2. 获得文本语料和词汇资源
在自然语言处理的实际项目中,通常要使用大量的语言数据或者语料库。本章的目的是要回答下列问题:
- 什么是有用的文本语料和词汇资源,我们如何使用Python获取它们?
- 哪些Python结构最适合这项工作?
- 编写Python代码时我们如何避免重复的工作?
本章继续通过语言处理任务的例子展示编程概念。在系统的探索每一个Python 结构之前请耐心等待。如果你看到一个例子中含有一些不熟悉的东西,请不要担心。只需去尝试它,看看它做些什么——如果你很勇敢——通过使用不同的文本或词替换代码的某些部分来进行修改。这样,你会将任务与编程习惯用法关联起来,并在后续的学习中了解怎么会这样和为什么是这样。
1 获取文本语料库
正如刚才提到的,一个文本语料库是一大段文本。许多语料库的设计都要考虑一个或多个文体间谨慎的平衡。我们曾在第1.章研究过一些小的文本集合,例如美国总统就职演说。这种特殊的语料库实际上包含了几十个单独的文本——每个人一个演讲——但为了处理方便,我们把它们头尾连接起来当做一个文本对待。第1.章中也使用变量预先定义好了一些文本,我们通过输入from nltk.book import *来访问它们。然而,因为我们希望能够处理其他文本,本节中将探讨各种文本语料库。我们将看到如何选择单个文本,以及如何处理它们。
1.1 古腾堡语料库
NLTK 包含古腾堡项目(Project Gutenberg)电子文本档案的经过挑选的一小部分文本,该项目大约有25,000本免费电子图书,放在http://www.gutenberg.org/上。我们先要用Python 解释器加载NLTK 包,然后尝试nltk.corpus.gutenberg.fileids(),下面是这个语料库中的文件标识符:
|
让我们挑选这些文本的第一个——简·奥斯丁的《爱玛》——并给它一个简短的名称emma,然后找出它包含多少个词:
|
注意
在第1章中,我们演示了如何使用text1.concordance()命令对text1这样的文本进行索引。然而,这是假设你正在使用由from nltk.book import *导入的9 个文本之一。现在你开始研究nltk.corpus中的数据,像前面的例子一样,你必须采用以下语句对来处理索引和第1章中的其它任务:
|
在我们定义emma, 时,我们调用了NLTK 中的corpus包中的gutenberg对象的words()函数。但因为总是要输入这么长的名字很繁琐,Python 提供了另一个版本的import语句,示例如下:
|
让我们写一个简短的程序,通过循环遍历前面列出的gutenberg文件标识符列表相应的fileid,然后计算统计每个文本。为了使输出看起来紧凑,我们将使用round()舍入每个数字到最近似的整数。
|
这个程序显示每个文本的三个统计量:平均词长、平均句子长度和本文中每个词出现的平均次数(我们的词汇多样性得分)。请看,平均词长似乎是英语的一个一般属性,因为它的值总是4。(事实上,平均词长是3而不是4,因为num_chars变量计数了空白字符。)相比之下,平均句子长度和词汇多样性看上去是作者个人的特点。
前面的例子也表明我们怎样才能获取“原始”文本![[1]](./static/callout1.gif) 而不用把它分割成词符。raw()函数给我们没有进行过任何语言学处理的文件的内容。因此,例如len(gutenberg.raw('blake-poems.txt'))告诉我们文本中出现的字符个数,包括词之间的空格。sents()函数把文本划分成句子,其中每一个句子是一个单词列表:
而不用把它分割成词符。raw()函数给我们没有进行过任何语言学处理的文件的内容。因此,例如len(gutenberg.raw('blake-poems.txt'))告诉我们文本中出现的字符个数,包括词之间的空格。sents()函数把文本划分成句子,其中每一个句子是一个单词列表:
|
注意
除了words(), raw()和sents()之外,大多数NLTK语料库阅读器还包括多种访问方法。一些语料库提供更加丰富的语言学内容,例如:词性标注,对话标记,语法树等;在后面的章节中,我们将看到这些。
1.2 网络和聊天文本
虽然古腾堡项目包含成千上万的书籍,它代表既定的文学。考虑较不正式的语言也是很重要的。NLTK的网络文本小集合的内容包括Firefox交流论坛,在纽约无意听到的对话, 加勒比海盗的电影剧本,个人广告和葡萄酒的评论:
|
还有一个即时消息聊天会话语料库,最初由美国海军研究生院为研究自动检测互联网幼童虐待癖而收集的。语料库包含超过10,000 张帖子,以“UserNNN”形式的通用名替换掉用户名,手工编辑消除任何其他身份信息,制作而成。语料库被分成15 个文件,每个文件包含几百个按特定日期和特定年龄的聊天室(青少年、20 岁、30 岁、40 岁、再加上一个通用的成年人聊天室)收集的帖子。文件名中包含日期、聊天室和帖子数量,例如10-19-20s_706posts.xml包含2006 年10 月19 日从20 多岁聊天室收集的706 个帖子。
|
1.3 布朗语料库
布朗语料库是第一个百万词级的英语电子语料库的,由布朗大学于1961 年创建。这个语料库包含500 个不同来源的文本,按照文体分类,如:新闻、社论等。表1.1给出了各个文体的例子(完整列表,请参阅http://icame.uib.no/brown/bcm-los.html)。
表 1.1:
布朗语料库每一部分的示例文档
| ID | 文件 | 文体 | 描述 |
|---|---|---|---|
| A16 | ca16 | 新闻 | Chicago Tribune: Society Reportage |
| B02 | cb02 | 社论 | Christian Science Monitor: Editorials |
| C17 | cc17 | 评论 | Time Magazine: Reviews |
| D12 | cd12 | 宗教 | Underwood: Probing the Ethics of Realtors |
| E36 | ce36 | 爱好 | Norling: Renting a Car in Europe |
| F25 | cf25 | 传说 | Boroff: Jewish Teenage Culture |
| G22 | cg22 | 纯文学 | Reiner: Coping with Runaway Technology |
| H15 | ch15 | 政府 | US Office of Civil and Defence Mobilization: The Family Fallout Shelter |
| J17 | cj19 | 博览 | Mosteller: Probability with Statistical Applications |
| K04 | ck04 | 小说 | W.E.B. Du Bois: Worlds of Color |
| L13 | cl13 | 悬疑 | Hitchens: Footsteps in the Night |
| M01 | cm01 | 科幻 | Heinlein: Stranger in a Strange Land |
| N14 | cn15 | 探险 | Field: Rattlesnake Ridge |
| P12 | cp12 | 浪漫 | Callaghan: A Passion in Rome |
| R06 | cr06 | 幽默 | Thurber: The Future, If Any, of Comedy |
我们可以将语料库作为单词列表或者句子列表来访问(每个句子本身也是一个单词列表)。我们可以指定特定的类别或文件阅读:
|
布朗语料库是一个研究文体之间的系统性差异——一种叫做文体学的语言学研究——很方便的资源。让我们来比较不同文体中的情态动词的用法。第一步是产生特定文体的计数。记住做下面的实验之前要import nltk:
|
注意
我们需要设置end = ' '以让print函数将其输出放在单独的一行。
注意
轮到你来: 选择布朗语料库的不同部分,修改前面的例子,计数包含wh的词,如:what, when, where, who和 why。
下面,我们来统计每一个感兴趣的文体。我们使用NLTK 提供的带条件的频率分布函数。在第2节中会系统的把下面的代码一行行拆开来讲解。现在,你可以忽略细节,只看输出。
|
请看,新闻文体中最常见的情态动词是will,而言情文体中最常见的情态动词是could。你能预言这些吗?这种可以区分文体的词计数方法将在chap-data-intensive中再次谈及。
1.4 路透社语料库
路透社语料库包含10,788 个新闻文档,共计130 万字。这些文档分成90 个主题,按照“训练”和“测试”分为两组;因此,fileid 为'test/14826'的文档属于测试组。这样分割是为了训练和测试算法的,这种算法自动检测文档的主题,我们将在chap-data-intensive中看到。
|
与布朗语料库不同,路透社语料库的类别是有互相重叠的,只是因为新闻报道往往涉及多个主题。我们可以查找由一个或多个文档涵盖的主题,也可以查找包含在一个或多个类别中的文档。为方便起见,语料库方法既接受单个的fileid 也接受fileids 列表作为参数。
|
类似的,我们可以以文档或类别为单位查找我们想要的词或句子。这些文本中最开始的几个词是标题,按照惯例以大写字母存储。
|
1.5 就职演说语料库
在第1章,我们看到了就职演说语料库,但是把它当作一个单独的文本对待。图fig-inaugural中使用的“词偏移”就像是一个坐标轴;它是语料库中词的索引数,从第一个演讲的第一个词开始算起。然而,语料库实际上是55个文本的集合,每个文本都是一个总统的演说。这个集合的一个有趣特性是它的时间维度:
|
请注意,每个文本的年代都出现在它的文件名中。要从文件名中获得年代,我们使用fileid[:4]提取前四个字符。
让我们来看看词汇America和citizen随时间推移的使用情况。下面的代码使用w.lower() 将就职演说语料库中的词汇转换成小写,然后用startswith() 检查它们是否以“目标”词汇america或citizen开始。因此,它会计算如American's和Citizens等词。我们将在第2节学习条件频率分布,现在只考虑输出,如图1.1所示。
|
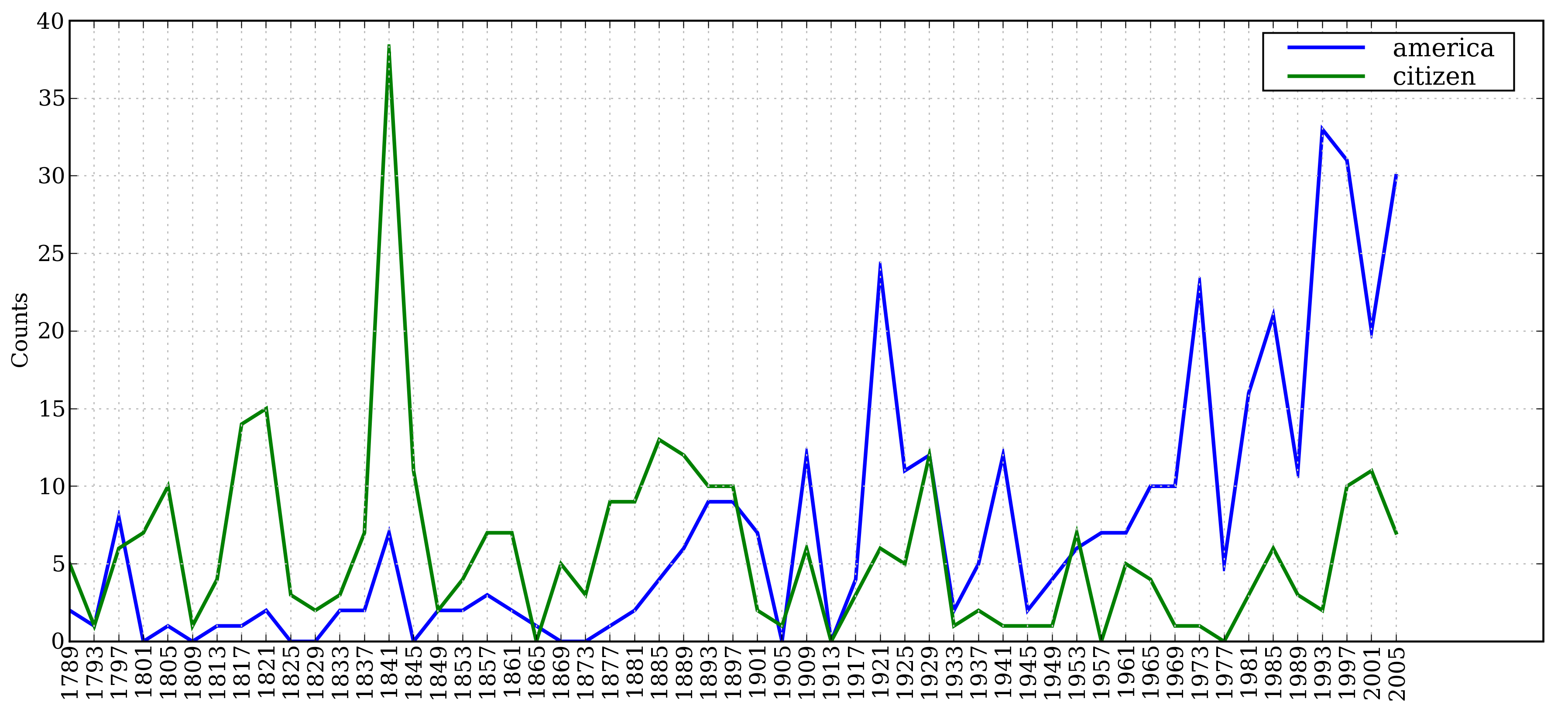
图 1.1:条件频率分布图:计数就职演说语料库中所有以america 或citizen开始的词;每个演讲单独计数;这样就能观察出随时间变化用法上的演变趋势;计数没有与文档长度进行归一化处理。
1.6 标注文本语料库
许多文本语料库都包含语言学标注,有词性标注、命名实体、句法结构、语义角色等。NLTK 中提供了很方便的方式来访问这些语料库中的几个,还有一个包含语料库和语料样本的数据包,用于教学和科研的话可以免费下载。表1.2列出了其中一些语料库。有关下载信息请参阅http://nltk.org/data。关于如何访问NLTK 语料库的其它例子,请在http://nltk.org/howto查阅语料库的HOWTO。
表 1.2:
NLTK中的一些语料库和语料库样本:关于下载和使用它们,请参阅NLTK网站的信息。
| 语料库 | 编者 | 内容 |
|---|---|---|
| Brown Corpus | Francis, Kucera | 15 genres, 1.15M words, tagged, categorized |
| CESS Treebanks | CLiC-UB | 1M words, tagged and parsed (Catalan, Spanish) |
| Chat-80 Data Files | Pereira & Warren | World Geographic Database |
| CMU Pronouncing Dictionary | CMU | 127k entries |
| CoNLL 2000 Chunking Data | CoNLL | 270k words, tagged and chunked |
| CoNLL 2002 Named Entity | CoNLL | 700k words, pos- and named-entity-tagged (Dutch, Spanish) |
| CoNLL 2007 Dependency Treebanks (sel) | CoNLL | 150k words, dependency parsed (Basque, Catalan) |
| Dependency Treebank | Narad | Dependency parsed version of Penn Treebank sample |
| FrameNet | Fillmore, Baker et al | 10k word senses, 170k manually annotated sentences |
| Floresta Treebank | Diana Santos et al | 9k sentences, tagged and parsed (Portuguese) |
| Gazetteer Lists | Various | Lists of cities and countries |
| Genesis Corpus | Misc web sources | 6 texts, 200k words, 6 languages |
| Gutenberg (selections) | Hart, Newby, et al | 18 texts, 2M words |
| Inaugural Address Corpus | CSpan | US Presidential Inaugural Addresses (1789-present) |
| Indian POS-Tagged Corpus | Kumaran et al | 60k words, tagged (Bangla, Hindi, Marathi, Telugu) |
| MacMorpho Corpus | NILC, USP, Brazil | 1M words, tagged (Brazilian Portuguese) |
| Movie Reviews | Pang, Lee | 2k movie reviews with sentiment polarity classification |
| Names Corpus | Kantrowitz, Ross | 8k male and female names |
| NIST 1999 Info Extr (selections) | Garofolo | 63k words, newswire and named-entity SGML markup |
| Nombank | Meyers | 115k propositions, 1400 noun frames |
| NPS Chat Corpus | Forsyth, Martell | 10k IM chat posts, POS-tagged and dialogue-act tagged |
| Open Multilingual WordNet | Bond et al | 15 languages, aligned to English WordNet |
| PP Attachment Corpus | Ratnaparkhi | 28k prepositional phrases, tagged as noun or verb modifiers |
| Proposition Bank | Palmer | 113k propositions, 3300 verb frames |
| Question Classification | Li, Roth | 6k questions, categorized |
| Reuters Corpus | Reuters | 1.3M words, 10k news documents, categorized |
| Roget's Thesaurus | Project Gutenberg | 200k words, formatted text |
| RTE Textual Entailment | Dagan et al | 8k sentence pairs, categorized |
| SEMCOR | Rus, Mihalcea | 880k words, part-of-speech and sense tagged |
| Senseval 2 Corpus | Pedersen | 600k words, part-of-speech and sense tagged |
| SentiWordNet | Esuli, Sebastiani | sentiment scores for 145k WordNet synonym sets |
| Shakespeare texts (selections) | Bosak | 8 books in XML format |
| State of the Union Corpus | CSPAN | 485k words, formatted text |
| Stopwords Corpus | Porter et al | 2,400 stopwords for 11 languages |
| Swadesh Corpus | Wiktionary | comparative wordlists in 24 languages |
| Switchboard Corpus (selections) | LDC | 36 phonecalls, transcribed, parsed |
| Univ Decl of Human Rights | United Nations | 480k words, 300+ languages |
| Penn Treebank (selections) | LDC | 40k words, tagged and parsed |
| TIMIT Corpus (selections) | NIST/LDC | audio files and transcripts for 16 speakers |
| VerbNet 2.1 | Palmer et al | 5k verbs, hierarchically organized, linked to WordNet |
| Wordlist Corpus | OpenOffice.org et al | 960k words and 20k affixes for 8 languages |
| WordNet 3.0 (English) | Miller, Fellbaum | 145k synonym sets |
1.7 其他语言的语料库
NLTK 包含多国语言语料库,尽管某些情况下你在使用这些语料库之前需要学习如何在Python 中处理字符编码(见3.3节)。
|
这些语料库的最后,udhr,是超过300种语言的世界人权宣言。这个语料库的fileids包括有关文件所使用的字符编码,如UTF8或者Latin1。让我们用条件频率分布来研究udhr语料库中不同语言版本中的字长差异。图1.2 中所示的输出(自己运行程序可以看到一个彩色图)。注意,True和False是Python 内置的布尔值。
|
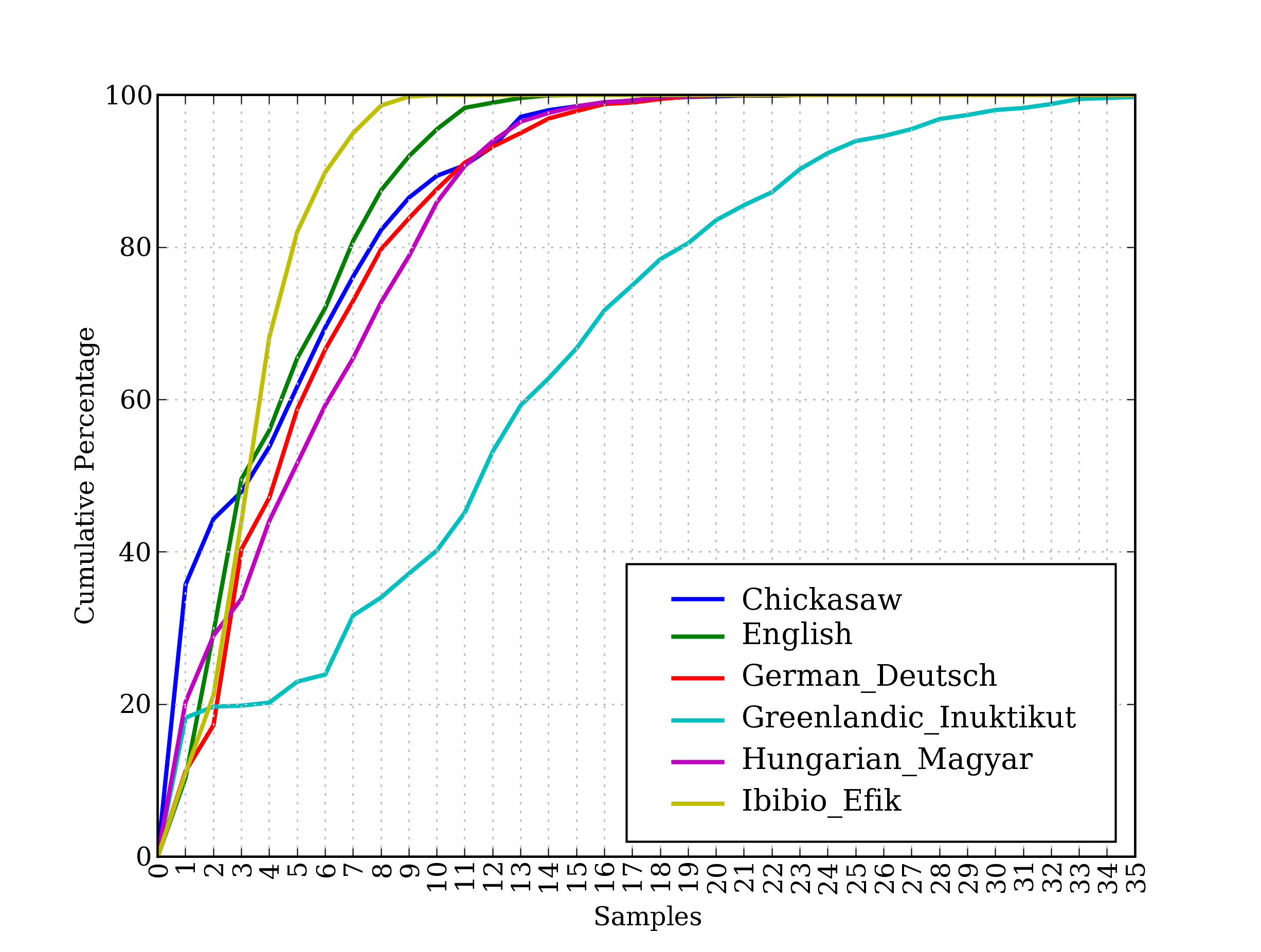
图 1.2:累积字长分布:世界人权宣言的6个翻译版本;此图显示,5个或5个以下字母组成的词在Ibibio语言的文本中占约80%,在德语文本中占60%,在Inuktitut文本中占25%。
注意
轮到你来:在udhr.fileids()中选择一种感兴趣的语言,定义一个变量raw_text = udhr.raw(Language-Latin1)。使用nltk.FreqDist(raw_text).plot()画出此文本的字母频率分布图。
不幸的是,许多语言没有大量的语料库。通常是政府或工业对发展语言资源的支持不够,个人的努力是零碎的,难以发现或重用。有些语言没有既定的书写系统,或濒临灭绝。(见第7节有关如何寻找语言资源的建议。)
1.8 文本语料库的结构
到目前为止,我们已经看到了大量的语料库结构;1.3总结了它们。最简单的一种没有任何结构,仅仅是一个文本集合。通常,文本会按照其可能对应的文体、来源、作者、语言等分类。有时,这些类别会重叠,尤其是在按主题分类的情况下,因为一个文本可能与多个主题相关。偶尔的,文本集有一个时间结构,新闻集合是最常见的例子。
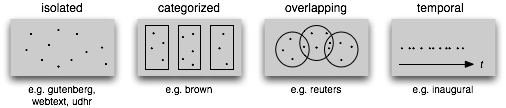
图 1.3:文本语料库的常见结构:最简单的一种语料库是一些孤立的没有什么特别的组织的文本集合;一些语料库按如文体(布朗语料库)等分类组织结构;一些分类会重叠,如主题类别(路透社语料库);另外一些语料库可以表示随时间变化语言用法的改变(就职演说语料库)。
表 1.3:
NLTK 中定义的基本语料库函数:使用help(nltk.corpus.reader)可以找到更多的文档,也可以阅读http://nltk.org/howto上的在线语料库的HOWTO。
| 示例 | 描述 |
|---|---|
| fileids() | 语料库中的文件 |
| fileids([categories]) | 这些分类对应的语料库中的文件 |
| categories() | 语料库中的分类 |
| categories([fileids]) | 这些文件对应的语料库中的分类 |
| raw() | 语料库的原始内容 |
| raw(fileids=[f1,f2,f3]) | 指定文件的原始内容 |
| raw(categories=[c1,c2]) | 指定分类的原始内容 |
| words() | 整个语料库中的词汇 |
| words(fileids=[f1,f2,f3]) | 指定文件中的词汇 |
| words(categories=[c1,c2]) | 指定分类中的词汇 |
| sents() | 整个语料库中的句子 |
| sents(fileids=[f1,f2,f3]) | 指定文件中的句子 |
| sents(categories=[c1,c2]) | 指定分类中的句子 |
| abspath(fileid) | 指定文件在磁盘上的位置 |
| encoding(fileid) | 文件的编码(如果知道的话) |
| open(fileid) | 打开指定语料库文件的文件流 |
| root | 本地安装的语料库根目录的路径 |
| readme() | 语料库的README 文件的内容 |
NLTK 的语料库阅读器支持高效的访问各种语料库,且可用于新的语料库。1.3列出的是语料库阅读器提供的功能。下面我们举例说明一些语料库访问方法之间的区别︰
|
1.9 加载你自己的语料库
如果你有自己收集的文本文件,并且想使用前面讨论的方法访问它们,你可以很容易地在NLTK 中的PlaintextCorpusReader帮助下加载它们。检查你的文件在文件系统中的位置;在下面的例子中,我们假定你的文件在/usr/share/dict目录下。不管是什么位置,将变量corpus_root 的值设置为这个目录。PlaintextCorpusReader初始化函数![[2]](./static/callout2.gif) 的第二个参数可以是一个如['a.txt', 'test/b.txt']这样的fileids列表,或者一个匹配所有fileids 的模式,如'[abc]/.*\.txt'(关于正则表达式的信息见3.4节)。
的第二个参数可以是一个如['a.txt', 'test/b.txt']这样的fileids列表,或者一个匹配所有fileids 的模式,如'[abc]/.*\.txt'(关于正则表达式的信息见3.4节)。
|
举另一个例子,假设你在本地硬盘上有自己的宾州树库(第3 版)的拷贝,放在C:\corpora。我们可以使用BracketParseCorpusReader访问这些语料。我们指定corpus_root为存放语料库中解析过的《华尔街日报》部分的位置,并指定file_pattern与它的子文件夹中包含的文件匹配(用前斜杠)。
|
2 条件频率分布
我们在第3节介绍了频率分布。我们看到给定某个词汇或其他元素的列表mylist,FreqDist(mylist)会计算列表中每个元素项目出现的次数。在这里,我们将推广这一想法。
当语料文本被分为几类,如文体、主题、作者等时,我们可以计算每个类别独立的频率分布。这将允许我们研究类别之间的系统性差异。在上一节中,我们是用NLTK 的ConditionalFreqDist数据类型实现的。条件频率分布是频率分布的集合,每个频率分布有一个不同的“条件”。这个条件通常是文本的类别。2.1描绘了一个带两个条件的条件频率分布的片段,一个是新闻文本,一个是言情文本。
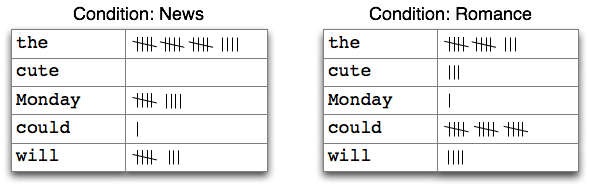
图 2.1:计数文本集合中单词出现次数(条件频率分布)
2.1 条件和事件
频率分布计算观察到的事件,如文本中出现的词汇。条件频率分布需要给每个事件关联一个条件。所以不是处理一个单词词序列,我们必须处理的是一个配对序列:
|
每个配对的形式是:(条件, 事件)。如果我们按文体处理整个布朗语料库,将有15 个条件(每个文体一个条件)和1,161,192 个事件(每一个词一个事件)。
2.2 按文体计数词汇
在1中,我们看到一个条件频率分布,其中条件为布朗语料库的每一节,并对每节计数词汇。FreqDist()以一个简单的列表作为输入,ConditionalFreqDist() 以一个配对列表作为输入。
|
让我们拆开来看,只看两个文体,新闻和言情。对于每个文体,我们遍历文体中的每个词![[3]](./static/callout3.gif) ,以产生文体与词的配对 :
,以产生文体与词的配对 :
|
因此,在下面的代码中我们可以看到,列表genre_word的前几个配对将是 ('news', word) 的形式,而最后几个配对将是 ('romance', word) 的形式。
|
现在,我们可以使用此配对列表创建一个ConditionalFreqDist,并将它保存在一个变量cfd中。像往常一样,我们可以输入变量的名称来检查它,并确认它有两个条件:
|
让我们访问这两个条件,它们每一个都只是一个频率分布:
|
2.3 绘制分布图和分布表
除了组合两个或两个以上的频率分布和更容易初始化之外,ConditionalFreqDist还为制表和绘图提供了一些有用的方法。
1.1是基于下面的代码产生的一个条件频率分布绘制的。条件是词america或citizen,被绘图的计数是在特定演讲中出现的词的次数。它利用了每个演讲的文件名的前4 个字符包含年代的事实——例如1865-Lincoln.txt 。这段代码为文件1865-Lincoln.txt中每个小写形式以america开头的词——如Americans——产生一个配对('america', '1865')。
|
图1.2也是基于下面的代码产生的一个条件频率分布绘制的。这次的条件是语言的名称,图中的计数来源于词长。它利用了每一种语言的文件名是语言名称后面跟'-Latin1'(字符编码)的事实。
|
在plot()和tabulate()方法中,我们可以使用conditions=来选择指定哪些条件显示。如果我们忽略它,所有条件都会显示。同样,我们可以使用samples=parameter 来限制要显示的样本。这使得载入大量数据到一个条件频率分布,然后通过选定条件和样品,绘图或制表的探索成为可能。这也使我们能全面控制条件和样本的显示顺序。例如:我们可以为两种语言和长度少于10 个字符的词汇绘制累计频率数据表,如下所示。我们解释一下上排最后一个单元格中数值的含义是英文文本中9 个或少于9 个字符长的词有1,638 个。
|
注意
轮到你来: 处理布朗语料库的新闻和言情文体,找出一周中最有新闻价值并且是最浪漫的日子。定义一个变量days,包含星期的列表,如['Monday', ...]。然后使用cfd.tabulate(samples=days)为这些词的计数制表。接下来用plot替代tabulate尝试同样的事情。你可以在额外的参数samples=['Monday', ...]的帮助下控制星期输出的顺序。
你可能已经注意到:我们已经在使用的条件频率分布看上去像列表推导,但是不带方括号。通常,我们使用列表推导作为一个函数的参数,如set([w.lower() for w in t]),忽略掉方括号而只写set(w.lower() for w in t)是允许的。(更多的讲解请参见4.2节“生成器表达式”的讨论。)
2.4 使用双连词生成随机文本
我们可以使用条件频率分布创建一个双连词表(词对)。(我们在3中介绍过。)bigrams()函数接受一个单词列表,并建立一个连续的词对列表。记住,为了能看到结果而不是神秘的"生成器对象",我们需要使用list()函数︰
|
在2.2中,我们把每个词作为一个条件,对每个词我们有效的创建它的后续词的频率分布。函数generate_model()包含一个简单的循环来生成文本。当我们调用这个函数时,我们选择一个词(如'living')作为我们的初始内容,然后进入循环,我们输入变量word的当前值,重新设置word为上下文中最可能的词符(使用max());下一次进入循环,我们使用那个词作为新的初始内容。正如你通过检查输出可以看到的,这种简单的文本生成方法往往会在循环中卡住;另一种方法是从可用的词汇中随机选择下一个词。
| ||
| ||
例 2.2 (code_random_text.py):图 2.2:产生随机文本:此程序获得《创世记》文本中所有的双连词,然后构造一个条件频率分布来记录哪些词汇最有可能跟在给定词的后面;例如living后面最可能的词是creature;generate_model()函数使用这些数据和种子词随机产生文本。 |
条件频率分布是一个对许多NLP 任务都有用的数据结构。2.1总结了它们常用的方法。
表 2.1:
NLTK 中的条件频率分布:定义、访问和可视化一个计数的条件频率分布的常用方法和习惯用法。
| 示例 | 描述 |
|---|---|
| cfdist = ConditionalFreqDist(pairs) | 从配对列表中创建条件频率分布 |
| cfdist.conditions() | 条件 |
| cfdist[condition] | 此条件下的频率分布 |
| cfdist[condition][sample] | 此条件下给定样本的频率 |
| cfdist.tabulate() | 为条件频率分布制表 |
| cfdist.tabulate(samples, conditions) | 指定样本和条件限制下制表 |
| cfdist.plot() | 为条件频率分布绘图 |
| cfdist.plot(samples, conditions) | 指定样本和条件限制下绘图 |
| cfdist1 < cfdist2 | 测试样本在cfdist1中出现次数是否小于在cfdist2中出现次数 |
3 更多关于Python:代码重用
到现在,你可能已经在Python 交互式解释器中输入和重新输入了大量的代码。如果你在重新输入一个复杂的例子时弄得一团糟,你就必须重新输入。使用箭头键来访问和修改以前的命令是有用的,但也很有限。在本节中,我们将讲述代码重用的两个重要方式:文本编辑器和Python 函数。
3.1 使用文本编辑器创建程序
Python 交互式解释器中你一输入命令就执行。通常,使用文本编辑器组织多行程序,然后让Python 一次运行整个程序会更好。使用IDLE,你可以通过File菜单打开一个新窗口来做到这些。现在就尝试一下,输入下面的一行程序:
print('Monty Python')
将这段程序保存为文件,取名为monty.py,然后打开Run菜单,选择Run Module命令。(我们将很快学习到什么是模块。)IDLE 主窗口的结果应该像这样:
|
你也可以输入from monty import *,它将做同样的事情。
从现在起,你可以选择使用交互式解释器或文本编辑器来创建你的程序。使用解释器测试你的想法往往比较方便,修改一行代码直到达到你期望的效果。测试好之后,你就可以将代码粘贴到文本编辑器(去除所有>>> 和...提示符),继续扩展它。给文件一个小而准确的名字,使用所有的小写字母,用下划线分割词汇,使用.py文件名后缀,例如monty_python.py。
3.2 函数
假设你正在分析一些文本,这些文本包含同一个词的不同形式,你的一部分程序需要将给定的单数名词变成复数形式。假设需要在两个地方做这样的事,一个是处理一些文本,另一个是处理用户的输入。
比起重复相同的代码好几次,把这些事情放在一个函数中会更有效和可靠。一个函数是命名的代码块,执行一些明确的任务,就像我们在1中所看到的那样。一个函数通常被定义来使用一些称为参数的变量接受一些输入,并且它可能会产生一些结果,也称为返回值。我们使用关键字def加函数名以及所有输入参数来定义一个函数,接下来是函数的主体。这里是我们在1看到的函数(对于Python 2,请包含import语句,这样可以使除法像我们期望的那样运算):
|
我们使用关键字return表示函数作为输出而产生的值。在这个例子中,函数所有的工作都在return语句中完成。下面是一个等价的定义,使用多行代码做同样的事。我们将把参数名称从text变为my_text_data,注意这只是一个任意的选择:
|
请注意,我们已经在函数体内部创造了一些新的变量。这些是局部变量,不能在函数体外访问。现在我们已经定义一个名为lexical_diversity的函数。但只定义它不会产生任何输出!函数在被“调用”之前不会做任何事情:
|
让我们回到前面的场景,实际定义一个简单的函数来处理英文的复数词。3.1中的函数plural()接受单数名词,产生一个复数形式,虽然它并不总是正确的。(我们将在4.4中以更长的篇幅讨论这个函数。)
| ||
| ||
例 3.1 (code_plural.py):图 3.1:一个Python 函数:这个函数试图生成任何英语名词的复数形式;关键字def(define)后面跟着函数的名称,然后是包含在括号内的参数和一个冒号;函数体是缩进代码块;它试图识别词内的模式,相应的对词进行处理;例如,如果这个词以y结尾,删除y并添加ies。 |
endswith()函数总是与一个字符串对象一起使用(如3.1中的word)。要调用此函数,我们使用对象的名字,一个点,然后跟函数的名称。这些函数通常被称为方法。
3.3 模块
随着时间的推移,你将会发现你创建了大量小而有用的文字处理函数,结果你不停的把它们从老程序复制到新程序中。哪个文件中包含的才是你要使用的函数的最新版本?如果你能把你的劳动成果收集在一个单独的地方,而且访问以前定义的函数不必复制,生活将会更加轻松。
要做到这一点,请将你的函数保存到一个文件text_proc.py。现在,你可以简单的通过从文件导入它来访问你的函数:
|
显然,我们的复数函数明显存在错误,因为fan的复数是fans。不必再重新输入这个函数的新版本,我们可以简单的编辑现有的。因此,在任何时候我们的复数函数只有一个版本,不会再有使用哪个版本的困扰。
在一个文件中的变量和函数定义的集合被称为一个Python 模块。相关模块的集合称为一个包。处理布朗语料库的NLTK 代码是一个模块,处理各种不同的语料库的代码的集合是一个包。NLTK 的本身是包的集合,有时被称为一个库。
小心!
如果你正在创建一个包含一些你自己的Python 代码的文件,一定不要将文件命名为nltk.py:这可能会在导入时占据“真正的”NLTK 包。当Python 导入模块时,它先查找当前目录(文件夹)。
4 词汇资源
词典或者词典资源是一个词和/或短语以及一些相关信息的集合,例如:词性和词意定义等相关信息。词典资源附属于文本,通常在文本的帮助下创建和丰富。例如:如果我们定义了一个文本my_text,然后vocab = sorted(set(my_text))建立my_text的词汇,同时word_freq = FreqDist(my_text)计数文本中每个词的频率。vocab和word_freq都是简单的词汇资源。同样,如我们在1中看到的,词汇索引为我们提供了有关词语用法的信息,可能在编写词典时有用。4.1中描述了词汇相关的标准术语。一个词项包括词目(也叫词条)以及其他附加信息,例如词性和词意定义。两个不同的词拼写相同被称为同音异义词。

图 4.1:词典术语:两个拼写相同的词条(同音异义词)的词汇项,包括词性和注释信息。
最简单的词典是除了一个词汇列表外什么也没有。复杂的词典资源包括在词汇项内和跨词汇项的复杂的结构。在本节,我们来看看NLTK 中的一些词典资源。
4.1 词汇列表语料库
NLTK 包括一些仅仅包含词汇列表的语料库。词汇语料库是Unix 中的/usr/share/dict/words文件,被一些拼写检查程序使用。我们可以用它来寻找文本语料中不寻常的或拼写错误的词汇,如4.2所示。
| ||
例 4.2 (code_unusual.py):图 4.2:过滤文本:此程序计算文本的词汇表,然后删除所有在现有的词汇列表中出现的元素,只留下罕见或拼写错误的词。 |
还有一个停用词语料库,就是那些高频词汇,如the,to和also,我们有时在进一步的处理之前想要将它们从文档中过滤。停用词通常几乎没有什么词汇内容,而它们的出现会使区分文本变困难。
|
让我们定义一个函数来计算文本中没有在停用词列表中的词的比例:
|
因此,在停用词的帮助下,我们筛选掉文本中四分之一的词。请注意,我们在这里结合了两种不同类型的语料库,使用词典资源来过滤文本语料的内容。

图 4.3:一个字母拼词谜题::在由随机选择的字母组成的网格中,选择里面的字母组成词;这个谜题叫做“目标”。
一个词汇列表对解决如图4.3中这样的词的谜题很有用。我们的程序遍历每一个词,对于每一个词检查是否符合条件。检查必须出现的字母和长度限制是很容易的(这里我们只查找6个或6个以上字母的词)。只使用指定的字母组合作为候选方案,尤其是一些指定的字母出现了两次(这里如字母v)这样的检查是很棘手的。FreqDist比较法允许我们检查每个字母在候选词中的频率是否小于或等于相应的字母在拼词谜题中的频率。
|
另一个词汇列表是名字语料库,包括8000个按性别分类的名字。男性和女性的名字存储在单独的文件中。让我们找出同时出现在两个文件中的名字,即难以分辨性别的名字:
|
正如大家都知道的,以字母a结尾的名字几乎都是女性。我们可以在4.4中看到这一点以及一些其它的模式,该图是由下面的代码产生的。请记住name[-1]是name的最后一个字母。
|
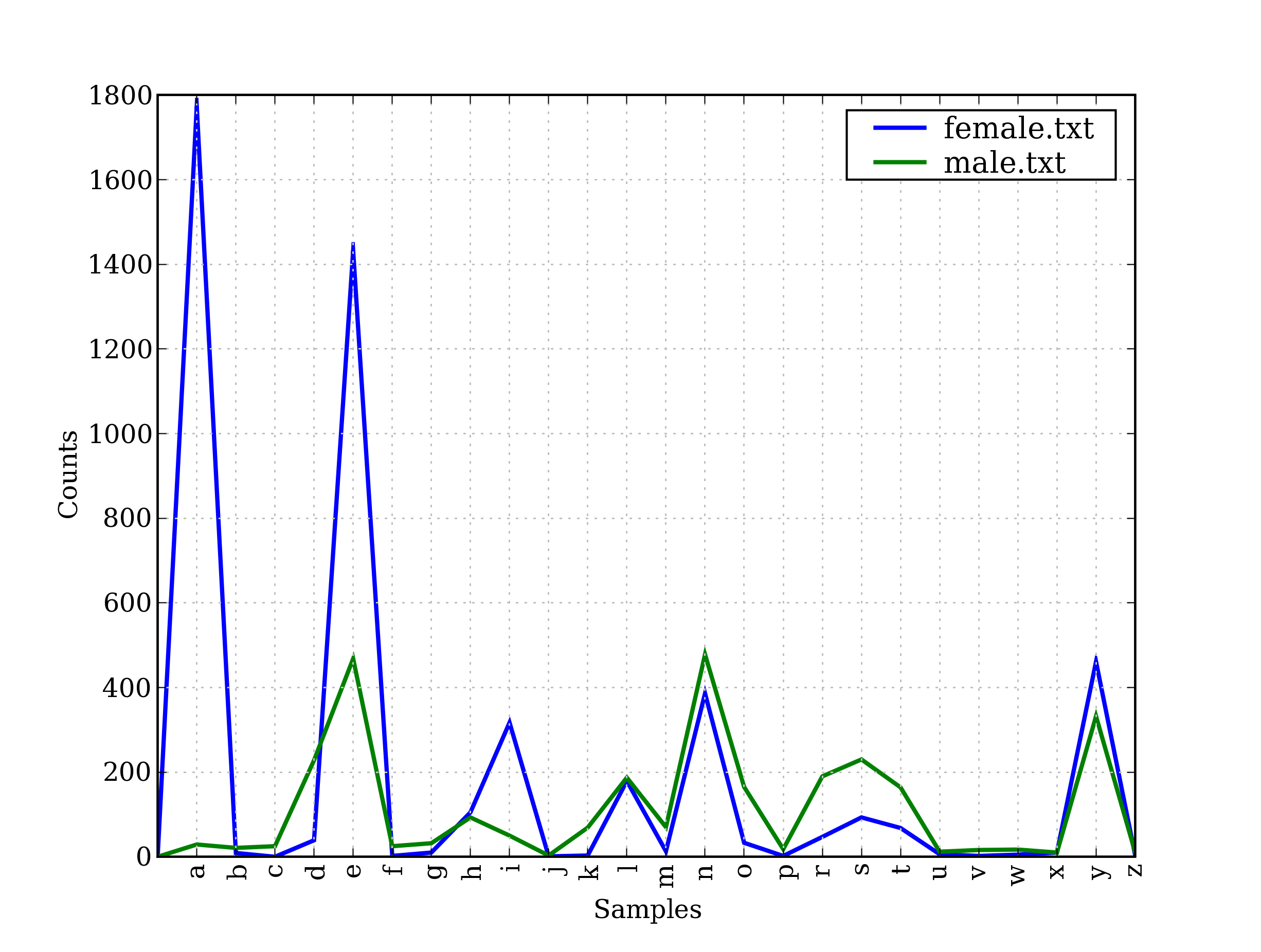
图 4.4:条件频率分布:此图显示男性和女性名字的结尾字母;大多数以a,e或i结尾的名字是女性;以h和l结尾的男性和女性同样多;以k, o, r, s和t结尾的更可能是男性。
4.2 发音的词典
一个稍微丰富的词典资源是一个表格(或电子表格),在每一行中含有一个词加一些性质。NLTK 中包括美国英语的CMU发音词典,它是为语音合成器使用而设计的。
|
对每一个词,这个词典资源提供语音的代码——不同的声音不同的标签——叫做phones。请看fire有两个发音(美国英语中):单音节F AY1 R和双音节F AY1 ER0。CMU 发音词典中的符号是从Arpabet来的,更多的细节请参考http://en.wikipedia.org/wiki/Arpabet。
每个条目由两部分组成,我们可以用一个复杂的for语句来一个一个的处理这些。我们没有写for entry in entries:,而是用两个变量名word, pron替换entry。现在,每次通过循环时,word被分配条目的第一部分,pron被分配条目的第二部分:
|
上面的程序扫描词典中那些发音包含三个音素的条目。如果条件为真,就将pron的内容分配给三个新的变量:ph1, ph2和ph3。请注意实现这个功能的语句的形式并不多见。
这里是同样的for语句的另一个例子,这次使用内部的列表推导。这段程序找到所有发音结尾与nicks相似的词汇。你可以使用此方法来找到押韵的词。
|
请注意,有几种方法来拼读一个读音:nics, niks, nix甚至ntic's加一个无声的t,如词atlantic's。让我们来看看其他一些发音与书写之间的不匹配。你可以总结一下下面的例子的功能,并解释它们是如何实现的?
|
音素包含数字表示主重音(1),次重音(2)和无重音(0)。作为我们最后的一个例子,我们定义一个函数来提取重音数字,然后扫描我们的词典,找到具有特定重音模式的词汇。
|
注意
这段程序的精妙之处在于:我们的用户自定义函数stress()调用一个内含条件的列表推导。还有一个双层嵌套for循环。这里有些复杂,等你有了更多的使用列表推导的经验后,你可能会想回过来重新阅读。
我们可以使用条件频率分布来帮助我们找到词汇的最小受限集合。在这里,我们找到所有p开头的三音素词,并按照它们的第一个和最后一个音素来分组。
|
我们可以通过查找特定词汇来访问词典,而不必遍历整个词典。我们将使用Python 的词典数据结构,在3节我们将系统的学习它。通过指定词典的名字后面跟一个包含在方括号里的关键字(例如词'fire')来查词典。
|
如果我们试图查找一个不存在的关键字,就会得到一个KeyError。这与我们使用一个过大的整数索引一个列表时产生一个IndexError是类似的。词blog在发音词典中没有,所以我们对我们自己版本的词典稍作调整,为这个关键字分配一个值(这对NLTK 语料库是没有影响的;下一次我们访问它,blog依然是空的)。
我们可以用任何词典资源来处理文本,如过滤掉具有某些词典属性的词(如名词),或者映射文本中每一个词。例如,下面的文本到发音函数在发音词典中查找文本中每个词:
|
4.3 比较词表
表格词典的另一个例子是比较词表。NLTK 中包含了所谓的斯瓦迪士核心词列表,几种语言中约200个常用词的列表。语言标识符使用ISO639 双字母码。
|
我们可以通过在entries() 方法中指定一个语言列表来访问多语言中的同源词。更进一步,我们可以把它转换成一个简单的词典(我们将在3学到dict()函数)。
|
通过添加其他源语言,我们可以让我们这个简单的翻译器更为有用。让我们使用dict()函数把德语-英语和西班牙语-英语对相互转换成一个词典,然后用这些添加的映射更新我们原来的翻译词典:
|
我们可以比较日尔曼语族和拉丁语族的不同:
|
4.4 词汇工具:Shoebox和Toolbox
可能最流行的语言学家用来管理数据的工具是Toolbox,以前叫做Shoebox,因为它用满满的档案卡片占据了语言学家的旧鞋盒。Toolbox 可以免费从http://www.sil.org/computing/toolbox/下载。
一个Toolbox 文件由一个大量条目的集合组成,其中每个条目由一个或多个字段组成。大多数字段都是可选的或重复的,这意味着这个词汇资源不能作为一个表格或电子表格来处理。
下面是一个罗托卡特语的词典。我们只看第一个条目,词kaa的意思是"to gag":
|
条目包括一系列的属性-值对,如('ps', 'V')表示词性是'V'(动词),('ge', 'gag')表示英文注释是''gag'。最后的3 个配对包含一个罗托卡特语例句和它的巴布亚皮钦语及英语翻译。
Toolbox 文件松散的结构使我们在现阶段很难更好的利用它。XML 提供了一种强有力的方式来处理这种语料库,我们将在11.回到这个的主题。
注意
罗托卡特语是巴布亚新几内亚的布干维尔岛上使用的一种语言。这个词典资源由Stuart Robinson 贡献给NLTK。罗托卡特语以仅有12 个音素(彼此对立的声音)而闻名。详情请参考:http://en.wikipedia.org/wiki/Rotokas_language
5 WordNet
WordNet是面向语义的英语词典,类似与传统辞典,但具有更丰富的结构。NLTK 中包括英语WordNet,共有155,287 个词和117,659 个同义词集合。我们将以寻找同义词和它们在WordNet中如何访问开始。
5.1 意义与同义词
考虑(1a)中的句子。如果我们用automobile替换掉(1a)中的词motorcar,变成(1b),句子的意思几乎保持不变:
| (1) |
|
因为句子中所有其他成分都保持不变,我们可以得出结论,motorcar和automobile有相同的含义,即它们是同义词。在WordNet的帮助下,我们可以探索这些词:
|
因此,motorcar只有一个可能的含义,它被定义为car.n.01,car的第一个名词意义。car.n.01被称为synset或“同义词集”,意义相同的词(或“词条”)的集合:
|
同义词集中的每个词可以有多种含义,例如:car也可能是火车车厢、一个货车或电梯厢。但我们只对这个同义词集中所有词来说最常用的一个意义感兴趣。同义词集也有一些一般的定义和例句:
|
虽然定义帮助人们了解一个同义词集的本意,同义词集中的词往往对我们的程序更有用。为了消除歧义,我们将这些词标记为car.n.01.automobile,car.n.01.motorcar等。这种同义词集和词的配对叫做词条。我们可以得到指定同义词集的所有词条,查找特定的词条,得到一个词条对应的同义词集,也可以得到一个词条的“名字”![[4]](./static/callout4.gif) :
:
|
与词motorcar意义明确且只有一个同义词集不同,词car是含糊的,有五个同义词集:
|
为方便起见,我们可以用下面的方式访问所有包含词car的词条。
|
注意
轮到你来:写下词dish的你能想到的所有意思。现在,在WordNet 的帮助下使用前面所示的相同的操作探索这个词。
5.2 WordNet的层次结构
WordNet 的同义词集对应于抽象的概念,它们并不总是有对应的英语词汇。这些概念在层次结构中相互联系在一起。一些概念也很一般,如实体、状态、事件;这些被称为唯一前缀或者根同义词集。其他的,如油老虎和有仓门式后背的汽车等就比较具体的多。5.1展示了一个概念层次的一小部分。
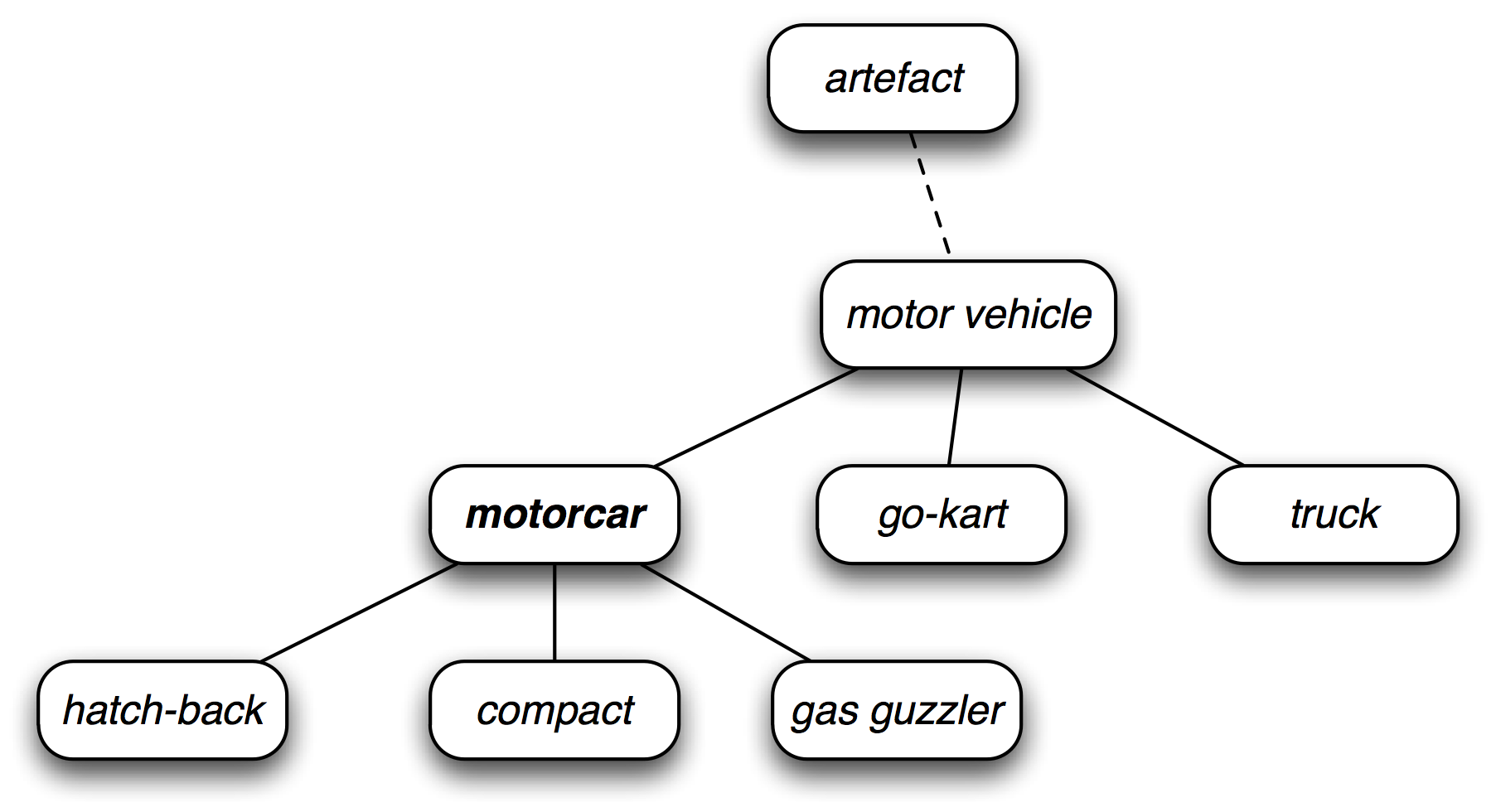
图 5.1:WordNet 概念层次片段:每个节点对应一个同义词集;边表示上位词/下位词关系,即上级概念与从属概念的关系。
WordNet 使在概念之间漫游变的容易。例如:一个如motorcar这样的概念,我们可以看到其更加具体(直接)的概念——下位词。
|
我们也可以通过访问上位词来浏览层次结构。有些词有多条路径,因为它们可以归类在一个以上的分类中。car.n.01与entity.n.01间有两条路径,因为wheeled_vehicle.n.01可以同时被归类为车辆和容器。
|
我们可以用如下方式得到一个最一般的上位(或根上位)同义词集:
|
注意
轮到你来: 尝试NLTK 中便捷的图形化WordNet浏览器:nltk.app.wordnet()。沿着上位词与下位词之间的链接,探索WordNet的层次结构。
5.3 更多的词汇关系
上位词和下位词被称为词汇关系,因为它们是同义集之间的关系。这个关系定位上下为“是一个”层次。WordNet 网络另一个重要的漫游方式是从元素到它们的部件(部分)或到它们被包含其中的东西(整体)。例如,一棵树的部分是它的树干,树冠等;这些都是part_meronyms()。一棵树的实质是包括心材和边材组成的,即substance_meronyms()。树木的集合形成了一个森林,即member_holonyms():
|
来看看可以获得多么复杂的东西,考虑具有几个密切相关意思的词mint。我们可以看到mint.n.04是mint.n.02的一部分,是组成mint.n.05的材质。
|
动词之间也有关系。例如,走路的动作包括抬脚的动作,所以走路蕴涵着抬脚。一些动词有多个蕴涵:
|
词条之间的一些词汇关系,如反义词:
|
你可以使用dir()查看词汇关系和同义词集上定义的其它方法,例如dir(wn.synset('harmony.n.02'))。
5.4 语义相似度
我们已经看到同义词集之间构成复杂的词汇关系网络。给定一个同义词集,我们可以遍历WordNet网络来查找相关含义的同义词集。知道哪些词是语义相关的,对索引文本集合非常有用,当搜索一个一般性的用语例如车辆时,就可以匹配包含具体用语例如豪华轿车的文档。
回想一下每个同义词集都有一个或多个上位词路径连接到一个根上位词,如entity.n.01。连接到同一个根的两个同义词集可能有一些共同的上位词(见图5.1)。如果两个同义词集共用一个非常具体的上位词——在上位词层次结构中处于较低层的上位词——它们一定有密切的联系。
|
当然,我们知道,鲸鱼是非常具体的(须鲸更是如此),脊椎动物是更一般的,而实体完全是抽象的一般的。我们可以通过查找每个同义词集深度量化这个一般性的概念:
|
WordNet同义词集的集合上定义的相似度能够包括上面的概念。例如,path_similarity是基于上位词层次结构中相互连接的概念之间的最短路径在0-1范围的打分(两者之间没有路径就返回-1)。同义词集与自身比较将返回1。考虑以下的相似度:露脊鲸与小须鲸、逆戟鲸、乌龟以及小说。数字本身的意义并不大,当我们从海洋生物的语义空间转移到非生物时它是减少的。
|
注意
还有一些其它的相似性度量方法;你可以输入help(wn)获得更多信息。NLTK 还包括VerbNet,一个连接到WordNet的动词的层次结构的词典。It can be accessed with nltk.corpus.verbnet.
6 小结
- 文本语料库是一个大型结构化文本的集合。NLTK 包含了许多语料库,如布朗语料库nltk.corpus.brown。
- 有些文本语料库是分类的,例如通过文体或者主题分类;有时候语料库的分类会相互重叠。
- 条件频率分布是一个频率分布的集合,每个分布都有一个不同的条件。它们可以用于通过给定内容或者文体对词的频率计数。
- 行数较多的Python 程序应该使用文本编辑器来输入,保存为.py后缀的文件,并使用import语句来访问。
- Python 函数允许你将一段特定的代码块与一个名字联系起来,然后重用这些代码想用多少次就用多少次。
- 一些被称为“方法”的函数与一个对象联系在起来,我们使用对象名称跟一个点然后跟方法名称来调用它,就像:x.funct(y)或者word.isalpha()。
- 要想找到一些关于某个变量v的信息,可以在Pyhon交互式解释器中输入help(v)来阅读这一类对象的帮助条目。
- WordNet是一个面向语义的英语词典,由同义词的集合——或称为同义词集——组成,并且组织成一个网络。
- 默认情况下有些函数是不能使用的,必须使用Python的import语句来访问。
7 深入阅读
本章的附加材料发布在http://nltk.org/,包括网络上免费提供的资源的链接。语料库方法总结请参阅http://nltk.org/howto上的语料库HOWTO,在线API文档中也有更广泛的资料。
公开发行的语料库的重要来源是语言数据联盟((LDC)和欧洲语言资源局(ELRA)。提供几十种语言的数以百计的已标注文本和语音语料库。非商业许可证允许这些数据用于教学和科研目的。其中一些语料库也提供商业许可(但需要较高的费用)。
用于创建标注的文本语料库的好工具叫做Brat,可从http://brat.nlplab.org/访问。
这些语料库和许多其他语言资源使用OLAC 元数据格式存档,可以通过 http://www.language-archives.org/上的OLAC 主页搜索到。Corpora List是一个讨论语料库内容的邮件列表,你可以通过搜索列表档案来找到资源或发布资源到列表中。Ethnologue是最完整的世界上的语言的清单,http://www.ethnologue.com/。7000 种语言中只有几十中有大量适合NLP 使用的数字资源。
本章触及语料库语言学领域。在这一领域的其他有用的书籍包括(Biber, Conrad, & Reppen, 1998), (McEnery, 2006), (Meyer, 2002), (Sampson & McCarthy, 2005), (Scott & Tribble, 2006)。在语言学中海量数据分析的深入阅读材料有:(Baayen, 2008), (Gries, 2009), (Woods, Fletcher, & Hughes, 1986)。
WordNet原始描述是(Fellbaum, 1998)。虽然WordNet最初是为心理语言学研究开发的,它目前在自然语言处理和信息检索领域被广泛使用。WordNets 正在开发许多其他语言的版本,在http://www.globalwordnet.org/中有记录。学习WordNet相似性度量可以阅读(Budanitsky & Hirst, 2006)。
本章触及的其它主题是语音和词汇语义学,读者可以参考(Jurafsky & Martin, 2008)的第7和第20章。
8 练习
- ☼ 创建一个变量phrase包含一个词的列表。实验本章描述的操作,包括加法、乘法、索引、切片和排序。
- ☼ 使用语料库模块处理austen-persuasion.txt。这本书中有多少词符?多少词型?
- ☼ 使用布朗语料库阅读器nltk.corpus.brown.words()或网络文本语料库阅读器nltk.corpus.webtext.words()来访问两个不同文体的一些样例文本。
- ☼ 使用state_union语料库阅读器,访问《国情咨文报告》的文本。计数每个文档中出现的men、women和people。随时间的推移这些词的用法有什么变化?
- ☼ 考查一些名词的整体部分关系。请记住,有3 种整体部分关系,所以你需要使用:member_meronyms(), part_meronyms(), substance_meronyms(), member_holonyms(), part_holonyms()和substance_holonyms()。
- ☼ 在比较词表的讨论中,我们创建了一个对象叫做translate,通过它你可以使用德语和意大利语词汇查找对应的英语词汇。这种方法可能会出现什么问题?你能提出一个办法来避免这个问题吗?
- ☼ 根据Strunk 和White 的《Elements of Style》,词however在句子开头使用是“in whatever way”或“to whatever extent”的意思,而没有“nevertheless”的意思。他们给出了正确用法的例子:However you advise him, he will probably do as he thinks best.(http://www.bartleby.com/141/strunk3.html) 使用词汇索引工具在我们一直在思考的各种文本中研究这个词的实际用法。也可以看LanguageLog发布在http://itre.cis.upenn.edu/~myl/languagelog/archives/001913.html上的“Fossilized prejudices abou‘t however’”。
- ◑ 在名字语料库上定义一个条件频率分布,显示哪个首字母在男性名字中比在女性名字中更常用(参见4.4)。
- ◑ 挑选两个文本,研究它们之间在词汇、词汇丰富性、文体等方面的差异。你能找出几个在这两个文本中词意相当不同的词吗,例如在《白鲸记》与《理智与情感》中的monstrous?
- ◑ 阅读BBC 新闻文章:UK's Vicky Pollards 'left behind' http://news.bbc.co.uk/1/hi/education/6173441.stm。文章给出了有关青少年语言的以下统计:“使用最多的20 个词,包括yeah, no, but 和like,占所有词的大约三分之一”。对于大量文本源来说,所有词标识符的三分之一有多少词类型?你从这个统计中得出什么结论?更多相关信息请阅读http://itre.cis.upenn.edu/~myl/languagelog/archives/003993.html上的LanguageLog。
- ◑ 调查模式分布表,寻找其他模式。试着用你自己对不同文体的印象理解来解释它们。你能找到其他封闭的词汇归类,展现不同文体的显著差异吗?
- ◑ CMU 发音词典包含某些词的多个发音。它包含多少种不同的词?具有多个可能的发音的词在这个词典中的比例是多少?
- ◑ 没有下位词的名词同义词集所占的百分比是多少?你可以使用wn.all_synsets('n')得到所有名词同义词集。
- ◑ 定义函数supergloss(s),使用一个同义词集s作为它的参数,返回一个字符串,包含s的定义和s所有的上位词与下位词的定义的连接字符串。
- ◑ 写一个程序,找出所有在布朗语料库中出现至少3 次的词。
- ◑ 写一个程序,生成一个词汇多样性得分表(例如词符/词型的比例),如我们在1.1所看到的。包括布朗语料库文体的全集 (nltk.corpus.brown.categories())。哪个文体词汇多样性最低(每个类型的标识符数最多)?这是你所期望的吗?
- ◑ 写一个函数,找出一个文本中最常出现的50个词,停用词除外。
- ◑ 写一个程序,输出一个文本中50 个最常见的双连词(相邻词对),忽略包含停用词的双连词。
- ◑ 写一个程序,按文体创建一个词频表,以1节给出的词频表为范例。选择你自己的词汇,并尝试找出那些在一个文体中很突出或很缺乏的词汇。讨论你的发现。
- ◑ 写一个函数word_freq(),用一个词和布朗语料库中的一个部分的名字作为参数,计算这部分语料中词的频率。
- ◑ 写一个程序,估算一个文本中的音节数,利用CMU发音词典。
- ◑ 定义一个函数hedge(text),处理一个文本和产生一个新的版本在每三个词之间插入一个词'like'。
- ★ 齐夫定律:f(w)是一个自由文本中的词w的频率。假设一个文本中的所有词都按照它们的频率排名,频率最高的在最前面。齐夫定律指出一个词类型的频率与它的排名成反比(即f × r = k,k是某个常数)。例如:最常见的第50个词类型出现的频率应该是最常见的第150个词型出现频率的3倍。
- 写一个函数来处理一个大文本,使用pylab.plot画出相对于词的排名的词的频率。你认可齐夫定律吗?(提示:使用对数刻度会有帮助。)所绘的线的极端情况是怎样的?
- 随机生成文本,如使用random.choice("abcdefg "),注意要包括空格字符。你需要事先import random。使用字符串连接操作将字符累积成一个很长的字符串。然后为这个字符串分词,产生前面的齐夫图,比较这两个图。此时你怎么看齐夫定律?
- ★ 修改例2.2的文本生成程序,进一步完成下列任务:
- 在一个列表words中存储n个最相似的词,使用random.choice()从列表中随机选取一个词。(你将需要事先import random。)
- 选择特定的文体,如布朗语料库中的一部分或者《创世纪》翻译或者古腾堡语料库中的文本或者一个网络文本。在此语料上训练一个模型,产生随机文本。你可能要实验不同的起始字。文本的可理解性如何?讨论这种方法产生随机文本的长处和短处。
- 现在使用两种不同文体训练你的系统,使用混合文体文本做实验。讨论你的观察结果。
- ★ 定义一个函数find_language(),用一个字符串作为其参数,返回包含这个字符串作为词汇的语言的列表。使用《世界人权宣言》udhr的语料,将你的搜索限制在Latin-1 编码的文件中。
- ★ 名词上位词层次的分枝因素是什么?也就是说,对于每一个具有下位词——上位词层次中的子女——的名词同义词集,它们平均有几个下位词?你可以使用wn.all_synsets('n')获得所有名词同义词集。
- ★ 一个词的多义性是它所有含义的个数。利用WordNet,使用len(wn.synsets('dog', 'n'))我们可以判断名词dog有7 种含义。计算WordNet 中名词、动词、形容词和副词的平均多义性。
- ★使用预定义的相似性度量之一给下面的每个词对的相似性打分。按相似性减少的顺序排名。你的排名与这里给出的顺序有多接近?(Miller & Charles, 1998)实验得出的顺序: car-automobile, gem-jewel, journey-voyage, boy-lad, coast-shore, asylum-madhouse, magician-wizard, midday-noon, furnace-stove, food-fruit, bird-cock, bird-crane, tool-implement, brother-monk, lad-brother, crane-implement, journey-car, monk-oracle, cemetery-woodland, food-rooster, coast-hill, forest-graveyard, shore-woodland, monk-slave, coast-forest, lad-wizard, chord-smile, glass-magician, rooster-voyage, noon-string。
关于本文档...
针对NLTK 3.0 作出更新。本章来自于Natural Language Processing with Python,Steven Bird, Ewan Klein 和Edward Loper,Copyright © 2014 作者所有。本章依据Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License [http://creativecommons.org/licenses/by-nc-nd/3.0/us/] 条款,与自然语言工具包 [http://nltk.org/] 3.0 版一起发行。
本文档构建于星期三 2015 年 7 月 1 日 12:30:05 AEST