensor as T x = T.matrix() x_as_int = T.cast(x, 'int32')
尝试cast一个复数值为实数值是有歧义的,并会引发异常。使用real()、imag()、abs()或angle()。
比较运算¶
- 通常的六个相等和不相等运算符共享同一个接口。
Parameter: a —— 符号张量(或兼容的) Parameter: b —— 符号张量(或兼容的) Return type: 符号张量 Returns: 一个符号张量,表示元素级别逻辑运算符的应用结果。 Note
Theano has no boolean dtype. 取而代之的是,所有布尔张量用
'int8'表示。下面是一个使用小于运算符的示例。
import theano.tensor as T x,y = T.dmatrices('x','y') z = T.le(x,y)
-
theano.tensor.lt(a, b)[source]¶ Returns a symbolic
'int8'tensor representing the result of logical less-than (a也可以使用语法
a < b
-
theano.tensor.gt(a, b)[source]¶ Returns a symbolic
'int8'tensor representing the result of logical greater-than (a>b).Also available using syntax
a > b
-
theano.tensor.le(a, b)[source]¶ Returns a variable representing the result of logical less than or equal (a<=b).
Also available using syntax
a <= b
-
theano.tensor.ge(a, b)[source]¶ Returns a variable representing the result of logical greater or equal than (a>=b).
Also available using syntax
a >= b
-
theano.tensor.eq(a, b)[source]¶ Returns a variable representing the result of logical equality (a==b).
-
theano.tensor.neq(a, b)[source]¶ Returns a variable representing the result of logical inequality (a!=b).
-
theano.tensor.isnan(a)[source]¶ Returns a variable representing the comparison of
aelements with nan.This is equivalent to
numpy.isnan.
-
theano.tensor.isinf(a)[source]¶ Returns a variable representing the comparison of
aelements with inf or -inf.This is equivalent to
numpy.isinf.
-
theano.tensor.isclose(a, b, rtol=1e-05, atol=1e-08, equal_nan=False)[source]¶ Returns a symbolic
'int8'tensor representing where two tensors are equal within a tolerance.The tolerance values are positive, typically very small numbers. The relative difference (rtol * abs(b)) and the absolute difference atol are added together to compare against the absolute difference between a and b.
For finite values, isclose uses the following equation to test whether two floating point values are equivalent:
|a - b| <= (atol + rtol * |b|)For infinite values, isclose checks if both values are the same signed inf value.
If equal_nan is True, isclose considers NaN values in the same position to be close. Otherwise, NaN values are not considered close.
This is equivalent to
numpy.isclose.
条件¶
-
theano.tensor.switch(cond, ift, iff)[source]¶ - Returns a variable representing a switch between ift (iftrue) and iff (iffalse)
based on the condition cond. 这是theano中相当于numpy.where的运算。
Parameter: cond —— 符号张量(或兼容的) Parameter: ift —— 符号张量(或兼容的) Parameter: iff —— 符号张量(或兼容的) Return type: 符号张量
import theano.tensor as T a,b = T.dmatrices('a','b') x,y = T.dmatrices('x','y') z = T.switch(T.lt(a,b), x, y)
位级别的运算¶
- 位级别的运算符拥有这个接口:
Parameter: a - symbolic Tensor of integer type. Parameter: b - symbolic Tensor of integer type. Note
The bitwise operators must have an integer type as input.
The bit-wise not (invert) takes only one parameter.
Return type: symbolic Tensor with corresponding dtype.
Here is an example using the bit-wise and_ via the & operator:
import theano.tensor as T
x,y = T.imatrices('x','y')
z = x & y
数学运算¶
-
theano.tensor.abs_(a)[source]¶ Returns a variable representing the absolute of a, ie
|a|.Note
Can also be accessed with
abs(a).
-
theano.tensor.angle(a)[source]¶ Returns a variable representing angular component of complex-valued Tensor a.
-
theano.tensor.maximum(a, b)[source]¶ Returns a variable representing the maximum element by element of a and b
-
theano.tensor.minimum(a, b)[source]¶ Returns a variable representing the minimum element by element of a and b
-
theano.tensor.inv(a)[source]¶ Returns a variable representing the inverse of a, ie 1.0/a. Also called reciprocal.
-
theano.tensor.log(a), log2(a), log10(a)[source]¶ Returns a variable representing the base e, 2 or 10 logarithm of a.
-
theano.tensor.ceil(a)[source]¶ Returns a variable representing the ceiling of a (for example ceil(2.1) is 3).
-
theano.tensor.floor(a)[source]¶ Returns a variable representing the floor of a (for example floor(2.9) is 2).
-
theano.tensor.round(a, mode="half_away_from_zero")[source]¶ Returns a variable representing the rounding of a in the same dtype as a. Implemented rounding mode are half_away_from_zero and half_to_even.
-
theano.tensor.iround(a, mode="half_away_from_zero")[source]¶ Short hand for cast(round(a, mode),’int64’).
-
theano.tensor.cos(a), sin(a), tan(a)[source]¶ Returns a variable representing the trigonometric functions of a (cosine, sine and tangent).
-
theano.tensor.erf(a), erfc(a)[source]¶ Returns a variable representing the error function or the complementary error function. wikipedia
-
theano.tensor.erfinv(a), erfcinv(a)[source]¶ Returns a variable representing the inverse error function or the inverse complementary error function. wikipedia
-
theano.tensor.gammaln(a)[source]¶ Returns a variable representing the logarithm of the gamma function.
-
theano.tensor.psi(a)[source]¶ Returns a variable representing the derivative of the logarithm of the gamma function (also called the digamma function).
Theano和Numpy中的Broadcasting¶
Broadcasting是一种机制,通过沿着缺少的维度(虚拟地)复制较小张量,允许具有不同维度数量的张量相加或相乘。
Broadcasting是标量与矩阵相加、向量与矩阵相加、或标量与向量相加的机制。
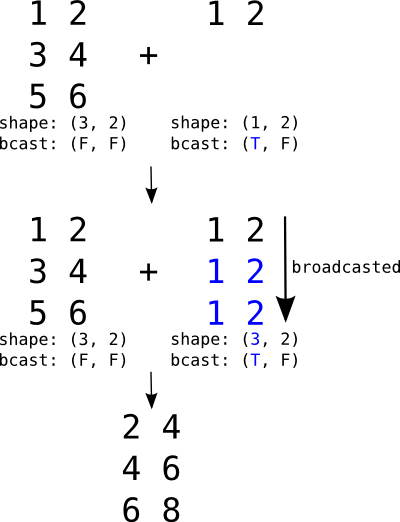
Broadcasting一个行矩阵。T和F分别代表True和False,表示我们允许broadcasting的维度。
如果第二个参数是向量,其形状将是(2,)及其broadcastable模式将为(F,)。它们将自动向左扩展以匹配矩阵的维度(将1添加到形状,将T添加到模式),结果为(1, 2)和(T, F)。It would then behave just like the example above.
与动态broadcasting的numpy不同,对于任何支持broadcasting的操作,Theano需要知道要broadcast哪些维度。如果适用,此信息在变量的Type中给出。
另见:
线性代数¶
-
theano.tensor.dot(X, Y)[source]¶ - 对于2-D数组,其等效于矩阵乘法,对于1-D数组等效于向量的内积(没有复共轭)。对于N维,它是a的最后一个轴和b的倒数第二个轴的积的和:
Parameters: - X(符号张量)— 左项
- Y(符号张量)— 右项
Return type: symbolic matrix or vector
Returns: the inner product of X and Y.
-
theano.tensor.outer(X, Y)[source]¶ Parameters: - X (symbolic vector) – left term
- Y (symbolic vector) – right term
Return type: symbolic matrix
Returns: vector-vector outer product
-
theano.tensor.tensordot(a, b, axes=2)[source]¶ Given two tensors a and b,tensordot computes a generalized dot product over the provided axes. Theano’s implementation reduces all expressions to matrix or vector dot products and is based on code from Tijmen Tieleman’s gnumpy (http://www.cs.toronto.edu/~tijmen/gnumpy.html).
Parameters: - a (symbolic tensor) – the first tensor variable
- b (symbolic tensor) – the second tensor variable
- axes (int or array-like of length 2) –
an integer or array. If an integer, the number of axes to sum over. If an array, it must have two array elements containing the axes to sum over in each tensor.
Note that the default value of 2 is not guaranteed to work for all values of a and b, and an error will be raised if that is the case. The reason for keeping the default is to maintain the same signature as numpy’s tensordot function (and np.tensordot raises analogous errors for non-compatible inputs).
If an integer i, it is converted to an array containing the last i dimensions of the first tensor and the first i dimensions of the second tensor:
axes = [range(a.ndim - i, b.ndim), range(i)]If an array, its two elements must contain compatible axes of the two tensors. For example, [[1, 2], [2, 0]] means sum over the 2nd and 3rd axes of a and the 3rd and 1st axes of b. (Remember axes are zero-indexed!) The 2nd axis of a and the 3rd axis of b must have the same shape; the same is true for the 3rd axis of a and the 1st axis of b.
Returns: a tensor with shape equal to the concatenation of a’s shape (less any dimensions that were summed over) and b’s shape (less any dimensions that were summed over).
Return type: symbolic tensor
It may be helpful to consider an example to see what tensordot does. Theano’s implementation is identical to NumPy’s. Here a has shape (2, 3, 4) and b has shape (5, 6, 4, 3). The axes to sum over are [[1, 2], [3, 2]] – note that a.shape[1] == b.shape[3] and a.shape[2] == b.shape[2]; these axes are compatible. The resulting tensor will have shape (2, 5, 6) – the dimensions that are not being summed:
import numpy as np a = np.random.random((2,3,4)) b = np.random.random((5,6,4,3)) #tensordot c = np.tensordot(a, b, [[1,2],[3,2]]) #loop replicating tensordot a0, a1, a2 = a.shape b0, b1, _, _ = b.shape cloop = np.zeros((a0,b0,b1)) #loop over non-summed indices -- these exist #in the tensor product. for i in range(a0): for j in range(b0): for k in range(b1): #loop over summed indices -- these don't exist #in the tensor product. for l in range(a1): for m in range(a2): cloop[i,j,k] += a[i,l,m] * b[j,k,m,l] assert np.allclose(c, cloop)
This specific implementation avoids a loop by transposing a and b such that the summed axes of a are last and the summed axes of b are first. The resulting arrays are reshaped to 2 dimensions (or left as vectors, if appropriate) and a matrix or vector dot product is taken. The result is reshaped back to the required output dimensions.
In an extreme case, no axes may be specified. The resulting tensor will have shape equal to the concatenation of the shapes of a and b:
>>> c = np.tensordot(a, b, 0) >>> a.shape (2, 3, 4) >>> b.shape (5, 6, 4, 3) >>> print(c.shape) (2, 3, 4, 5, 6, 4, 3)
Note: See the documentation of numpy.tensordot for more examples.
-
theano.tensor.batched_dot(X, Y)[source]¶ Parameters: - x – A Tensor with sizes e.g.: for 3D (dim1, dim3, dim2)
- y – A Tensor with sizes e.g.: for 3D (dim1, dim2, dim4)
This function computes the dot product between the two tensors, by iterating over the first dimension using scan. Returns a tensor of size e.g. if it is 3D: (dim1, dim3, dim4) Example:
>>> first = T.tensor3('first') >>> second = T.tensor3('second') >>> result = batched_dot(first, second)
Note: This is a subset of numpy.einsum, but we do not provide it for now. But numpy einsum is slower than dot or tensordot: http://mail.scipy.org/pipermail/numpy-discussion/2012-October/064259.html
Parameters: - X (symbolic tensor) – left term
- Y (symbolic tensor) – right term
Returns: tensor of products
-
theano.tensor.batched_tensordot(X, Y, axes=2)[source]¶ Parameters: - x – A Tensor with sizes e.g.: for 3D (dim1, dim3, dim2)
- y – A Tensor with sizes e.g.: for 3D (dim1, dim2, dim4)
- axes (int or array-like of length 2) –
an integer or array. If an integer, the number of axes to sum over. If an array, it must have two array elements containing the axes to sum over in each tensor.
If an integer i, it is converted to an array containing the last i dimensions of the first tensor and the first i dimensions of the second tensor (excluding the first (batch) dimension):
axes = [range(a.ndim - i, b.ndim), range(1,i+1)]
If an array, its two elements must contain compatible axes of the two tensors. For example, [[1, 2], [2, 4]] means sum over the 2nd and 3rd axes of a and the 3rd and 5th axes of b. (Remember axes are zero-indexed!) The 2nd axis of a and the 3rd axis of b must have the same shape; the same is true for the 3rd axis of a and the 5th axis of b.
Returns: a tensor with shape equal to the concatenation of a’s shape (less any dimensions that were summed over) and b’s shape (less first dimension and any dimensions that were summed over).
Return type: tensor of tensordots
A hybrid of batch_dot and tensordot, this function computes the tensordot product between the two tensors, by iterating over the first dimension using scan to perform a sequence of tensordots.
Note: See tensordot()andbatched_dot()for supplementary documentation.
-
theano.tensor.mgrid()[source]¶ Returns: an instance which returns a dense (or fleshed out) mesh-grid when indexed, so that each returned argument has the same shape. The dimensions and number of the output arrays are equal to the number of indexing dimensions. If the step length is not a complex number, then the stop is not inclusive. Example:
>>> a = T.mgrid[0:5, 0:3] >>> a[0].eval() array([[0, 0, 0], [1, 1, 1], [2, 2, 2], [3, 3, 3], [4, 4, 4]]) >>> a[1].eval() array([[0, 1, 2], [0, 1, 2], [0, 1, 2], [0, 1, 2], [0, 1, 2]])
-
theano.tensor.ogrid()[source]¶ Returns: an instance which returns an open (i.e. not fleshed out) mesh-grid when indexed, so that only one dimension of each returned array is greater than 1. The dimension and number of the output arrays are equal to the number of indexing dimensions. If the step length is not a complex number, then the stop is not inclusive. Example:
>>> b = T.ogrid[0:5, 0:3] >>> b[0].eval() array([[0], [1], [2], [3], [4]]) >>> b[1].eval() array([[0, 1, 2]])
梯度/微分¶
梯度计算的驱动程序。
theano.gradient.grad(cost, wrt, consider_constant=None, disconnected_inputs='raise', add_names=True, known_grads=None, return_disconnected='zero', null_gradients='raise')[source]返回某个cost对于一个或多个变量的符号梯度。
Theano中自动微分如何工作的有关更多信息,请参见
gradient。For information on how to implement the gradient of a certain Op, seegrad().Parameters: - cost(标量(0维)张量或None)— 我们微分所涉及的值。如果提供known_grads,可以为None。
- wrt(变量或变量列表)— 我们想要的梯度的项。
- consider_constant(变量列表)— 不反向传播的表达式。
- disconnected_inputs ({'ignore', 'warn', 'raise'}) —
如果wrt中的某些变量不是计算图计算cost的一部分(或者所有链接都是不可微分的),则定义相应的行为。The possible values are:
- ‘ignore’: considers that the gradient on these parameters is zero.
- 'warn':认为梯度为零,并打印警告。
- 'raise':引发DisconnectedInputError。
- add_names(布尔值)— 如果为True,grad生成的变量将命名为(d<cost.name>/d<wrt.name>),只要cost和wrt都具有名字。
- known_grads(dict,可选)— 一个字典,映射变量到其梯度。这在你知道一些变量的梯度但不知道原始cost的情况下是有用的。
- return_disconnected ({'zero', 'None', 'Disconnected'}) —
- ‘zero’ :如果wrt[i]断开,返回值i将为
- wrt[i].zeros_like()
- ‘None’ : 如果wrt[i]断开,返回值i将为
- None
- ‘Disconnected’ : returns variables of type DisconnectedType
- null_gradients ({'raise', 'return'}) —
Defines the behaviour if some of the variables in wrt have a null gradient. The possibles values are:
- 'raise':引发一个NullTypeGradError异常
- 'return':返回空梯度
Returns: cost相对于wrt项中的每一个的梯度的符号表达式。If an element of wrt is not differentiable with respect to the output, then a zero variable is returned.
Return type: 变量或变量组成的列表/元组(匹配wrt)
See the gradient page for complete documentation of the gradient module.