
本教程描述如何使用机器学习按物种对鸢尾花进行分类。 它使用TensorFlow的eager执行来1. 建立一个模型;2. 在示例数据上训练模型;以及3. 使用模型对未知数据进行预测。 学习本指南不需要机器学习经验,但需要阅读一些Python代码。
TensorFlow编程
有许多TensorFlow API可用,但我们建议从这些高级别的TensorFlow概念开始:
- 启用eager执行开发环境,
- 使用Datasets API导入数据,
- 使用TensorFlow的Keras API构建模型和图层。
本教程讲述下面这些API,与许多其他TensorFlow程序结构相似:
- 导入和解析数据集。
- 选择模型的类型。
- 训练模型。
- 评估模型的有效性。
- 使用训练好的模型进行预测。
要了解有关使用TensorFlow的更多信息,请参阅入门指南和示例教程。 如果想了解机器学习的基础知识,请考虑参加机器学习速成课程。
运行这个笔记
本教程以交互式Colab笔记本形式提供,供你直接在浏览器中运行和更改Python代码。 该笔记本在你“运行”单元以执行代码块时处理安装和依赖关系。 这是探索程序和测试想法的有趣方式。 如果你对Python笔记本环境不熟悉,请牢记以下几点:
- 执行代码需要连接到运行时环境。 在Colab笔记本菜单中,选择 Runtime > Connect to runtime...
- 笔记本单元按顺序排列以逐渐构建程序。 通常,后面的代码单元依赖于先前的代码单元,但你始终可以重新运行代码块。 要按顺序执行整个笔记本,请选择Runtime > Run all。 要重新运行代码单元格,请选择单元格,然后单击左侧的运行图标。
安装程序
安装最新版本的TensorFlow
本教程使用TensorFlow 1.7中的eager执行功能。 (你可能需要在升级后重新启动运行时。)
!pip install -q --upgrade tensorflow
配置导入和eager执行
导入所需的Python模块,包括TensorFlow,并为该程序启用eager执行。 Eager执行使TensorFlow立即评估操作,返回具体值而不是创建稍后执行的计算图。 如果你习惯REPL或python交互式控制台,那么你会感到很习惯。
启用eager执行之后,就不能在同一个程序中禁用它。 有关更多详细信息,请参阅eager执行指南。
from __future__ import absolute_import, division, print_function
import os
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow.contrib.eager as tfe
tf.enable_eager_execution()
print("TensorFlow version: {}".format(tf.VERSION))
print("Eager execution: {}".format(tf.executing_eagerly()))
/usr/local/lib/python2.7/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`. from ._conv import register_converters as _register_converters
WARNING:tensorflow:From /usr/local/lib/python2.7/dist-packages/tensorflow/contrib/learn/python/learn/datasets/base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be removed in a future version. Instructions for updating: Use the retry module or similar alternatives. TensorFlow version: 1.7.0 Eager execution: True
鸢尾花分类问题
想象一下,你是一位植物学家,寻找一种自动化的方法对你发现的每个鸢尾花进行分类。 机器学习提供许多算法来对花朵进行统计分类。 例如,一个复杂的机器学习程序可以根据照片对花进行分类。 我们的目标要温和一些 — 我们将根据萼片和花瓣的长度和宽度测量值对鸢尾花进行分类。
鸢尾花属约有300种,但我们的程序将只分类以下三种:
- Iris setosa
- Iris virginica
- Iris versicolor

图1. Iris setosa (by Radomil, CC BY-SA 3.0), Iris versicolor (by Dlanglois, CC BY-SA 3.0), and Iris virginica (by Frank Mayfield, CC BY-SA 2.0).
幸运的是,有人已经创建了一个由120个鸢尾花组成的数据集,其中包括萼片和花瓣的测量结果。 这是一个流行的初学者机器学习分类问题的经典数据集。
导入并解析训练数据集
我们需要下载数据集文件并将其转换为可供此Python程序使用的结构。
下载数据集
使用tf.keras.utils.get_file函数下载训练数据集文件。 这将返回下载文件的文件路径。
train_dataset_url = "http://download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Downloading data from http://download.tensorflow.org/data/iris_training.csv 16384/2194 [================================================================================================================================================================================================================================] - 0s 0us/step Local copy of the dataset file: /root/.keras/datasets/iris_training.csv
检查数据
该数据集iris_training.csv是一个纯文本文件,它存储表格数据为逗号分隔值(CSV)的格式。 使用head -n5命令查看最前面五个条目:
!head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
从数据集的这个视图中,我们看到以下内容:
- 第一行是包含有关数据集信息的标题:
- 总共有120个样本。 每个样本都有四个特征和三个可能的标签名称之一。
- 后续行是数据记录,每行一个样本,其中:
- 前四个字段是特征:它们是一个样本的特征。 这里,这些字段为浮点数,表示花朵的测量值。
- 最后一列是标签:这是我们想要预测的值。 对于这个数据集,它是一个0、1或2的整数值,分别对应于一个花名。
每个标签都与字符串名称(例如,“setosa”)相关联,但机器学习通常依赖于数字值。 标签号码被映射到一个指定的表示,例如:
0: Iris setosa1: Iris versicolor2: Iris virginica
有关特征和标签的更多信息,请参阅机器学习速成课程的ML术语部分。
解析数据集
由于我们的数据集是CSV格式的文本文件,因此我们会将特征和标签值解析为我们的Python模型可以使用的格式。 文件中的每一行都被传递给parse_csv函数,该函数抓取前四个特征字段并将它们合并为一个张量。 然后,最后一个字段被解析为标签。 该函数将features和label张量同时返回:
def parse_csv(line):
example_defaults = [[0.], [0.], [0.], [0.], [0]] # sets field types
parsed_line = tf.decode_csv(line, example_defaults)
# First 4 fields are features, combine into single tensor
features = tf.reshape(parsed_line[:-1], shape=(4,))
# Last field is the label
label = tf.reshape(parsed_line[-1], shape=())
return features, label
创建training tf.data.Dataset
TensorFlow的Dataset API处理将数据提供给模型的许多常见情况。 它是一个读取数据并将其转换为用于训练形式的高级API。 有关更多信息,请参阅数据集快速入门指南。
该程序使用tf.data.TextLineDataset加载CSV格式的文本文件,并使用我们的parse_csv函数解析。 一个tf.data.Dataset将输入管道表示为元素的一个集合和在这些元素上的一系列转换。
转换方法可以链接在一起或按顺序调用 — 只要确保对返回的Dataset对象的引用。
如果样本是随机排列的,则训练效果最好。 使用tf.data.Dataset.shuffle将条目随机化,其中将buffer_size设置为大于样本数的值(本例中为120)。 为了更快地训练模型,数据集的批次大小被设置为32个样本同时训练。
train_dataset = tf.data.TextLineDataset(train_dataset_fp)
train_dataset = train_dataset.skip(1) # skip the first header row
train_dataset = train_dataset.map(parse_csv) # parse each row
train_dataset = train_dataset.shuffle(buffer_size=1000) # randomize
train_dataset = train_dataset.batch(32)
# View a single example entry from a batch
features, label = tfe.Iterator(train_dataset).next()
print("example features:", features[0])
print("example label:", label[0])
example features: tf.Tensor([4.6 3.2 1.4 0.2], shape=(4,), dtype=float32) example label: tf.Tensor(0, shape=(), dtype=int32)
选择模型的类型
为什么建模?
模型是特征和标签之间的关联关系。 对于鸢尾花分类问题,模型定义萼片和花瓣测量值与预测的鸢尾花物种之间的关系。 一些简单的模型可以用几行代数来描述,但是复杂的机器学习模型有很多参数,难以归纳它们。
你能否不使用机器学习来确定个四特征与鸢尾花物种之间的关系? 也就是说,你是否可以使用传统编程技术(例如,大量条件语句)来创建模型? 也许可以 — 如果你分析数据集的时间足够长,并确定花瓣和萼片测量值与一个特定的物种之间的关系。 这对于更复杂的数据集来说变得困难 — 也许是不可能的。 一个好的机器学习方法帮你决定模型。 如果你将足够多的代表样本提供给正确的机器学习模型类型,该程序将为你找出关系。
选择模型
我们需要选择训练模型的种类。 有许多类型的模型,挑选好的模型需要经验。 本教程使用神经网络来解决鸢尾花分类问题。 神经网络可以找到特征和标签之间的复杂关系。 它是一个高度结构化的图,组织成一个或多个隐藏层。 每个隐藏层由一个或多个神经元组成。 有几类神经网络,这个程序使用密集的或完全连接的神经网络:一层中的神经元接收来自前一层中每个神经元的输入连接。 例如,图2说明了一个由输入层、两个隐藏层和一个输出层组成的密集神经网络:
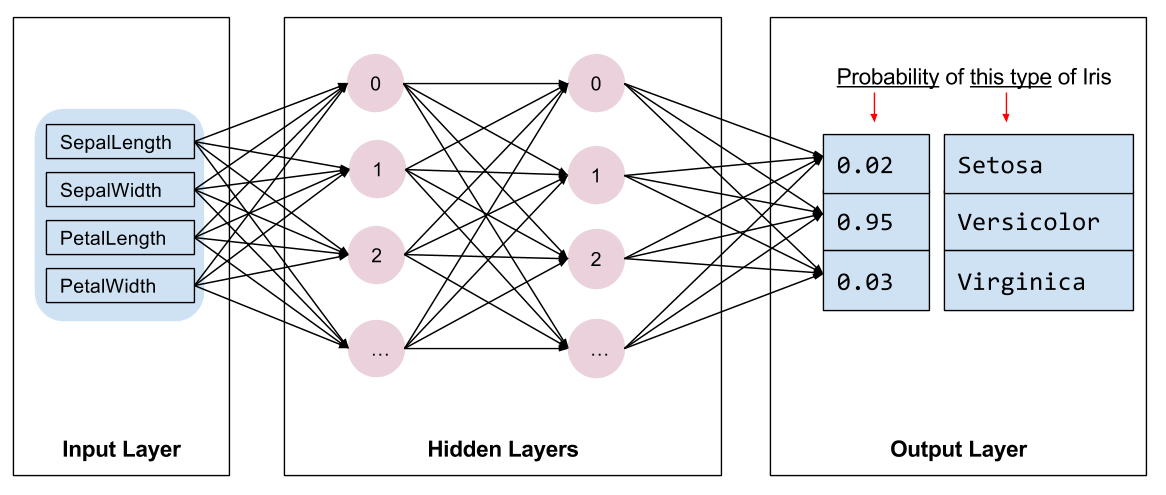
当图2的模型被训练并且提供一个未标记的样本时,它产生三个预测:该花是给定的鸢尾花物种的可能性。 这个预测被称为推断。 对于这个样本,输出预测的总和是1.0。 在图2中,这个预测分解为:Iris setosa为0.03,Iris versicolor为0.95,以及Iris virginica为0.02。 它表示该模型预测 — 以95%的概率 — 一个未标记的样本花是一种Iris versicolor。
使用Keras创建模型
TensorFlow tf.keras API是创建模型和图层的首选方式。 它使得构建模型和实验非常轻松,而Keras处理将所有内容连接在一起的复杂内容。 有关详细信息,请参阅Keras文档。
tf.keras.Sequential模型是一个线性栈图层。 它的构造函数接受一个图层实例列表,在这个例子中为两个各有10个节点的密集图层和一个有3个节点代表我们的标签预测的输出图层。 第一层的input_shape参数对应于数据集中特征的数量,并且是必需的。
model = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation="relu", input_shape=(4,)), # input shape required
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(3)
])
激活函数确定单个神经元到下一层的输出。 这是粗略地基于大脑神经元的连接方式。 有许多可用的激活函数,对隐藏图层ReLU是常见的激活函数。
隐藏层和神经元的理想数量取决于问题和数据集。 像机器学习的许多方面一样,选择神经网络的最佳形状需要知识和实验的混合。 作为一个经验法则,增加隐藏层和神经元的数量通常会创建一个更强大的模型,但需要更多的数据进行有效训练。
训练模型
训练是机器学习的一个阶段,这时模型逐渐优化或模型学习数据集。 我们的目标是充分了解训练数据集的结构,以预测未看到的数据。 如果你对训练数据集学习太多,那么预测只适用于所看到的数据,并且不会泛化。 这个问题被称为过拟合 — 这就像记忆答案而不是理解如何解决问题。
鸢尾花分类问题是监督机器学习的一个示例:模型是从包含标签的样本进行训练的。 在无监督机器学习中,样本不包含标签。 相反,该模型通常会在特征中找到模式。
定义损失和梯度函数
训练和评估阶段都需要计算模型的损失。 这可以衡量模型的预测与期望的标签有多大的差距,换句话说,模型的表现有多糟糕。 我们想要最小化或优化这个值。
我们的模型将使用tf.losses.sparse_softmax_cross_entropy函数来计算其损失,该函数接受模型的预测和想要的标签。 随着预测变差,返回的损失值逐渐增大。
def loss(model, x, y):
y_ = model(x)
return tf.losses.sparse_softmax_cross_entropy(labels=y, logits=y_)
def grad(model, inputs, targets):
with tfe.GradientTape() as tape:
loss_value = loss(model, inputs, targets)
return tape.gradient(loss_value, model.variables)
grad函数使用loss函数和tfe.GradientTape来记录计算梯度的操作以用于优化我们的模型。 有关更多示例,请参阅eager执行指南。
创建一个优化器
一个优化器将计算出的梯度应用于模型的变量,以最大限度地减少损失函数。 你可以想象一个曲面(见图3),我们希望通过走动找到最低点。 梯度指向上升速度最快的方向 — 所以我们将以相反的方式行进,并沿着山丘向下移动。 通过迭代计算每个步的损失和梯度(或学习速率),我们将在训练期间调整模型。 逐渐地,模型会找到权重和偏差的最佳组合,以最大限度地减少损失。 损失越低,模型的预测就越好。

TensorFlow有许多可用于训练的优化算法。 该模型使用实现标准梯度下降(SGD)算法的tf.train.GradientDescentOptimizer。 learning_rate设置每次迭代下的步长大小。
这是一个超参数,你通常会调整它以获得更好的结果。
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
训练循环
有了所有的代码块,模型已准备好训练! 训练循环将数据集样本输入到模型中,以帮助进行更好的预测。 以下代码块建立这些训练步骤:
- 迭代每个周期。 一个周期是数据集的一次遍历。
- 在周期内,根据其特征 (
x)和标签 (y),迭代训练数据集中的每个样本。 - 使用样本的特征,进行预测并将其与标签进行比较。 测量预测的不准确性并使用它来计算模型的损失和梯度。
- 使用
优化器更新模型的变量。 - 跟踪一些统计数据以进行可视化。
- 重复每个周期。
num_epochs变量是遍历数据集集合的次数。 与直觉相反,长时间训练模型并不能保证更好的模型。 num_epochs是你可以调整的超参数。 选择正确的数字通常需要经验和实验。
## Note: Rerunning this cell uses the same model variables
# keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tfe.metrics.Mean()
epoch_accuracy = tfe.metrics.Accuracy()
# Training loop - using batches of 32
for x, y in tfe.Iterator(train_dataset):
# Optimize the model
grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.variables),
global_step=tf.train.get_or_create_global_step())
# Track progress
epoch_loss_avg(loss(model, x, y)) # add current batch loss
# compare predicted label to actual label
epoch_accuracy(tf.argmax(model(x), axis=1, output_type=tf.int32), y)
# end epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
Epoch 000: Loss: 1.023, Accuracy: 35.000% Epoch 050: Loss: 0.477, Accuracy: 83.333% Epoch 100: Loss: 0.286, Accuracy: 95.000% Epoch 150: Loss: 0.188, Accuracy: 97.500% Epoch 200: Loss: 0.141, Accuracy: 97.500%
可视化损失函数随时间推移
虽然打印出模型的训练进度是有帮助的,但通常可视化这一进度更有帮助。 TensorBoard是一个很好的可视化工具,与TensorFlow打包在一起,但我们可以使用mathplotlib模块创建基本图表。
理解这些图表需要一些经验,但是您确实希望看到损失下降,准确率上升。
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()

评估模型的有效性
现在模型已经过训练,我们可以得到一些关于它的性能的统计数据。
评估表示确定模型如何有效地进行预测。 为了确定模型在鸢尾花分类中的有效性,将一些萼片和花瓣测量结果传递给模型,并要求模型预测它们所代表的鸢尾花种类。 然后将模型的预测与实际标签进行比较。 例如,在输入样本上选取一半正确物种的模型的准确率为0.5。
图4显示了一个稍微有效的模型,在5次预测中有4个正确,准确率为80%:
| 样本特征 | 标签 | 模型预测 | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
设置测试数据集
评估模型与训练模型相似。 最大的区别是样本来自一个单独的测试集而不是训练集。 为了公平评估模型的有效性,用于评估模型的样本必须与用于训练模型的样本不同。
测试数据集的设置类似于训练数据集的设置。 下载CSV文本文件并解析这些值,然后给它一点小小的搅乱:
test_url = "http://download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
test_dataset = tf.data.TextLineDataset(test_fp)
test_dataset = test_dataset.skip(1) # skip header row
test_dataset = test_dataset.map(parse_csv) # parse each row with the funcition created earlier
test_dataset = test_dataset.shuffle(1000) # randomize
test_dataset = test_dataset.batch(32) # use the same batch size as the training set
Downloading data from http://download.tensorflow.org/data/iris_test.csv 16384/573 [=========================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================] - 0s 0us/step
在测试数据集上评估模型
与训练阶段不同,该模型仅评估测试数据一个周期。 在下面的代码单元中,我们遍历测试集中的每个样本,并将模型的预测与实际标签进行比较。 这用于在整个测试集中测量模型的准确性。
test_accuracy = tfe.metrics.Accuracy()
for (x, y) in tfe.Iterator(test_dataset):
prediction = tf.argmax(model(x), axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 96.667%
使用训练好的模型进行预测
我们已经训练了一个模型并“证明”它在分类鸢尾属物种时是好的 — 但并不完美。 现在我们使用训练好的模型对未标记的样本做出一些预测;也就是说,在包含特征但没有标签的样本上。
在现实生活中,未标记的示例可能来自许多不同的来源,包括应用程序,CSV文件和数据馈送。 现在,我们将手动提供三个未标记的样本来预测其标签。 回想一下,标签号被映射到一个命名表示形式如下:
0: Iris setosa1: Iris versicolor2: Iris virginica
class_ids = ["Iris setosa", "Iris versicolor", "Iris virginica"]
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
predictions = model(predict_dataset)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
name = class_ids[class_idx]
print("Example {} prediction: {}".format(i, name))
Example 0 prediction: Iris setosa Example 1 prediction: Iris versicolor Example 2 prediction: Iris virginica
这些预测看起来不错!