


注意
here下载完整的示例代码
对抗性示例生成|
作者: 内森·因卡
如果您正在阅读本文,希望您能了解一些机器学习模型的有效性。 研究不断推动 ML 模型更快、更准确、更高效。 然而,设计和训练模型中经常被忽视的一个方面是安全性和鲁棒性,尤其是在面对想要愚弄模型的对手时。
本教程将提高您对 ML 模型安全漏洞的认识,并深入了解对抗性机器学习的热门话题。 您可能会惊讶地发现,向图像添加难以察觉的扰动可能会导致模型性能发生巨大变化。 鉴于这是一个教程,我们将通过图像分类器上的示例来探讨该主题。 具体来说,我们将使用第一个和最流行的攻击方法之一,快速梯度符号攻击(FGSM),以愚弄MNIST分类器。
威胁模型|
对于上下文,有许多类别的对抗性攻击,每种攻击的目标和攻击者的知识假设都不同。 但是,一般来说,总体目标是向输入数据添加最少的扰动量,从而导致所需的错误分类。 攻击者的知识有几种假设,其中两种是:白盒和黑匣子。 白盒攻击假定攻击者完全了解模型并有权访问模型,包括体系结构、输入、输出和权重。 黑盒攻击假定攻击者只能访问模型的输入和输出,并且对基础体系结构或权重一无所知。 还有几种目标类型,包括错误分类和源/目标错误分类。 错误分类的目标意味着攻击者只希望输出分类是错误的,而不关心新分类是什么。 源/目标错误分类意味着攻击者希望更改最初属于特定源类的图像,以便将其归类为特定目标类。
在这种情况下,FGSM攻击是白盒攻击,目标是错误分类。 有了这个背景信息,我们现在可以详细讨论攻击。
快速渐变符号攻击|
迄今第一个和最流行的对抗性攻击之一被称为快速梯度符号攻击 (FGSM),由 Goodfellow 等人描述。 al.在解释和利用敌对的例子。 攻击非常强大,但直观。 它被设计成通过利用他们学习的方式,梯度来攻击神经网络。 这个想法很简单,而不是通过调整基于回传播梯度的权重来最小化损失,攻击调整输入数据,以根据相同的回传播梯度最大化损失。 换句话说,攻击使用输入数据的损耗 w.r.t 梯度,然后调整输入数据以最大化损失。
在插入代码之前,让我们看一下著名的FGSM熊猫示例,并提取一些符号。

从图中,[(mathbf_x_)是正确分类为"熊猫"的原始输入图像,[(y])是[(mathbf_x_)的地面真值标签],[(mathbf_theta_) 表示模型参数,而\(j([mathbf_ta],[mathbf_x])是使用的火车位。 攻击将梯度回传到输入数据以计算[(nabla__x] J([mathbf_theta]、[mathbf_x_x]、y))。 然后,它会按图中一小步([([([([乘以\x)]或[0.007])的方向调整输入数据(即[(符号(nabla__x_J([mathbf_theta]、[mathbf_x_x,y)))]),从而将损失最大化。 由此产生的扰动图像[(x'])然后被目标网络错误地归类为"长臂猿",当它显然仍然是"熊猫"时。
希望现在本教程的动机是明确的,所以让我们跳到实现。
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt
实施|
在本节中,我们将讨论本教程的输入参数,定义受攻击的模型,然后编写攻击代码并运行一些测试。
•输入
本教程只有三个输入,定义如下:
epsilons - 用于运行的子素值列表。 在列表中保留 0 非常重要,因为它表示原始测试集中的模型性能。 此外,从直觉上讲,我们期望的epsilon越大,扰动越明显,但就降低模型准确性而言,攻击效果越有效。 由于此处的数据范围为[(0,1]),因此任何 epsilon 值都不应超过 1。
pretrained_model - 预训练的MNIST模型,这是训练与pytorch/示例/mnist的路径。 为简单起见,请在此处下载预置模型。
use_cuda - 布尔标志,如果需要且可用,可使用 CUDA。 请注意,具有 CUDA 的 GPU 对本教程并不重要,因为 CPU 不会花费太多时间。
epsilons = [0, .05, .1, .15, .2, .25, .3]
pretrained_model = "data/lenet_mnist_model.pth"
use_cuda=True
攻击模型|
如前所述,被攻击的模型与pytorch/示例/mnist相同的 MNIST 模型相同。 您可以训练和保存您自己的 MNIST 模型,也可以下载和使用提供的模型。 此处的Net定义和测试数据加载器是从 MNIST 示例复制的。 本节的目的是定义模型和数据加载器,然后初始化模型并加载预训练的权重。
# LeNet Model definition
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
# MNIST Test dataset and dataloader declaration
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, download=True, transform=transforms.Compose([
transforms.ToTensor(),
])),
batch_size=1, shuffle=True)
# Define what device we are using
print("CUDA Available: ",torch.cuda.is_available())
device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu")
# Initialize the network
model = Net().to(device)
# Load the pretrained model
model.load_state_dict(torch.load(pretrained_model, map_location='cpu'))
# Set the model in evaluation mode. In this case this is for the Dropout layers
model.eval()
输出:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../data/MNIST/raw/train-images-idx3-ubyte.gz
Extracting ../data/MNIST/raw/train-images-idx3-ubyte.gz to ../data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../data/MNIST/raw/train-labels-idx1-ubyte.gz
Extracting ../data/MNIST/raw/train-labels-idx1-ubyte.gz to ../data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../data/MNIST/raw/t10k-images-idx3-ubyte.gz
Extracting ../data/MNIST/raw/t10k-images-idx3-ubyte.gz to ../data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz
Extracting ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw
Processing...
Done!
CUDA Available: False
FGSM 攻击|
现在,我们可以定义通过干扰原始输入来创建对抗性示例的函数。 fgsm_attack函数采用三个输入,图像是原始干净的图像([(x]),epsilon是像素级扰动量(*([(epsilon])),data_grad是损失的梯度 w.r.t 输入图像 ( _(nabla__x_ J(_mathbf_theta_, _mathbf_x_) 然后,该函数将创建扰动的图像,如
最后,为了保持数据的原始范围,扰动图像被剪切到范围 [({0,1})。
# FGSM attack code
def fgsm_attack(image, epsilon, data_grad):
# Collect the element-wise sign of the data gradient
sign_data_grad = data_grad.sign()
# Create the perturbed image by adjusting each pixel of the input image
perturbed_image = 图像 + epsilon*sign_data_grad
# Adding clipping to maintain [0,1] range
perturbed_image = torch.clamp(perturbed_image, 0, 1)
# Return the perturbed image
return perturbed_image
测试功能|
最后,本教程的中心结果来自test函数。 每次调用此测试函数都会在 MNIST 测试集上执行完整的测试步骤,并报告最终精度。 但是,请注意,此函数也采用一个epsilon输入。 这是因为test函数报告受到来自具有实力[([epsilon])的对手攻击的模型的准确性。 更具体地说,对于测试集中的每个示例,函数计算输入数据的损耗 w.r.t 的梯度(*(数据 _grad)),创建具有fgsm_attack ([(扰动]_data))的扰动图像,然后检查扰动示例是否具有对抗性。 除了测试模型的准确性外,该函数还保存并返回一些成功的对抗性示例,以便以后可视化。
def test( model, device, test_loader, epsilon ):
# Accuracy counter
correct = 0
adv_examples = []
# Loop over all examples in test set
for data, target in test_loader:
# Send the data and label to the device
data, target = data.to(device), target.to(device)
# Set requires_grad attribute of tensor. Important for Attack
data.requires_grad = True
# Forward pass the data through the model
output = model(data)
init_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
# If the initial prediction is wrong, dont bother attacking, just move on
if init_pred.item() != target.item():
continue
# Calculate the loss
loss = F.nll_loss(output, target)
# Zero all existing gradients
model.zero_grad()
# Calculate gradients of model in backward pass
loss.backward()
# Collect datagrad
data_grad = data.grad.data
# Call FGSM Attack
perturbed_data = fgsm_attack(data, epsilon, data_grad)
# Re-classify the perturbed image
output = model(perturbed_data)
# Check for success
final_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability
if final_pred.item() == target.item():
correct += 1
# Special case for saving 0 epsilon examples
if (epsilon == 0) and (len(adv_examples) < 5):
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )
else:
# Save some adv examples for visualization later
if len(adv_examples) < 5:
adv_ex = perturbed_data.squeeze().detach().cpu().numpy()
adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )
# Calculate final accuracy for this epsilon
final_acc = correct/float(len(test_loader))
print("Epsilon: {}\tTest Accuracy = {} / {} = {}".format(epsilon, correct, len(test_loader), final_acc))
# Return the accuracy and an adversarial example
return final_acc, adv_examples
运行攻击|
实现的最后一部分是实际运行攻击。 在这里,我们运行一个完整的测试步骤,每个epsilons输入中的每个epsilon值。 对于每个 epsilon,我们还保存最终精度和一些成功的对抗性示例,以便在接下来的章节中绘制。 请注意打印精度如何随着环子值的增加而降低。 此外,请注意[(_epsilon{0})案例表示原始测试精度,没有攻击。
accuracies = []
examples = []
# Run test for each epsilon
for eps in epsilons:
acc, ex = test(model, device, test_loader, eps)
accuracies.append(acc)
examples.append(ex)
输出:
Epsilon: 0 Test Accuracy = 9810 / 10000 = 0.981
Epsilon: 0.05 Test Accuracy = 9426 / 10000 = 0.9426
Epsilon: 0.1 Test Accuracy = 8510 / 10000 = 0.851
Epsilon: 0.15 Test Accuracy = 6826 / 10000 = 0.6826
Epsilon: 0.2 Test Accuracy = 4301 / 10000 = 0.4301
Epsilon: 0.25 Test Accuracy = 2082 / 10000 = 0.2082
Epsilon: 0.3 Test Accuracy = 869 / 10000 = 0.0869
结果|
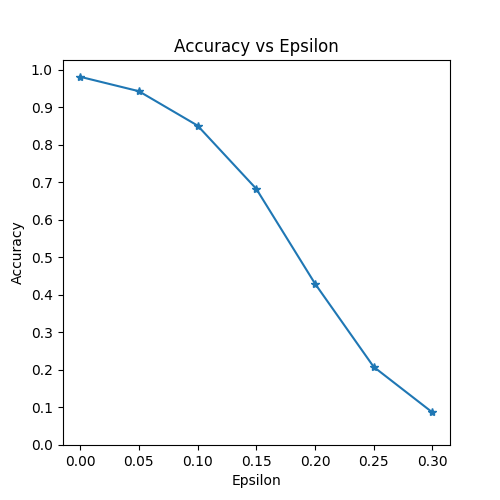
精度 vs Epsilon|
第一个结果是精度与epsilon图。 正如前面提到的,随着epsilon的增加,我们预计测试精度会下降。 这是因为较大的环子意味着我们在将损失最大化的方向上迈出了更大的一步。 请注意,曲线中的趋势不是线性的,即使环子值是线性间隔的。 例如,[([epsilon]0.05°)处的精度仅比[([epsilon=0])低约 4%,但[([epsilon]0.2])的精度比[(_epsilon=0.15])低 25%。 此外,请注意模型的准确性达到 10 类分类器的随机精度 ,该分类器介于[(_epsilon=0.25])和[(_epsilon=0.3])之间。
plt.figure(figsize=(5,5))
plt.plot(epsilons, accuracies, "*-")
plt.yticks(np.arange(0, 1.1, step=0.1))
plt.xticks(np.arange(0, .35, step=0.05))
plt.title("Accuracy vs Epsilon")
plt.xlabel("Epsilon")
plt.ylabel("Accuracy")
plt.show()
对抗示例示例|
还记得没有免费午餐的想法吗? 在这种情况下,随着环子增加测试精度降低,但扰动变得更容易察觉。 实际上,攻击者必须考虑精度偏离和感知之间的权衡。 在这里,我们展示了一些成功的对抗性示例,每个 epsilon 值。 绘图的每一行都显示不同的 epsilon 值。 第一行是[(_epsilon_0})示例,表示原始"干净"图像,没有扰动。 每个图像的标题显示"原始分类 -= 对抗分类"。请注意,扰动在[([epsilon]0.15°)处开始变得明显,在[([epsilon]0.3])中非常明显。 然而,在所有情况下,尽管增加了噪音,人类仍然能够识别正确的类。
# Plot several examples of adversarial samples at each epsilon
cnt = 0
plt.figure(figsize=(8,10))
for i in range(len(epsilons)):
for j in range(len(examples[i])):
cnt += 1
plt.subplot(len(epsilons),len(examples[0]),cnt)
plt.xticks([], [])
plt.yticks([], [])
if j == 0:
plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14)
orig,adv,ex = examples[i][j]
plt.title("{} -> {}".format(orig, adv))
plt.imshow(ex, cmap="gray")
plt.tight_layout()
plt.show()

下一步要去哪里?*
希望本教程能够深入了解对抗性机器学习的主题。 从这里可以走很多潜在的方向。 此攻击代表了对抗性攻击研究的开始,因为随后有许多关于如何攻击和防御 ML 模型的想法。 事实上,在2017NIPS,出现了对抗性攻防竞争,本文介绍了竞争中的许多方法:对抗攻击和防御竞争。 防御工作还产生了使机器学习模型在一般方面更加强大的想法,这既具有自然扰动,也具有对抗性。
另一个方向是不同领域的对抗性攻击和防御。 对抗性研究并不限于图像领域,看看这次对语音到文本模型的攻击。 但是,了解对抗性机器学习的最佳方式可能是弄脏双手。 尝试实施与 2017 NIPS 比赛不同的攻击,并了解它与 FGSM 有何不同。 然后,尝试保护模型免受自己的攻击。
脚本总运行时间: (28分46.855秒)