


注意
here下载完整的示例代码
torchaudio 教程¶
PyTorch 是一个开源深度学习平台,提供从研究原型到生产环境部署的无缝衔接,并支持 GPU。
解决机器学习问题的大量工作在于数据准备。 torchaudio利用 PyTorch 的 GPU 支持,并提供许多工具,使数据加载变得简单和更具可读性。 在本教程中,我们将了解如何从简单数据集加载和预处理数据。
在本教程中,请确保安装了matplotlib包,以便更轻松地进行可视化。
import torch
import torchaudio
import matplotlib.pyplot as plt
打开一个数据集¶
torchaudio 支持以 wav 和 mp3 格式加载声音文件。 我们称波形为原始音频信号。
filename = "../_static/img/steam-train-whistle-daniel_simon-converted-from-mp3.wav"
waveform, sample_rate = torchaudio.load(filename)
print("Shape of waveform: {}".format(waveform.size()))
print("Sample rate of waveform: {}".format(sample_rate))
plt.figure()
plt.plot(waveform.t().numpy())
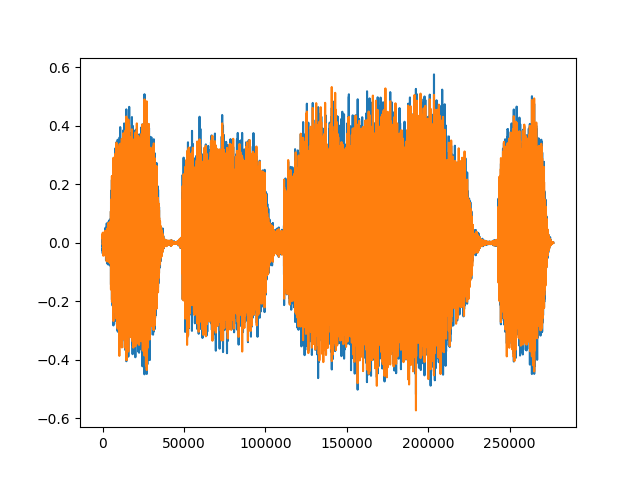
输出:
Shape of waveform: torch.Size([2, 276858])
Sample rate of waveform: 44100
转换¶
下面列出的是 torchaudio 支持的转换,这个列表还在不断增长中。
重采样:将波形重新采样到不同的采样率。
频谱图:从波形创建频谱图。
MelScale:它使用转换矩阵将普通 STFT 转换为梅尔频率 STFT。
AmplitudeToDB:它将一个频谱图从功率/振幅刻度转换为分贝刻度。
MFCC:从波形创建梅尔频率的cepstrum系数。
MelSpectrogram:使用 PyTorch 中的 STFT 函数从波形创建 MEL 频谱图。
MuLawEncoding:基于mu-law比较编码波形。
MuLawDecode:解码mu-law编码波形。
由于所有变换都是 nn.Modules 或 jit.ScriptModules,它们可以随时用作神经网络的一部分。
首先,我们可以以对数刻度查看频谱图的对数。
specgram = torchaudio.transforms.Spectrogram()(waveform)
print("Shape of spectrogram: {}".format(specgram.size()))
plt.figure()
plt.imshow(specgram.log2()[0,:,:].numpy(), cmap='gray')
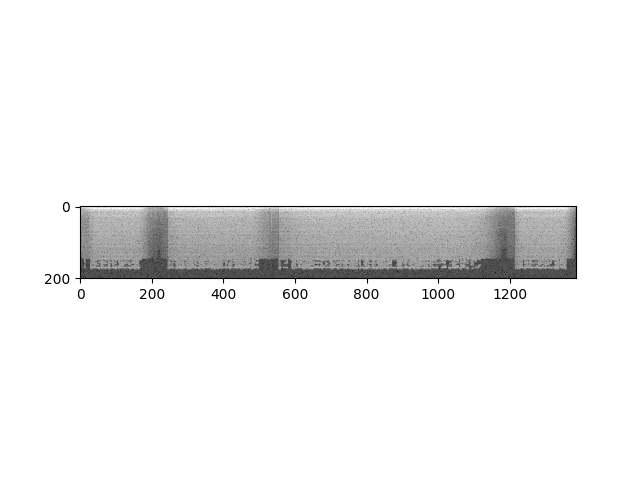
输出:
Shape of spectrogram: torch.Size([2, 201, 1385])
或者我们可以以对数刻度查看梅尔频谱图。
specgram = torchaudio.transforms.MelSpectrogram()(waveform)
print("Shape of spectrogram: {}".format(specgram.size()))
plt.figure()
p = plt.imshow(specgram.log2()[0,:,:].detach().numpy(), cmap='gray')
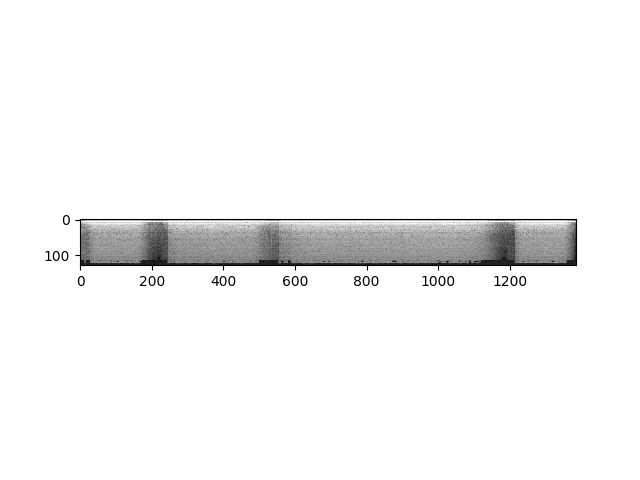
输出:
Shape of spectrogram: torch.Size([2, 128, 1385])
我们可以重新采样波形,一次一个通道。
new_sample_rate = sample_rate/10
# Since Resample applies to a single channel, we resample first channel here
channel = 0
transformed = torchaudio.transforms.Resample(sample_rate, new_sample_rate)(waveform[channel,:].view(1,-1))
print("Shape of transformed waveform: {}".format(transformed.size()))
plt.figure()
plt.plot(transformed[0,:].numpy())
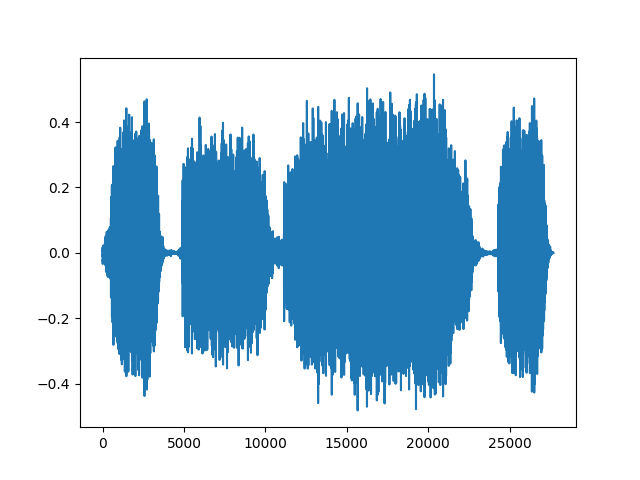
输出:
Shape of transformed waveform: torch.Size([1, 27686])
作为转换的另一个示例,我们可以基于 Mu-Law enen 对信号进行编码。 但为此,我们需要的信号介于 -1 和 1 之间。 由于这个张量只是一个常规的 PyTorch 张量,因此我们可以对其应用标准操作符。
# Let's check if the tensor is in the interval [-1,1]
print("Min of waveform: {}\nMax of waveform: {}\nMean of waveform: {}".format(waveform.min(), waveform.max(), waveform.mean()))
输出:
Min of waveform: -0.572845458984375
Max of waveform: 0.575958251953125
Mean of waveform: 9.293758921558037e-05
由于波形已经在 -1 和 1 之间,因此我们不需要将其规范化。
def normalize(tensor):
# Subtract the mean, and scale to the interval [-1,1]
tensor_minusmean = tensor - tensor.mean()
return tensor_minusmean/tensor_minusmean.abs().max()
# Let's normalize to the full interval [-1,1]
# waveform = normalize(waveform)
让我们应用编码波形。
transformed = torchaudio.transforms.MuLawEncoding()(waveform)
print("Shape of transformed waveform: {}".format(transformed.size()))
plt.figure()
plt.plot(transformed[0,:].numpy())
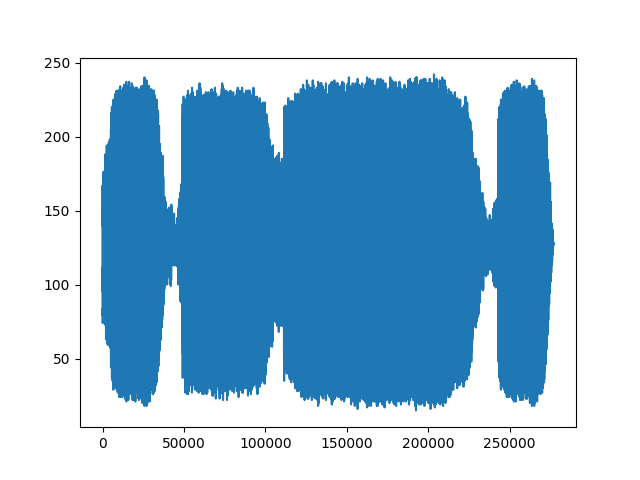
输出:
Shape of transformed waveform: torch.Size([2, 276858])
现在解码。
reconstructed = torchaudio.transforms.MuLawDecoding()(transformed)
print("Shape of recovered waveform: {}".format(reconstructed.size()))
plt.figure()
plt.plot(reconstructed[0,:].numpy())
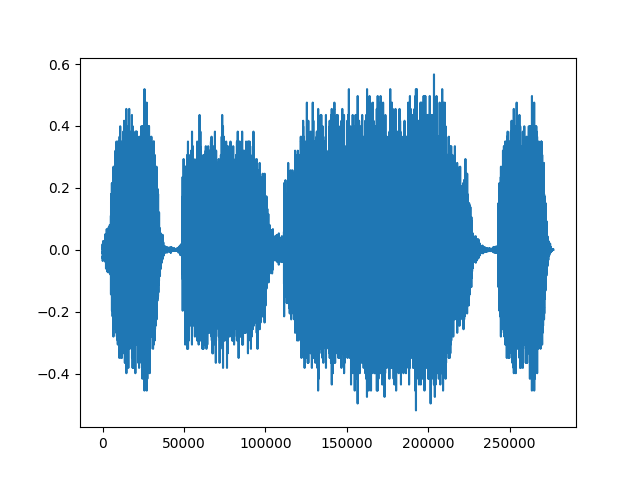
输出:
Shape of recovered waveform: torch.Size([2, 276858])
我们终于可以将原始波形与其重建版本进行比较。
# Compute median relative difference
err = ((waveform-reconstructed).abs() / waveform.abs()).median()
print("Median relative difference between original and MuLaw reconstucted signals: {:.2%}".format(err))
输出:
Median relative difference between original and MuLaw reconstucted signals: 1.28%
从 Kaldi 迁移到 torchaudio¶
用户可能熟悉 Kaldi,一个用于语音识别的工具包。 torchaudio 在torchaudio.kaldi_io中提供与它的兼容性。 它可以用以下函数读取 kaldi scp、ark 文件或流:
read_vec_int_ark
read_vec_flt_scp
read_vec_flt_arkfile/stream
read_mat_scp
read_mat_ark
torchaudio 提供与 Kaldi 兼容的spectrogram和fbank转换并支持GPU,请参阅此处了解更多信息。
n_fft = 400.0
frame_length = n_fft / sample_rate * 1000.0
frame_shift = frame_length / 2.0
params = {
"channel": 0,
"dither": 0.0,
"window_type": "hanning",
"frame_length": frame_length,
"frame_shift": frame_shift,
"remove_dc_offset": False,
"round_to_power_of_two": False,
"sample_frequency": sample_rate,
}
specgram = torchaudio.compliance.kaldi.spectrogram(waveform, **params)
print("Shape of spectrogram: {}".format(specgram.size()))
plt.figure()
plt.imshow(specgram.t().numpy(), cmap='gray')
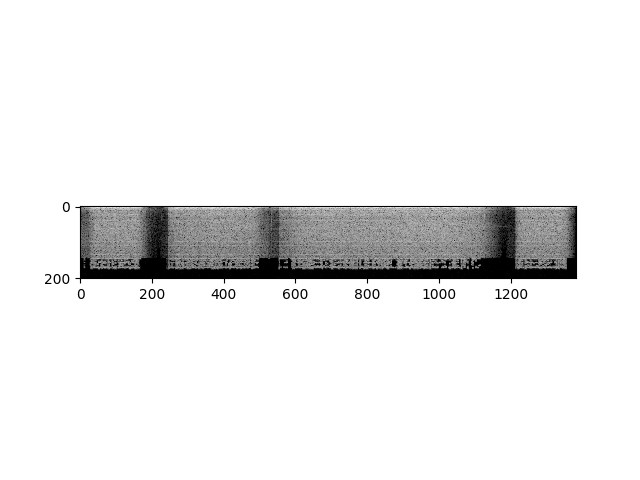
输出:
Shape of spectrogram: torch.Size([1383, 201])
我们还支持从波形计算 filterbank 特征,与 Kaldi 的实现一致。
fbank = torchaudio.compliance.kaldi.fbank(waveform, **params)
print("Shape of fbank: {}".format(fbank.size()))
plt.figure()
plt.imshow(fbank.t().numpy(), cmap='gray')
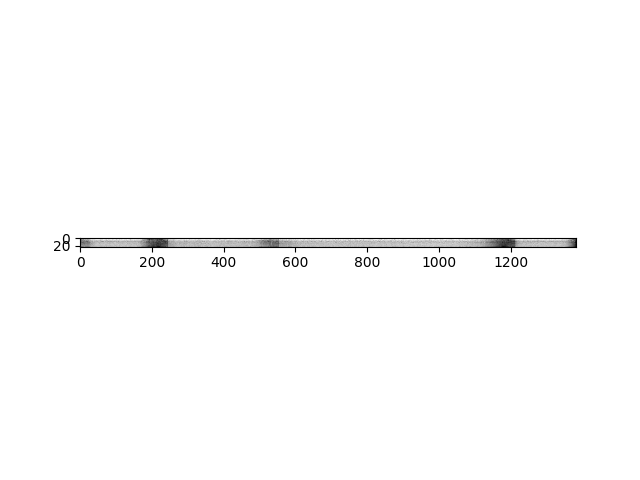
输出:
Shape of fbank: torch.Size([1383, 23])
结论|
我们使用一个原始音频信号或波形样本来说明如何使用 torchaudio 打开音频文件,以及如何预处理和转换这类波形。 由于 torchaudio 构建在 PyTorch 上,这些技术可用作更高级音频应用(如语音识别)的构建基块,同时利用 GPU。
脚本总运行时间: (0分3.096秒)