6. 学习分类文本
模式识别是自然语言处理的一个核心部分。以-ed结尾的词往往是过去时态动词(5.)。频繁使用will是新闻文本的暗示(3)。这些可观察到的模式——词的结构和词频——恰好与特定方面的含义关联,如时态和主题。但我们怎么知道从哪里开始寻找,形式的哪一方面关联含义的哪一方面?
本章的目的是要回答下列问题:
- 我们怎样才能识别语言数据中能明显用于对其分类的特征?
- 我们怎样才能构建语言模型,用于自动执行语言处理任务?
- 从这些模型中我们可以学到哪些关于语言的知识?
一路上,我们将研究一些重要的机器学习技术,包括决策树、朴素贝叶斯分类器和最大熵分类。我们会掩盖这些技术的数学和统计的基础,集中关注如何以及何时使用它们(更多的技术背景知识见进一步阅读一节)。在看这些方法之前,我们首先需要知道这个主题的范围十分广泛。
1 有监督分类
分类是为给定的输入选择正确的类标签的任务。在基本的分类任务中,每个输入被认为是与所有其它输入隔离的,并且标签集是预先定义的。这里是分类任务的一些例子:
- 判断一封电子邮件是否是垃圾邮件。
- 从一个固定的主题领域列表中,如“体育”、“技术”和“政治”,决定新闻报道的主题是什么。
- 决定词bank给定的出现是用来指河的坡岸、一个金融机构、向一边倾斜的动作还是在金融机构里的存储行为。
基本的分类任务有许多有趣的变种。例如,在多类分类中,每个实例可以分配多个标签;在开放性分类中,标签集是事先没有定义的;在序列分类中,一个输入列表作为一个整体分类。
一个分类称为有监督的,如果它的建立基于训练语料的每个输入包含正确标签。有监督分类使用的框架图如1.1所示。
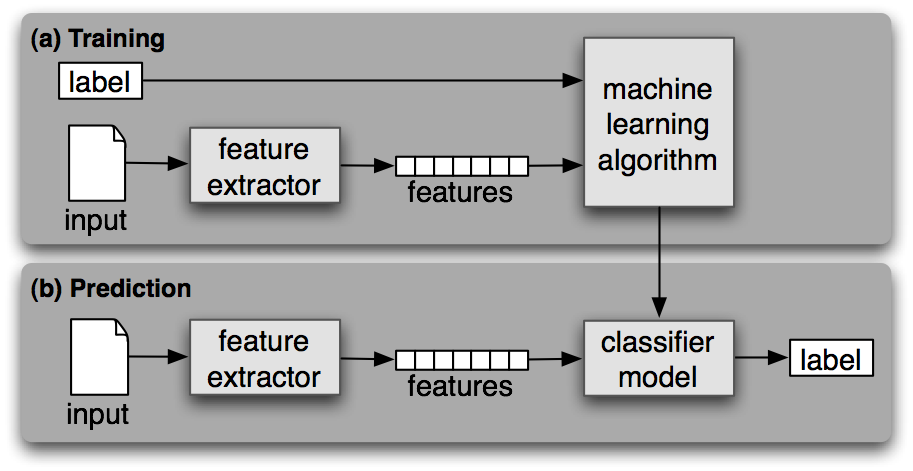
图 1.1:有监督分类。(a)在训练过程中,特征提取器用来将每一个输入值转换为特征集。这些特征集捕捉每个输入中应被用于对其分类的基本信息,我们将在下一节中讨论它。特征集与标签的配对被送入机器学习算法,生成模型。(b)在预测过程中,相同的特征提取器被用来将未见过的输入转换为特征集。之后,这些特征集被送入模型产生预测标签。
在本节的其余部分,我们将着眼于分类器如何能够解决各种各样的任务。我们讨论的目的不是要范围全面,而是给出在文本分类器的帮助下执行的任务的一个代表性的例子。
1.1 性别鉴定
在4中,我们看到,男性和女性的名字有一些鲜明的特点。以a,e和i结尾的很可能是女性,而以k,o,r,s和t结尾的很可能是男性。让我们建立一个分类器更精确地模拟这些差异。
创建一个分类器的第一步是决定输入的什么样的特征是相关的,以及如何为那些特征编码。在这个例子中,我们一开始只是寻找一个给定的名称的最后一个字母。以下特征提取器函数建立一个字典,包含有关给定名称的相关信息:
|
这个函数返回的字典被称为特征集,映射特征名称到它们的值。特征名称是区分大小写的字符串,通常提供一个简短的人可读的特征描述,例如本例中的'last_letter'。特征值是简单类型的值,如布尔、数字和字符串。
注意
大多数分类方法要求特征使用简单的类型进行编码,如布尔类型、数字和字符串。但要注意仅仅因为一个特征是简单类型,并不一定意味着该特征的值易于表达或计算。的确,它可以用非常复杂的和有信息量的值作为特征,如第2个有监督分类器的输出。
现在,我们已经定义了一个特征提取器,我们需要准备一个例子和对应类标签的列表。
|
接下来,我们使用特征提取器处理names数据,并划分特征集的结果链表为一个训练集和一个测试集。训练集用于训练一个新的“朴素贝叶斯”分类器。
|
在本章的后面,我们将学习更多关于朴素贝叶斯分类器的内容。现在,让我们只是在上面测试一些没有出现在训练数据中的名字:
|
请看《黑客帝国》中这些角色的名字被正确分类。尽管这部科幻电影的背景是在2199年,但它仍然符合我们有关名字和性别的预期。我们可以在大数据量的未见过的数据上系统地评估这个分类器:
|
最后,我们可以检查分类器,确定哪些特征对于区分名字的性别是最有效的:
|
此列表显示训练集中以a 结尾的名字中女性是男性的38倍,而以k 结尾名字中男性是女性的31倍。这些比率称为似然比,可以用于比较不同特征-结果关系。
注意
轮到你来:修改gender_features()函数,为分类器提供名称的长度、它的第一个字母以及任何其他看起来可能有用的特征。用这些新特征重新训练分类器,并测试其准确性。
在处理大型语料库时,构建一个包含每一个实例的特征的单独的列表会使用大量的内存。在这些情况下,使用函数nltk.classify.apply_features,返回一个行为像一个列表而不会在内存存储所有特征集的对象:
|
1.2 选择正确的特征
选择相关的特征,并决定如何为一个学习方法编码它们,这对学习方法提取一个好的模型可以产生巨大的影响。建立一个分类器的很多有趣的工作之一是找出哪些特征可能是相关的,以及我们如何能够表示它们。虽然使用相当简单而明显的特征集往往可以得到像样的性能,但是使用精心构建的基于对当前任务的透彻理解的特征,通常会显著提高收益。
典型地,特征提取通过反复试验和错误的过程建立的,由哪些信息是与问题相关的直觉指引的。它通常以“厨房水槽”的方法开始,包括你能想到的所有特征,然后检查哪些特征是实际有用的。我们在1.2中对名字性别特征采取这种做法。
| ||
| ||
例 1.2 (code_gender_features_overfitting.py):图 1.2:一个特征提取器,过拟合性别特征。这个特征提取器返回的特征集包括大量指定的特征,从而导致对于相对较小的名字语料库过拟合。 |
然而,你要用于一个给定的学习算法的特征的数目是有限的——如果你提供太多的特征,那么该算法将高度依赖你的训练数据的特性,而一般化到新的例子的效果不会很好。这个问题被称为过拟合,当运作在小训练集上时尤其会有问题。例如,如果我们使用1.2中所示的特征提取器训练朴素贝叶斯分类器,将会过拟合这个相对较小的训练集,造成这个系统的精度比只考虑每个名字最后一个字母的分类器的精度低约1%:
|
一旦初始特征集被选定,完善特征集的一个非常有成效的方法是错误分析。首先,我们选择一个开发集,包含用于创建模型的语料数据。然后将这种开发集分为训练集和开发测试集。
|
训练集用于训练模型,开发测试集用于进行错误分析。测试集用于系统的最终评估。由于下面讨论的原因,我们将一个单独的开发测试集用于错误分析而不是使用测试集是很重要的。在1.3中显示了将语料数据划分成不同的子集。
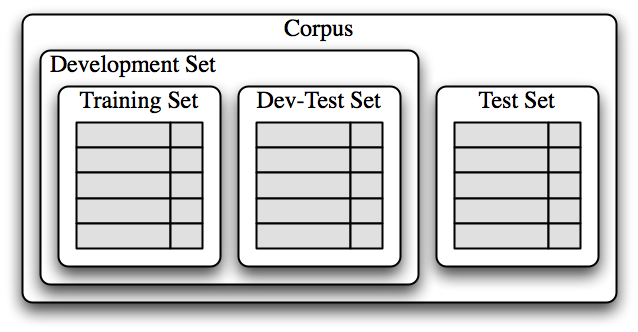
图 1.3:用于训练有监督分类器的语料数据组织图。语料数据分为两类:开发集和测试集。开发集通常被进一步分为训练集和开发测试集。
已经将语料分为适当的数据集,我们使用训练集训练一个模型![[1]](./static/callout1.gif) ,然后在开发测试集上运行
,然后在开发测试集上运行![[2]](./static/callout2.gif) 。
。
|
使用开发测试集,我们可以生成一个分类器预测名字性别时的错误列表:
|
然后,可以检查个别错误案例,在那里该模型预测了错误的标签,尝试确定什么额外信息将使其能够作出正确的决定(或者现有的哪部分信息导致其做出错误的决定)。然后可以相应的调整特征集。我们已经建立的名字分类器在开发测试语料上产生约100个错误:
|
浏览这个错误列表,它明确指出一些多个字母的后缀可以指示名字性别。例如,yn结尾的名字显示以女性为主,尽管事实上,n结尾的名字往往是男性;以ch结尾的名字通常是男性,尽管以h结尾的名字倾向于是女性。因此,调整我们的特征提取器包括两个字母后缀的特征:
|
使用新的特征提取器重建分类器,我们看到测试数据集上的性能提高了近3个百分点(从76.5%到78.2%):
|
这个错误分析过程可以不断重复,检查存在于由新改进的分类器产生的错误中的模式。每一次错误分析过程被重复,我们应该选择一个不同的开发测试/训练分割,以确保该分类器不会开始反映开发测试集的特质。
但是,一旦我们已经使用了开发测试集帮助我们开发模型,关于这个模型在新数据会表现多好,我们将不能再相信它会给我们一个准确地结果。因此,保持测试集分离、未使用过,直到我们的模型开发完毕是很重要的。在这一点上,我们可以使用测试集评估模型在新的输入值上执行的有多好。
1.3 文档分类
在1中,我们看到了语料库的几个例子,那里文档已经按类别标记。使用这些语料库,我们可以建立分类器,自动给新文档添加适当的类别标签。首先,我们构造一个标记了相应类别的文档清单。对于这个例子,我们选择电影评论语料库,将每个评论归类为正面或负面。
|
接下来,我们为文档定义一个特征提取器,这样分类器就会知道哪些方面的数据应注意(1.4)。对于文档主题识别,我们可以为每个词定义一个特性表示该文档是否包含这个词。为了限制分类器需要处理的特征的数目,我们一开始构建一个整个语料库中前2000个最频繁词的列表。然后,定义一个特征提取器,简单地检查这些词是否在一个给定的文档中。
| ||
| ||
例 1.4 (code_document_classify_fd.py):图 1.4:一个文档分类的特征提取器,其特征表示每个词是否在一个给定的文档中。 |
注意
在![[3]](./static/callout3.gif) 中我们计算文档的所有词的集合,而不仅仅检查是否word in document,因为检查一个词是否在一个集合中出现比检查它是否在一个列表中出现要快的多(4.7)。
中我们计算文档的所有词的集合,而不仅仅检查是否word in document,因为检查一个词是否在一个集合中出现比检查它是否在一个列表中出现要快的多(4.7)。
现在,我们已经定义了我们的特征提取器,可以用它来训练一个分类器,为新的电影评论加标签(1.5)。为了检查产生的分类器可靠性如何,我们在测试集上计算其准确性。再一次的,我们可以使用show_most_informative_features()来找出哪些特征是分类器发现最有信息量的。
| ||
| ||
例 1.5 (code_document_classify_use.py):图 1.5:训练和测试一个分类器进行文档分类。 |
显然在这个语料库中,提到Seagal的评论中负面的是正面的大约8倍,而提到Damon的评论中正面的是负面的大约6倍。
1.4 词性标注
第5.中,我们建立了一个正则表达式标注器,通过查找词内部的组成,为词选择词性标记。然而,这个正则表达式标注器是手工制作的。作为替代,我们可以训练一个分类器来算出哪个后缀最有信息量。首先,让我们找出最常见的后缀:
|
|
接下来,我们将定义一个特征提取器函数,检查给定的单词的这些后缀:
|
特征提取函数的行为就像有色眼镜一样,强调我们的数据中的某些属性(颜色),并使其无法看到其他属性。分类器在决定如何标记输入时,将完全依赖它们强调的属性。在这种情况下,分类器将只基于一个给定的词拥有(如果有)哪个常见后缀的信息来做决定。
现在,我们已经定义了我们的特征提取器,可以用它来训练一个新的“决策树”的分类器(将在4讨论):
|
|
|
|
决策树模型的一个很好的性质是它们往往很容易解释——我们甚至可以指示NLTK将它们以伪代码形式输出:
|
在这里,我们可以看到分类器一开始检查一个词是否以逗号结尾——如果是,它会得到一个特别的标记","。接下来,分类器检查词是否以"the"尾,这种情况它几乎肯定是一个限定词。这个“后缀”被决策树早早使用是因为词"the"太常见。分类器继续检查词是否以"s"结尾。如果是,那么它极有可能得到动词标记VBZ(除非它是这个词"is",它有特殊标记BEZ),如果不是,那么它往往是名词(除非它是标点符号“.”)。实际的分类器包含这里显示的if-then语句下面进一步的嵌套,参数depth=4 只显示决策树的顶端部分。
1.5 探索上下文语境
通过增加特征提取函数,我们可以修改这个词性标注器来利用各种词内部的其他特征,例如词长、它所包含的音节数或者它的前缀。然而,只要特征提取器仅仅看着目标词,我们就没法添加依赖词出现的上下文语境特征。然而上下文语境特征往往提供关于正确标记的强大线索——例如,标注词"fly",如果知道它前面的词是“a”将使我们能够确定它是一个名词,而不是一个动词。
为了采取基于词的上下文的特征,我们必须修改以前为我们的特征提取器定义的模式。不是只传递已标注的词,我们将传递整个(未标注的)句子,以及目标词的索引。1.6演示了这种方法,使用依赖上下文的特征提取器定义一个词性标记分类器。
| ||
| ||
例 1.6 (code_suffix_pos_tag.py):图 1.6:一个词性分类器,它的特征检测器检查一个词出现的上下文以便决定应该分配的词性标记。特别的,前面的词被作为一个特征。 |
很显然,利用上下文特征提高了我们的词性标注器的准确性。例如,分类器学到一个词如果紧跟在词"large"或"gubernatorial"后面,极可能是名词。然而,它无法学到,一个词如果它跟在形容词后面可能是名词,这样更一般的,因为它没有获得前面这个词的词性标记。在一般情况下,简单的分类器总是将每一个输入与所有其他输入独立对待。在许多情况下,这非常有道理。例如,关于名字是否倾向于男性或女性的决定可以通过具体分析来做出。然而,有很多情况,如词性标注,我们感兴趣的是解决彼此密切相关的分类问题。
1.6 序列分类
为了捕捉相关的分类任务之间的依赖关系,我们可以使用联合分类器模型,收集有关输入,选择适当的标签。在词性标注的例子中,各种不同的序列分类器模型可以被用来为一个给定的句子中的所有的词共同选择词性标签。
一种序列分类器策略,称为连续分类或贪婪序列分类,是为第一个输入找到最有可能的类标签,然后使用这个问题的答案帮助找到下一个输入的最佳的标签。这个过程可以不断重复直到所有的输入都被贴上标签。这是5中的二元标注器采用的方法,它一开始为句子的第一个词选择词性标记,然后为每个随后的词选择标记,基于词本身和前面词的预测的标记。
在1.7中演示了这一策略。首先,我们必须扩展我们的特征提取函数使其具有参数history,它提供一个我们到目前为止已经为句子预测的标记的列表。history中的每个标记对应sentence中的一个词。但是请注意,history将只包含我们已经归类的词的标记,也就是目标词左侧的词。因此,虽然是有可能查看目标词右边的词的某些特征,但查看那些词的标记是不可能的(因为我们还未产生它们)。
已经定义了特征提取器,我们可以继续建立我们的序列分类器。在训练中,我们使用已标注的标记为征提取器提供适当的历史信息,但标注新的句子时,我们基于标注器本身的输出产生历史信息。
| ||
| ||
例 1.7 (code_consecutive_pos_tagger.py):图 1.7:使用连续分类器进行词性标注 |
1.7 其他序列分类方法
这种方法的一个缺点是我们的决定一旦做出无法更改。例如,如果我们决定将一个词标注为名词,但后来发现的证据表明应该是一个动词,就没有办法回去修复我们的错误。这个问题的一个解决方案是采取转型策略。转型联合分类的工作原理是为输入的标签创建一个初始值,然后反复提炼那个值,尝试修复相关输入之间的不一致。Brill标注器,(1)中描述的,是这种策略的一个很好的例子。
另一种方案是为词性标记所有可能的序列打分,选择总得分最高的序列。隐马尔可夫模型就采取这种方法。隐马尔可夫模型类似于连续分类器,它不光看输入也看已预测标记的历史。然而,不是简单地找出一个给定的词的单个最好的标签,而是为标记产生一个概率分布。然后将这些概率结合起来计算标记序列的概率得分,最高概率的标记序列会被选中。不幸的是,可能的标签序列的数量相当大。给定30 个标签的标记集,有大约600 万亿(3010)种方式来标记一个10个词的句子。为了避免单独考虑所有这些可能的序列,隐马尔可夫模型要求特征提取器只看最近的标记(或最近的n个标记,其中n是相当小的)。由于这种限制,它可以使用动态规划(4.7),有效地找出最有可能的标记序列。特别是,对每个连续的词索引i,每个可能的当前及以前的标记都被计算得分。这种同样基础的方法被两个更先进的模型所采用,它们被称为最大熵马尔可夫模型和线性链条件随机场模型;但为标记序列打分用的是不同的算法。
2 有监督分类的更多例子
2.1 句子分割
句子分割可以看作是一个标点符号的分类任务:每当我们遇到一个可能会结束一个句子的符号,如句号或问号,我们必须决定它是否终止了当前句子。
第一步是获得一些已被分割成句子的数据,将它转换成一种适合提取特征的形式:
|
在这里,tokens是单独句子标识符的合并列表,boundaries是一个包含所有句子边界词符索引的集合。下一步,我们需要指定用于决定标点是否表示句子边界的数据特征:
|
基于这一特征提取器,我们可以通过选择所有的标点符号创建一个加标签的特征集的列表,然后标注它们是否是边界标识符:
|
使用这些特征集,我们可以训练和评估一个标点符号分类器:
|
使用这种分类器进行断句,我们只需检查每个标点符号,看它是否是作为一个边界标识符;在边界标识符处分割词列表。在2.1中的清单显示了如何可以做到这一点。
| ||
例 2.1 (code_classification_based_segmenter.py):图 2.1:基于分类的断句器 |
2.2 识别对话行为类型
处理对话时,将对话看作说话者执行的行为是很有用的。对于表述行为的陈述句这种解释是最直白的,例如"I forgive you"或"I bet you can't climb that hill"。但是问候、问题、回答、断言和说明都可以被认为是基于语言的行为类型。识别对话中言语下的对话行为是理解谈话的重要的第一步。
NPS聊天语料库,在1中的展示过,包括超过10,000个来自即时消息会话的帖子。这些帖子都已经被贴上15 种对话行为类型中的一种标签,例如“陈述”,“情感”,“yn问题”和“Continuer”。因此,我们可以利用这些数据建立一个分类器,识别新的即时消息帖子的对话行为类型。第一步是提取基本的消息数据。我们将调用xml_posts()来得到一个数据结构,表示每个帖子的XML注释:
|
下一步,我们将定义一个简单的特征提取器,检查帖子包含什么词:
|
最后,我们通过为每个帖子提取特征(使用post.get('class')获得一个帖子的对话行为类型)构造训练和测试数据,并创建一个新的分类器:
|
2.3 识别文字蕴含
识别文字蕴含(RTE)是判断文本T的一个给定片段是否蕴含着另一个叫做“假设”的文本(已经在5讨论过)。迄今为止,已经有4个RTE挑战赛,在那里共享的开发和测试数据会提供给参赛队伍。这里是挑战赛3开发数据集中的文本/假设对的两个例子。标签True表示蕴含成立,False表示蕴含不成立。
Challenge 3, Pair 34 (True)
T: Parviz Davudi was representing Iran at a meeting of the Shanghai Co-operation Organisation (SCO), the fledgling association that binds Russia, China and four former Soviet republics of central Asia together to fight terrorism.
H: China is a member of SCO.
Challenge 3, Pair 81 (False)
T: According to NC Articles of Organization, the members of LLC company are H. Nelson Beavers, III, H. Chester Beavers and Jennie Beavers Stewart.
H: Jennie Beavers Stewart is a share-holder of Carolina Analytical Laboratory.
应当强调,文字和假设之间的关系并不一定是逻辑蕴涵,而是一个人是否会得出结论:文本提供了合理的证据证明假设是真实的。
我们可以把RTE当作一个分类任务,尝试为每一对预测True/False标签。虽然这项任务的成功做法似乎看上去涉及语法分析、语义和现实世界的知识的组合,RTE的许多早期的尝试使用粗浅的分析基于文字和假设之间的在词级别的相似性取得了相当不错的结果。在理想情况下,我们希望如果有一个蕴涵那么假设所表示的所有信息也应该在文本中表示。相反,如果假设中有的资料文本中没有,那么就没有蕴涵。
在我们的RTE 特征探测器(2.2)中,我们让词(即词类型)作为信息的代理,我们的特征计数词重叠的程度和假设中有而文本中没有的词的程度(由hyp_extra()方法获取)。不是所有的词都是同样重要的——命名实体,如人、组织和地方的名称,可能会更为重要,这促使我们分别为words和nes(命名实体)提取不同的信息。此外,一些高频虚词作为“停用词”被过滤掉。
| [xx] | give some intro to RTEFeatureExtractor? ? |
| ||
例 2.2 (code_rte_features.py):图 2.2: “认识文字蕴涵”的特征提取器。RTEFeatureExtractor类建立了一个除去一些停用词后在文本和假设中都有的词汇包,然后计算重叠和差异。 |
为了说明这些特征的内容,我们检查前面显示的文本/假设对34的一些属性:
|
这些特征表明假设中所有重要的词都包含在文本中,因此有一些证据支持标记这个为True。
nltk.classify.rte_classify模块使用这些方法在合并的RTE测试数据上取得了刚刚超过58%的准确率。这个数字并不是很令人印象深刻的,还需要大量的努力,更多的语言学处理,才能达到更好的结果。
2.4 扩展到大型数据集
Python提供了一个良好的环境进行基本的文本处理和特征提取。然而,它处理机器学习方法需要的密集数值计算不能够如C语言那样的低级语言那么快。因此,如果你尝试在大型数据集使用纯Python 的机器学习实现(如nltk.NaiveBayesClassifier),你可能会发现学习算法会花费大量的时间和内存。
如果你打算用大量训练数据或大量特征来训练分类器,我们建议你探索NLTK与外部机器学习包的接口。只要这些软件包已安装,NLTK可以透明地调用它们(通过系统调用)来训练分类模型,明显比纯Python的分类实现快。请看NLTK网站上推荐的NLTK支持的机器学习包列表。
3 评估
为了决定一个分类模型是否准确地捕捉了模式,我们必须评估该模型。评估的结果对于决定模型是多么值得信赖以及我们如何使用它是非常重要。评估也可以是一个有效的工具,用于指导我们在未来改进模型。
3.1 测试集
大多数评估技术为模型计算一个得分,通过比较它在测试集(或评估集)中为输入生成的标签与那些输入的正确标签。该测试集通常与训练集具有相同的格式。然而,测试集与训练语料不同是非常重要的:如果我们简单地重复使用训练集作为测试集,那么一个只记住了它的输入而没有学会如何推广到新的例子的模型会得到误导人的高分。
建立测试集时,往往是一个可用于测试的和可用于训练的数据量之间的权衡。对于有少量平衡的标签和一个多样化的测试集的分类任务,只要100个评估实例就可以进行有意义的评估。但是,如果一个分类任务有大量的标签或包括非常罕见的标签,那么选择的测试集的大小就要保证出现次数最少的标签至少出现50次。此外,如果测试集包含许多密切相关的实例——例如来自一个单独文档中的实例——那么测试集的大小应增加,以确保这种多样性的缺乏不会扭曲评估结果。当有大量已标注数据可用时,只使用整体数据的10%进行评估常常会在安全方面犯错。
选择测试集时另一个需要考虑的是测试集中实例与开发集中的实例的相似程度。这两个数据集越相似,我们对将评估结果推广到其他数据集的信心就越小。例如,考虑词性标注任务。在一种极端情况,我们可以通过从一个反映单一的文体(如新闻)的数据源随机分配句子,创建训练集和测试集:
|
在这种情况下,我们的测试集和训练集将是非常相似的。训练集和测试集均取自同一文体,所以我们不能相信评估结果可以推广到其他文体。更糟糕的是,因为调用random.shuffle(),测试集中包含来自训练使用过的相同的文档的句子。如果文档中有相容的模式(也就是说,如果一个给定的词与特定词性标记一起出现特别频繁),那么这种差异将体现在开发集和测试集。一个稍好的做法是确保训练集和测试集来自不同的文件:
|
如果我们要执行更令人信服的评估,可以从与训练集中文档联系更少的文档中获取测试集:
|
如果我们在此测试集上建立了一个性能很好的分类器,那么我们完全可以相信它有能力很好的泛化到用于训练它的数据以外的数据。
3.2 准确度
用于评估一个分类最简单的度量是准确度,测量测试集上分类器正确标注的输入的比例。例如,一个名字性别分类器,在包含80个名字的测试集上预测正确的名字有60个,它有60/80 = 75%的准确度。nltk.classify.accuracy()函数会在给定的测试集上计算分类器模型的准确度:
|
解释一个分类器的准确性得分,考虑测试集中单个类标签的频率是很重要的。例如,考虑一个决定词bank每次出现的正确的词意的分类器。如果我们在金融新闻文本上评估分类器,那么我们可能会发现,金融机构的意思20个里面出现了19次。在这种情况下,95%的准确度也难以给人留下深刻印象,因为我们可以实现一个模型,它总是返回金融机构的意义。然而,如果我们在一个更加平衡的语料库上评估分类器,那里的最频繁的词意只占40%,那么95%的准确度得分将是一个更加积极的结果。(在2测量标注一致性程度时也会有类似的问题。)
3.3 精确度和召回率
另一个准确度分数可能会产生误导的实例是在“搜索”任务中,如信息检索,我们试图找出与特定任务有关的文档。由于不相关的文档的数量远远多于相关文档的数量,一个将每一个文档都标记为无关的模型的准确度分数将非常接近100%。
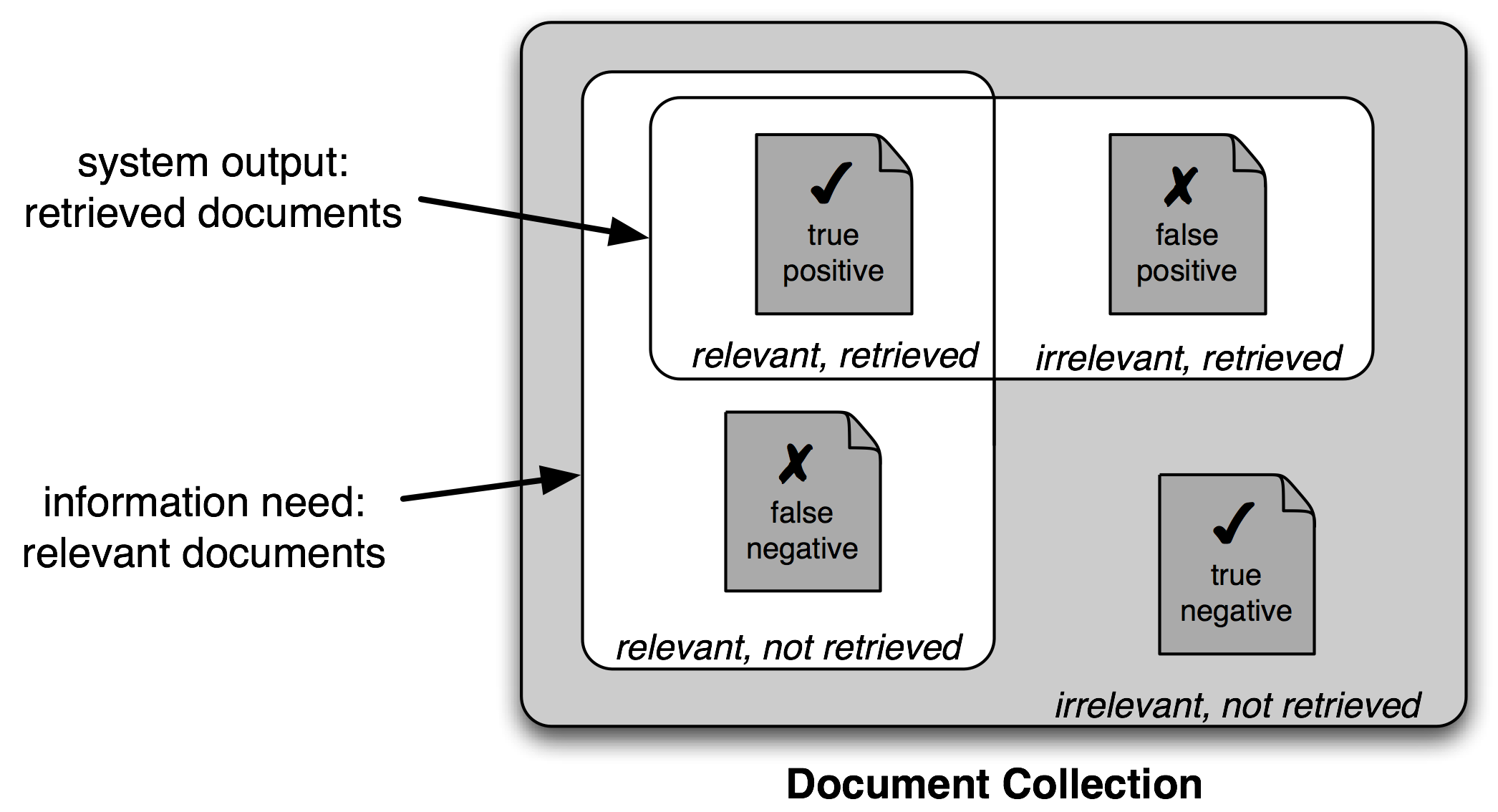
图 3.1:真与假的阳性和阴性
因此,对搜索任务使用不同的测量集是很常见的,基于3.1所示的四个类别的每一个中的项目的数量:
- 真阳性是相关项目中我们正确识别为相关的。
- 真阴性是不相关项目中我们正确识别为不相关的。
- 假阳性(或I 型错误)是不相关项目中我们错误识别为相关的。
- 假阴性(或II型错误)是相关项目中我们错误识别为不相关的。
给定这四个数字,我们可以定义以下指标:
- 精确度,表示我们发现的项目中有多少是相关的,TP/(TP+FP)。
- 召回率,表示相关的项目中我们发现了多少,TP/(TP+FN)。
- F-度量值(或F-Score),组合精确度和召回率为一个单独的得分,被定义为精确度和召回率的调和平均数(2 × Precision × Recall) / (Precision + Recall)。
3.4 混淆矩阵
当处理有3 个或更多的标签的分类任务时,基于模型错误类型细分模型的错误是有信息量的。一个混淆矩阵是一个表,其中每个cells [i,j]表示正确的标签i被预测为标签j的次数。因此,对角线项目(即cells |ii|)表示正确预测的标签,非对角线项目表示错误。在下面的例子中,我们为4中开发的一元标注器生成一个混淆矩阵:
|
这个混淆矩阵显示常见的错误,包括NN替换为了JJ(1.6%的词),NN替换为了NNS(1.5%的词)。注意点(.)表示值为0 的单元格,对角线项目——对应正确的分类——用尖括号标记。.. XXX explain use of "reference" in the legend above.
3.5 交叉验证
为了评估我们的模型,我们必须为测试集保留一部分已标注的数据。正如我们已经提到,如果测试集是太小了,我们的评价可能不准确。然而,测试集设置较大通常意味着训练集设置较小,如果已标注数据的数量有限,这样设置对性能会产生重大影响。
这个问题的解决方案之一是在不同的测试集上执行多个评估,然后组合这些评估的得分,这种技术被称为交叉验证。特别是,我们将原始语料细分为N个子集称为折叠。对于每一个这些的折叠,我们使用除这个折叠中的数据外其他所有数据训练模型,然后在这个折叠上测试模型。即使个别的折叠可能是太小了而不能在其上给出准确的评价分数,综合评估得分是基于大量的数据,因此是相当可靠的。
第二,同样重要的,采用交叉验证的优势是,它可以让我们研究不同的训练集上性能变化有多大。如果我们从所有N个训练集得到非常相似的分数,然后我们可以相当有信心,得分是准确的。另一方面,如果N个训练集上分数很大不同,那么,我们应该对评估得分的准确性持怀疑态度。
4 决策树
接下来的三节中,我们将仔细看看可用于自动生成分类模型的三种机器学习方法:决策树、朴素贝叶斯分类器和最大熵分类器。正如我们所看到的,可以把这些学习方法看作黑盒子,直接训练模式,使用它们进行预测而不需要理解它们是如何工作的。但是,仔细看看这些学习方法如何基于一个训练集上的数据选择模型,会学到很多。了解这些方法可以帮助指导我们选择相应的特征,尤其是我们关于那些特征如何编码的决定。理解生成的模型可以让我们更好的提取信息,哪些特征对有信息量,那些特征之间如何相互关联。
决策树是一个简单的为输入值选择标签的流程图。这个流程图由检查特征值的决策节点和分配标签的叶节点组成。为输入值选择标签,我们以流程图的初始决策节点开始,称为其根节点。此节点包含一个条件,检查输入值的特征之一,基于该特征的值选择一个分支。沿着这个描述我们输入值的分支,我们到达了一个新的决策节点,有一个关于输入值的特征的新的条件。我们继续沿着每个节点的条件选择的分支,直到到达叶节点,它为输入值提供了一个标签。4.1显示名字性别任务的决策树模型的例子。
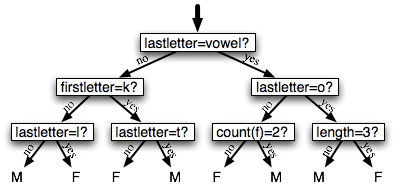
图 4.1:名字性别任务的决策树模型。请注意树图按照习惯画出“颠倒的”,根在上面,叶子在下面。
一旦我们有了一个决策树,就可以直接用它来分配标签给新的输入值。不那么直接的是我们如何能够建立一个模拟给定的训练集的决策树。但在此之前,我们看一下建立决策树的学习算法,思考一个简单的任务:为语料库选择最好的“决策树桩”。决策树桩是只有一个节点的决策树,基于一个特征决定如何为输入分类。每个可能的特征值一个叶子,为特征有那个值的输入指定类标签。要建立决策树桩,我们首先必须决定哪些特征应该使用。最简单的方法是为每个可能的特征建立一个决策树桩,看哪一个在训练数据上得到最高的准确度,也有其他的替代方案,我们将在下面讨论。一旦我们选择了一个特征,就可以通过分配一个标签给每个叶子,基于在训练集中所选的例子的最频繁的标签,建立决策树桩(即选择特征具有那个值的例子)。
给出了选择决策树桩的算法,生长出较大的决策树的算法就很简单了。首先,我们选择分类任务的整体最佳的决策树桩。然后,我们在训练集上检查每个叶子的准确度。没有达到足够的准确度的叶片被新的决策树桩替换,新决策树桩是在根据到叶子的路径选择的训练语料的子集上训练的。例如,我们可以使4.1中的决策树生长,通过替换最左边的叶子为新的决策树桩,这个新的决策树桩是在名字不以"k"开始或以一个元音或"l"结尾的训练集的子集上训练的。
4.1 熵和信息增益
正如之前提到的,有几种方法来为决策树桩确定最有信息量的特征。一种流行的替代方法,被称为信息增益,当我们用给定的特征分割输入值时,衡量它们变得更有序的程度。要衡量原始输入值集合如何无序,我们计算它们的标签的墒,如果输入值的标签非常不同,墒就高;如果输入值的标签都相同,墒就低。特别地,熵被定义为每个标签的概率乘以那个标签的log概率的总和:
| (1) | H = −Σl |in| labelsP(l) × log2P(l). |
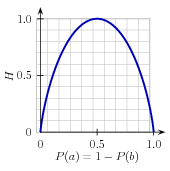
图 4.2:名字性别预测任务中标签的墒,作为给定名字集合中是男性的百分比的函数。
例如,4.2显示了在名字性别预测任务中标签的墒如何取决于男性名字对女性名字的比例。请注意,如果大多数输入值具有相同的标签(例如,如果P(male)接近0或接近1),那么墒很低。特别的,低频率的标签不会贡献多少给墒(因为P(l)很小),高频率的标签对熵也没有多大帮助(因为log2P(l)很小)。另一方面,如果输入值的标签变化很多,那么有很多“中等”频率的标签,它们的P(l)和log2P(l)都不小,所以墒很高。4.3演示了如何计算标签列表的墒。
| ||
| ||
例 4.3 (code_entropy.py):图 4.3:计算标签列表的墒 |
一旦我们已经计算了原始输入值的标签集的墒,就可以判断应用了决策树桩之后标签会变得多么有序。为了这样做,我们计算每个决策树桩的叶子的熵,利用这些叶子熵值的平均值(加权每片叶子的样本数量)。信息增益等于原来的熵减去这个新的减少的熵。信息增益越高,将输入值分为相关组的决策树桩就越好,于是我们可以通过选择具有最高信息增益的决策树桩来建立决策树。
决策树的另一个考虑因素是效率。前面描述的选择决策树桩的简单算法必须为每一个可能的特征构建候选决策树桩,并且这个过程必须在构造决策树的每个节点上不断重复。已经开发了一些算法通过存储和重用先前评估的例子的信息减少训练时间。
决策树有一些有用的性质。首先,它们简单明了,容易理解。决策树顶部附近尤其如此,这通常使学习算法可以找到非常有用的特征。决策树特别适合有很多层次的分类区别的情况。例如,决策树可以非常有效地捕捉进化树。
然而,决策树也有一些缺点。一个问题是,由于决策树的每个分支会划分训练数据,在训练树的低节点,可用的训练数据量可能会变得非常小。因此,这些较低的决策节点可能
过拟合训练集,学习模式反映训练集的特质而不是问题底层显著的语言学模式。对这个问题的一个解决方案是当训练数据量变得太小时停止分裂节点。另一种方案是长出一个完整的决策树,但随后剪去在开发测试集上不能提高性能的决策节点。
决策树的第二个问题是,它们强迫特征按照一个特定的顺序进行检查,即使特征可能是相对独立的。例如,按主题分类文档(如体育、汽车或谋杀之谜)时,特征如hasword(football)极可能表示一个特定标签,无论其他的特征值是什么。由于决策树顶部附近的空间有限,大部分这些特征将需要在树中的许多不同的分支中重复。因为越往树的下方,分支的数量成指数倍增长,重复量可能非常大。
一个相关的问题是决策树不善于利用对正确的标签具有较弱预测能力的特征。由于这些特征的影响相对较小,它们往往出现在决策树非常低的地方。决策树学习的时间远远不够用到这些特征,也不能留下足够的训练数据来可靠地确定它们应该有什么样的影响。如果我们能够在整个训练集中看看这些特征的影响,那么我们也许能够做出一些关于它们是如何影响标签的选择的结论。
决策树需要按一个特定的顺序检查特征的事实,限制了它们的利用相对独立的特征的能力。我们下面将讨论的朴素贝叶斯分类方法克服了这一限制,允许所有特征“并行”的起作用。
5 朴素贝叶斯分类器
在朴素贝叶斯分类器中,每个特征都得到发言权,来确定哪个标签应该被分配到一个给定的输入值。为一个输入值选择标签,朴素贝叶斯分类器以计算每个标签的先验概率开始,它由在训练集上检查每个标签的频率来确定。之后,每个特征的贡献与它的先验概率组合,得到每个标签的似然估计。似然估计最高的标签会分配给输入值。5.1说明了这一过程。
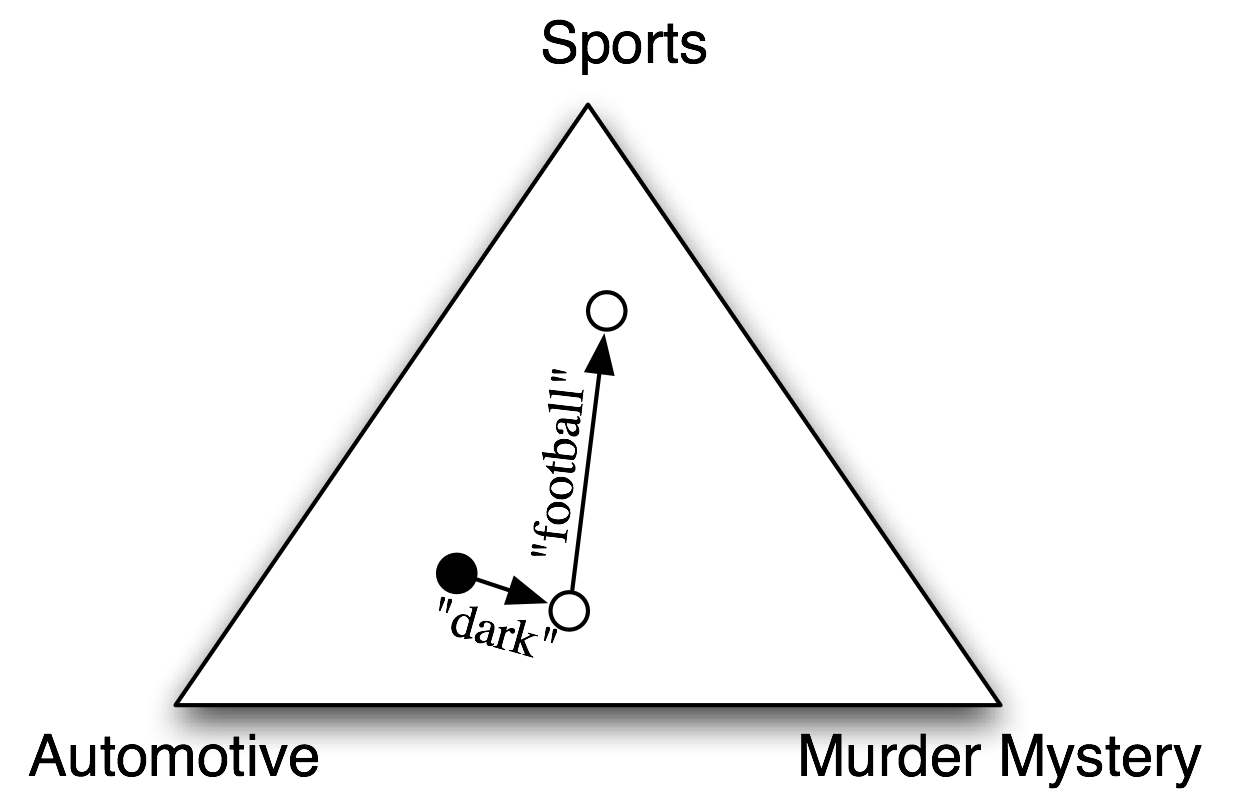
图 5.1:使用朴素贝叶斯分类器为文档选择主题的程序的抽象图解。在训练语料中,大多数文档是有关汽车的,所以分类器从接近“汽车”的标签的点上开始。但它会考虑每个特征的影响。在这个例子中,输入文档中包含的词"dark",它是谋杀之谜的一个不太强的指标,也包含词"football",它是体育文档的一个有力指标。每个特征都作出了贡献之后,分类器检查哪个标签最接近,并将该标签分配给输入。
个别特征对整体决策作出自己的贡献,通过“投票反对”那些不经常出现的特征的标签。特别是,每个标签的似然得分由于与输入值具有此特征的标签的概率相乘而减小。例如,如果词run在12%的体育文档中出现,在10%的谋杀之谜的文档中出现,在2%的汽车文档中出现,那么体育标签的似然得分将被乘以0.12,谋杀之谜标签将被乘以0.1,汽车标签将被乘以0.02。整体效果是略高于体育标签的得分的谋杀之谜标签的得分会减少,而汽车标签相对于其他两个标签会显著减少。这个过程如5.2和5.3所示。
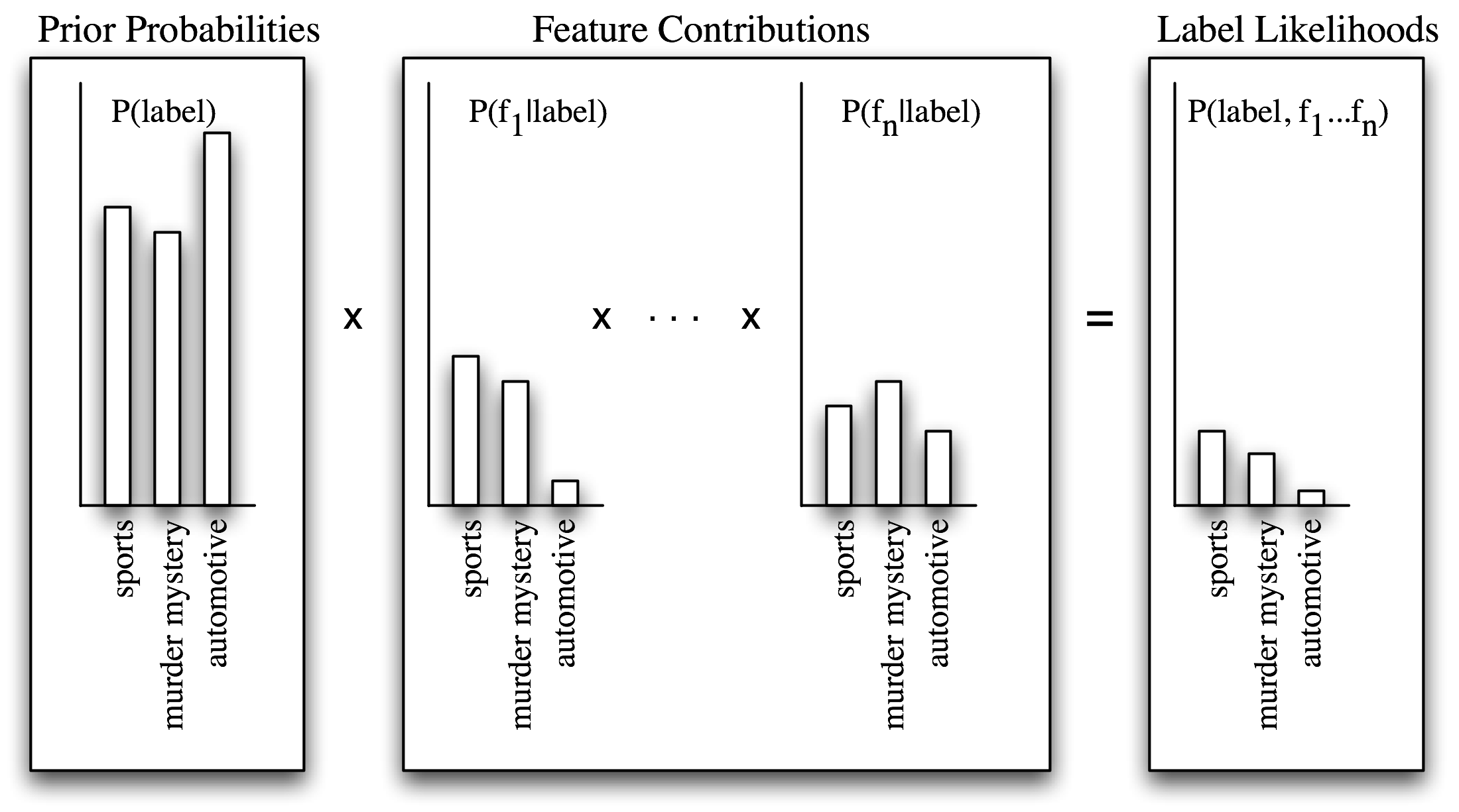
图 5.2:计算朴素贝叶斯的标签似然得分。朴素贝叶斯以计算每个标签的先验概率开始,基于每个标签出现在训练数据中的频率。然后每个特征都用于估计每个标签的似然估计,通过用输入值中有那个特征的标签的概率乘以它。似然得分结果可以认为是从具有给定的标签和特征集的训练集中随机选取的值的概率的估计,假设所有特征概率是独立的。
5.1 底层的概率模型
理解朴素贝叶斯分类器的另一种方式是它为输入选择最有可能的标签,基于下面的假设:每个输入值是通过首先为那个输入值选择一个类标签,然后产生每个特征的方式产生的,每个特征与其他特征完全独立。当然,这种假设是不现实的,特征往往高度依赖彼此。我们将在本节结尾回过来讨论这个假设的一些后果。这简化的假设,称为朴素贝叶斯假设(或独立性假设),使得它更容易组合不同特征的贡献,因为我们不必担心它们相互影响。
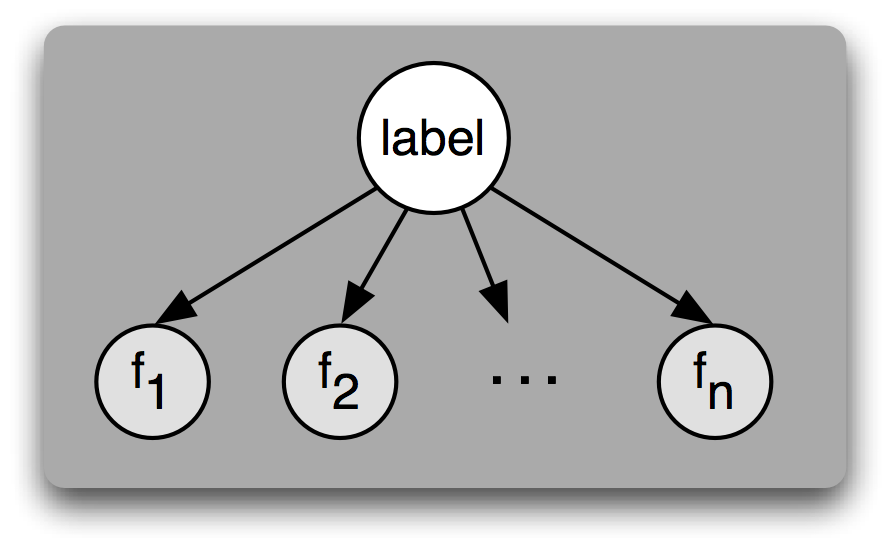
图 5.3:一个贝叶斯网络图演示朴素贝叶斯分类器假定的生成过程。要生成一个标记的输入,模型先为输入选择标签,然后基于该标签生成每个输入的特征。对给定标签,每个特征被认为是完全独立于所有其他特征的。
基于这个假设,我们可以计算表达式P(label|features),给定一个特别的特征集一个输入具有特定标签的概率。要为一个新的输入选择标签,我们可以简单地选择使P(l|features)最大的标签l。
一开始,我们注意到P(label|features)等于具有特定标签和特定特征集的输入的概率除以具有特定特征集的输入的概率:
| (2) | P(label|features) = P(features, label)/P(features) |
接下来,我们注意到P(features)对每个标签选择都相同,因此如果我们只是对寻找最有可能的标签感兴趣,只需计算P(features, label),我们称之为该标签的似然。
注意
如果我们想生成每个标签的概率估计,而不是只选择最有可能的标签,那么计算P(features)的最简单的方法是简单的计算P(features, label)在所有标签上的总和:
| (3) | P(features) = Σl in| labels P(features, label) |
标签的似然可以展开为标签的概率乘以给定标签的特征的概率:
| (4) | P(features, label) = P(label) × P(features|label) |
进一步,因为特征都是独立的(给定标签),我们可以分离每个独立特征的概率:
| (5) | P(features, label) = P(label) × Prodf in| featuresP(f|label)` |
这正是我们前面讨论的用于计算标签可能性的方程式:P(label)是一个给定标签的先验概率,每个P(f|label)是一个单独的特征对标签可能性的贡献。
5.2 零计数和平滑
最简单的方法计算P(f|label),特征f对标签label的标签可能性的贡献,是取得具有给定特征和给定标签的训练实例的百分比:
| (6) | P(f|label) = count(f, label) / count(label) |
然而,当训练集中有特征从来没有和给定标签一起出现时,这种简单的方法会产生一个问题。在这种情况下,我们的P(f|label)计算值将是0,这将导致给定标签的标签可能性为0。从而,输入将永远不会被分配为这个标签,不管其他特征有多么适合这个标签。
这里的基本问题与我们计算P(f|label)有关,对于给定标签输入将具有一个特征的概率。特别的,仅仅因为我们在训练集中没有看到特征/标签组合出现,并不意味着该组合不会出现。例如,我们可能不会看到任何谋杀之迷文档中包含词"football",但我们不希望作出结论认为在这些文档中存在是完全不可能。
因此,虽然count(f,label)/count(label)在当count(f, label)相对高时是P(f|label)的好的估计,当count(f)变小时这个估计变得不那么可靠。因此,建立朴素贝叶斯模型时,我们通常采用更复杂的技术,被称为平滑技术,用于计算P(f|label),给定标签的特征的概率。例如,给定标签的一个特征的概率的期望似然估计基本上给每个count(f,label)值加0.5,Heldout估计使用一个heldout语料库计算特征频率与特征概率之间的关系。nltk.probability模块提供了多种平滑技术的支持。
5.3 非二元特征
我们这里假设每个特征是二元的,即每个输入要么有这个特征要么没有。标签值特征(例如颜色特征,可能有红色、绿色、蓝色、白色或橙色)可通过用二元特征,如“颜色是红色”,替换它们,将它们转换为二元特征。数字特征可以通过装箱转换为二元特征,用特征如“4<x<6”替换它们。
另一种方法是使用回归方法模拟数字特征的概率。例如:如果我们假设特征height具有贝尔曲线分布,那么我们可以通过找到每个标签的输入的height 的均值和方差来估算P(height|label)。在这种情况下,P(f=v|label)将不会是一个固定值,会依赖v的值变化。
5.4 独立的朴素
朴素贝叶斯分类器被称为“朴素”的原因是它不切实际地假设所有特征相互独立(给定标签)。特别的,几乎所有现实世界的问题含有的特征都不同程度的彼此依赖。如果我们要避免任何依赖其他特征的特征,那将很难构建良好的功能集,提供所需的信息给机器学习算法。
如果我们忽略了独立性假设,使用特征不独立的朴素贝叶斯分类器会发生什么?产生的一个问题是分类器“双重计数”高度相关的特征的影响,将分类器推向更接近给定的标签而不是合理的标签。
来看看这种情况怎么出现的,思考一个包含两个相同的特征f1和f2字性别分类器。换句话说,f2是f1的精确副本,不包含任何新的信息。当分类器考虑输入,在决定选择哪一个标签时,它会同时包含f1和f2的贡献。因此,这两个特征的信息内容将被赋予比它们应得的更多的比重。
当然,我们通常不会建立包含两个相同的特征的朴素贝叶斯分类器。不过,我们会建立包含相互依赖特征的分类器。例如,特征ends-with(a)和ends-with(vowel)是彼此依赖,因为如果一个输入值有第一个特征,那么它也必有第二个特征。对于这些功能,重复的信息可能会被训练集赋予比合理的更多的比重。
5.5 双重计数的原因
双重计数问题的原因是在训练过程中特征的贡献被分开计算,但当使用分类器为新输入选择标签时,这些特征的贡献被组合。因此,一个解决方案是考虑在训练中特征的贡献之间可能的相互作用。然后,我们就可以使用这些相互作用调整独立特征所作出的贡献。
为了使这个更精确,我们可以重写计算标签的可能性的方程,分离出每个功能(或标签)所作出的贡献:
| (7) | P(features, label) = w[label] × Prodf |in| features w[f, label] |
在这里,w[label]是一个给定标签的“初始分数”,w[f, label]是给定特征对一个标签的可能性所作的贡献。我们称这些值w[label]和w[f, label]为模型的参数或权重。使用朴素贝叶斯算法,我们单独设置这些参数:
| (8) | w[label] = P(label) |
| (9) | w[f, label] = P(f|label) |
然而,在下一节中,我们将来看一个分类器,它在选择这些参数的值时会考虑它们之间可能的相互作用的。
6 最大熵分类器
最大熵分类器使用了一个与朴素贝叶斯分类器使用的模型非常相似的模型。但是不是使用概率设置模型的参数,它使用搜索技术找出一组将最大限度地提高分类器准确性的参数。特别的,它查找使训练语料的整体可能性最大的参数组。其定义如下:
| (10) | P(features) = Σx |in| corpus P(label(x)|features(x)) |
其中P(label|features),一个特征为features将有类标签label的输入的概率,被定义为:
| (11) | P(label|features) = P(label, features) / Σlabel P(label, features) |
由于相关特征的影响之间的潜在的复杂的相互作用,没有办法直接计算最大限度地提高训练集的可能性的模型参数。因此,最大熵分类器采用迭代优化技术选择模型参数,该技术用随机值初始化模型的参数,然后反复优化这些参数,使它们更接近最优解。这些迭代优化技术保证每次参数的优化都会使它们更接近最佳值,但不一定提供方法来确定是否已经达到最佳值。由于最大熵分类器使用迭代优化技术选择参数,它们花费很长的时间来学习。当训练集的大小、特征的数目以及标签的数目都很大时尤其如此。
注意
一些迭代优化技术比别的快得多。当训练最大熵模型时,应避免使用广义迭代缩放(GIS)或改进的迭代缩放(IIS),这两者都比共轭梯度(CG)和BFGS优化方法慢很多。
6.1 最大熵模型
最大熵分类器模型是一朴素贝叶斯分类器模型的泛化。像朴素贝叶斯模型一样,最大熵分类器为给定的输入值计算每个标签的可能性,通过将适合于输入值和标签的参数乘在一起。朴素贝叶斯分类器模型为每个标签定义一个参数,指定其先验概率,为每个(特征,标签)对定义一个参数,指定独立的特征对一个标签的可能性的贡献。
相比之下,最大熵分类器模型留给用户来决定什么样的标签和特征组合应该得到自己的参数。特别的,它可以使用一个单独的参数关联一个特征与一个以上的标签;或者关联一个以上的特征与一个给定的标签。这有时会允许模型“概括”相关的标签或特征之间的一些差异。
每个接收它自己的参数的标签和特征的组合被称为一个联合特征。请注意,联合特征是有标签的的值的属性,而(简单)特征是未加标签的值的属性。
注意
描述和讨论最大熵模型的文字中,术语“特征”往往指联合特征;术语“上下文”指我们一直说的(简单)特征。
通常情况下,用来构建最大熵模型的联合特征完全镜像朴素贝叶斯模型使用的联合特征。特别的,每个标签定义的联合特征对应于w[label],每个(简单)特征和标签组合定义的联合特征对应于w[f,label]。给定一个最大熵模型的联合特征,分配到一个给定输入的标签的得分与适用于该输入和标签的联合特征相关联的参数的简单的乘积:
| (12) | P(input, label) = Prodjoint-features(input,label) w[joint-feature] |
6.2 熵的最大化
进行最大熵分类的直觉是我们应该建立一个模型,捕捉单独的联合特征的频率,不必作任何无根据的假设。举一个例子将有助于说明这一原则。
假设我们被分配从10个可能的任务的列表(标签从A-J)中为一个给定的词找出正确词意的任务。首先,我们没有被告知其他任何关于词或词意的信息。我们可以为10种词意选择的概率分布很多,例如:
表 6.1
| A | B | C | D | E | F | G | H | I | J | |
|---|---|---|---|---|---|---|---|---|---|---|
| (i) | 10% | 10% | 10% | 10% | 10% | 10% | 10% | 10% | 10% | 10% |
| (ii) | 5% | 15% | 0% | 30% | 0% | 8% | 12% | 0% | 6% | 24% |
| (iii) | 0% | 100% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
虽然这些分布都可能是正确的,我们很可能会选择分布(i),因为没有任何更多的信息,也没有理由相信任何词的词意比其他的更有可能。另一方面,分布(ii)及(iii)反映的假设不被我们已知的信息支持。
直觉上这种分布(i)比其他的更“公平”,解释这个的一个方法是引用熵的概念。在决策树的讨论中,我们描述了熵作为衡量一套标签是如何“无序”。特别的,如果是一个单独的标签则熵较低,但如果标签的分布比较均匀则熵较高。在我们的例子中,我们选择了分布(i)因为它的标签概率分布均匀——换句话说,因为它的熵较高。一般情况下,最大熵原理是说在与我们所知道的一致的的分布中,我们会选择熵最高的。
接下来,假设我们被告知词意A 出现的次数占55%。再一次,有许多分布与这一条新信息一致,例如:
表 6.2
| A | B | C | D | E | F | G | H | I | J | |
|---|---|---|---|---|---|---|---|---|---|---|
| (iv) | 55% | 45% | 0% | 0% | 0% | 0% | 0% | 0% | 0% | 0% |
| (v) | 55% | 5% | 5% | 5% | 5% | 5% | 5% | 5% | 5% | 5% |
| (vi) | 55% | 3% | 1% | 2% | 9% | 5% | 0% | 25% | 0% | 0% |
但是,我们可能会选择最少无根据的假设的分布——在这种情况下,分布(v)。
最后,假设我们被告知词up出现在nearby上下文中的次数占10%,当它出现在这个上下文中时有80%的可能使用词意A或C。在这种情况下,我们很难手工找到合适的分布;然而,可以验证下面的看起来适当的分布:
表 6.3
| A | B | C | D | E | F | G | H | I | J | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (vii) | +up | 5.1% | 0.25% | 2.9% | 0.25% | 0.25% | 0.25% | 0.25% | 0.25% | 0.25% | 0.25% |
| ` ` | -up | 49.9% | 4.46% | 4.46% | 4.46% | 4.46% | 4.46% | 4.46% | 4.46% | 4.46% | 4.46% |
特别的,与我们所知道的一致的分布:如果我们将A 列的概率加起来是55%,如果我们将第1 行的概率加起来是10%;如果我们将+up 行词意A 和C 的概率加起来是8%(或+up 行的80%)。此外,其余的概率“均匀分布”。
纵观这个例子,我们将自己限制在与我们所知道的一致的分布上;其中,我们选择最高熵的分布。这正是最大熵分类器所做的。特别的,对于每个联合特征,最大熵模型计算该特征的“经验频率”——即它出现在训练集中的频率。然后,它搜索熵最大的分布,同时也预测每个联合特征正确的频率。
6.3 生成式分类器对比条件式分类器
朴素贝叶斯分类器和最大熵分类器之间的一个重要差异是它们可以被用来回答问题的类型。朴素贝叶斯分类器是一个生成式分类器的例子,建立一个模型,预测P(input, label),即(input, label)对的联合概率。因此,生成式模型可以用来回答下列问题:
- 一个给定输入的最可能的标签是什么?
- 对于一个给定输入,一个给定标签有多大可能性?
- 最有可能的输入值是什么?
- 一个给定输入值的可能性有多大?
- 一个给定输入具有一个给定标签的可能性有多大?
- 对于一个可能有两个值中的一个值(但我们不知道是哪个)的输入,最可能的标签是什么?
另一方面,最大熵分类器是条件式分类器的一个例子。条件式分类器建立模型预测P(label|input)——一个给定输入值的标签的概率。因此,条件式模型仍然可以被用来回答问题1和2。然而,条件式模型不能用来回答剩下的问题3-6。
一般情况下,生成式模型确实比条件式模型强大,因为我们可以从联合概率P(input, label)计算出条件概率P(label|input),但反过来不行。然而,这种额外的能力是要付出代价的。由于该模型更强大的,它也有更多的“自由参数”需要学习的。而训练集的大小是固定的。因此,使用一个更强大的模型时,我们可用来训练每个参数的值的数据也更少,使其难以找到最佳参数值。结果是一个生成式模型回答问题1和2可能不会与条件式模型一样好,因为条件式模型可以集中精力在这两个问题上。然而,如果我们确实需要像3-6问题的答案,那么我们别无选择,只能使用生成式模型。
生成式模型与条件式模型之间的差别类似与一张地形图和一张地平线的图片之间的区别。虽然地形图可用于回答问题的更广泛,制作一张精确的地形图也明显比制作一张精确的地平线图片更加困难。
7 为语言模式建模
分类器可以帮助我们理解自然语言中存在的语言模式,允许我们建立明确的模型捕捉这些模式。通常情况下,这些模型使用有监督的分类技术,但也可以建立分析型激励模型。无论哪种方式,这些明确的模型有两个重要目的:它们帮助我们了解语言模式,它们可以被用来预测新的语言数据。
明确的模型可以让我们洞察语言模式,在很大程度上取决于使用哪种模型。一些模型,如决策树,相对透明,直接给我们信息:哪些因素是决策中重要的,哪些因素是彼此相关的。另一些模型,如多级神经网络,比较不透明。虽然有可能通过研究它们获得洞察力,但通常需要大量的工作。
但是,所有明确的模型都可以预测新的未见过的建立模型时未包括在语料中的语言数据。可以对这些预测进行评估获得模型的准确性。一旦模型被认为足够准确,它就可以被用来自动预测新的语言数据信息。这些预测模型可以组合成系统,执行很多有用的语言处理任务,例如文档分类、自动翻译、问答系统。
7.1 模型告诉我们什么?
理解我们可以从自动构建的模型中学到关于语言的什么是很重要的。处理语言模型时一个重要的考虑因素是描述性模型与解释性模型之间的区别。描述性模型捕获数据中的模式,但它们并不提供任何有关数据包含这些模式的原因的信息。例如,我们在3.1中看到的,同义词absolutely和definitely是不能互换的:我们说absolutely adore而不是definitely adore,definitely prefer而不是absolutely prefer。与此相反,解释性模型试图捕捉造成语言模式的属性和关系。例如,我们可能会介绍一个抽象概念“极性动词”为一个具有极端意义的动词,并对一些动词进行分类,如adore和detest是相反的两极。我们的解释性模式将包含约束:absolutely只能与极性动词结合,definitely只能与非极性动词结合。总之,描述性模型提供数据内相关性的信息,而解释性模型再进一步假设因果关系。
大多数从语料库自动构建的模型是描述性模型;换句话说,它们可以告诉我们哪些特征与一个给定的模式或结构有关,但它们不一定能告诉我们这些特征和模式之间如何关联。如果我们的目标是理解语言模式,那么我们就可以使用哪些特征是相关的这一信息作为出发点,设计进一步的实验弄清特征与模式之间的关系。另一方面,如果我们只是对利用该模型进行预测(例如作为一种语言处理系统的一部分)感兴趣,那么我们可以使用该模型预测新的数据,而不用担心潜在的因果关系的细节。
8 小结
- 为语料库中的语言数据建模可以帮助我们理解语言模型,也可以用于预测新语言数据。
- 有监督分类器使用加标签的训练语料库来建立模型,基于输入的特征,预测那个输入的标签。
- 有监督分类器可以执行多种NLP任务,包括文档分类、词性标注、语句分割、对话行为类型识别以及确定蕴含关系和很多其他任务。
- 训练一个有监督分类器时,你应该把语料分为三个数据集:用于构造分类器模型的训练集,用于帮助选择和调整模型特性的开发测试集,以及用于评估最终模型性能的测试集。
- 评估一个有监督分类器时,重要的是你要使用新鲜的没有包含在训练集或开发测试集中的数据。否则,你的评估结果可能会不切实际地乐观。
- 决策树可以自动地构建树结构的流程图,用于为输入变量值基于它们的特征加标签。虽然它们易于解释,但不适合处理特性值在决定合适标签过程中相互影响的情况。
- 在朴素贝叶斯分类器中,每个特征决定应该使用哪个标签的贡献是独立的。它允许特征值间有关联,但当两个或更多的特征高度相关时将会有问题。
- 最大熵分类器使用的基本模型与朴素贝叶斯相似;不过,它们使用了迭代优化来寻找使训练集的概率最大化的特征权值集合。
- 大多数从语料库自动构建的模型都是描述性的,也就是说,它们让我们知道哪些特征与给定的模式或结构相关,但它们没有给出关于这些特征和模式之间的因果关系的任何信息。
9 深入阅读
关于本章和如何安装外部机器学习包,如Weka、Mallet、TADM 和MegaM的进一步的材料请查询http://nltk.org/。关于使用NLTK标注的更多的例子,请看在http://nltk.org/howto上的分类HOWTO。
机器学习的一般介绍我们推荐(Alpaydin, 2004)。更多机器学习理论的数学专著,见(Hastie, Tibshirani, & Friedman, 2009)。使用机器学习技术进行自然语言处理的优秀图书包括(Abney, 2008), (Daelemans & Bosch, 2005), (Feldman & Sanger, 2007), (Segaran, 2007), (Weiss et al, 2004)。语言问题上的平滑技术的更多信息,请参阅(Manning & Schutze, 1999)。序列建模尤其是隐马尔可夫模型的更多信息,请参阅(Manning & Schutze, 1999)或(Jurafsky & Martin, 2008)。(Manning, Raghavan, & Schutze, 2008)的第13 章讨论了利用朴素贝叶斯分类文本。
许多在本章中讨论的机器学习算法都是数值计算密集的,使用纯Python编码时它们运行的很慢。关于Python中提升数值密集型算法效率的信息,请参阅(Kiusalaas, 2005)。
本章中所描述的分类技术应用范围可以非常广泛。例如,(Agirre & Edmonds, 2007)使用分类器处理词义消歧;(Melamed, 2001)使用分类器创建平行文本。最近的包括文本分类的教科书有(Manning, Raghavan, & Schutze, 2008)和(Croft, Metzler, & Strohman, 2009)。
目前机器学习技术应用到NLP问题的研究大部分是由政府主办的“挑战”,在那里提供给一些研究机构相同的开发语料库,要求建立一个系统,使用保留的测试集比较系统的结果。这些挑战比赛的例子包括CoNLL共享任务、ACE 比赛、文字蕴含识别比赛和AQUAINT比赛。这些挑战的网页链接的列表请参阅http://nltk.org/。
10 练习
☼ 阅读在本章中提到的语言技术,如词意消歧、语义角色标注、问答系统、机器翻译,命名实体识别之一。找出开发这种系统需要什么类型和多少数量的已标注的数据。为什么你会认为需要大量的数据?
☼ 使用任何本章所述的三种分类器之一,以及你能想到的特征,尽量好的建立一个名字性别分类器。从将名字语料库分成3 个子集开始:500个词为测试集,500个词为开发测试集,剩余6900个词为训练集。然后从示例的名字性别分类器开始,逐步改善。使用开发测试集检查你的进展。一旦你对你的分类器感到满意,在测试集上检查它的最终准确性。相比在开发测试集上的准确性,它在测试集上的准确性如何?这是你期待的吗?
☼ Senseval 2 语料库包含旨在训练词-词义消歧分类器的数据。它包含四个词的数据:hard、interest、line 和serve。选择这四个词中的一个,加载相应的数据:
>>> from nltk.corpus import senseval >>> instances = senseval.instances('hard.pos') >>> size = int(len(instances) * 0.1) >>> train_set, test_set = instances[size:], instances[:size]
使用这个数据集,建立一个分类器,预测一个给定的实例的正确的词意标签。关于使用Senseval 2 语料库返回的实例对象的信息请参阅http://nltk.org/howto上的语料库HOWTO。
☼ 使用本章讨论过的电影评论文档分类器,产生对分类器最有信息量的30个特征的列表。你能解释为什么这些特定特征具有信息量吗?你能在它们中找到什么惊人的发现吗?
☼ 选择一个本章所描述的分类任务,如名字性别检测、文档分类、词性标注或对话行为分类。使用相同的训练和测试数据,相同的特征提取器,建立该任务的三个分类器::决策树、朴素贝叶斯分类器和最大熵分类器。比较你所选任务上这三个分类器的准确性。你如何看待如果你使用了不同的特征提取器,你的结果可能会不同?
☼ 同义词strong和powerful的模式不同(尝试将它们与chip和sales结合)。哪些特征与这种区别有关?建立一个分类器,预测每个词何时该被使用。
◑ 对话行为分类器为每个帖子分配标签,不考虑帖子的上下文背景。然而,对话行为是高度依赖上下文的,一些对话行序列可能比别的更相近。例如,ynQuestion 对话行为更容易被一个yanswer回答而不是以一个问候来回答。利用这一事实,建立一个连续的分类器,为对话行为加标签。一定要考虑哪些特征可能是有用的。参见1.7词性标记的连续分类器的代码,获得一些想法。
◑ 词特征在处理文本分类中是非常有用的,因为在一个文档中出现的词对于其语义内容是什么具有强烈的指示作用。然而,很多词很少出现,一些在文档中的最有信息量的词可能永远不会出现在我们的训练数据中。一种解决方法是使用一个词典,它描述了词之间的不同。使用WordNet词典,加强本章介绍的电影评论文档分类器,使用概括一个文档中出现的词的特征,使之更容易匹配在训练数据中发现的词。
★ PP 附件语料库是描述介词短语附着决策的语料库。语料库中的每个实例被编码为PPAttachment对象:
>>> from nltk.corpus import ppattach >>> ppattach.attachments('training') [PPAttachment(sent='0', verb='join', noun1='board', prep='as', noun2='director', attachment='V'), PPAttachment(sent='1', verb='is', noun1='chairman', prep='of', noun2='N.V.', attachment='N'), ...] >>> inst = ppattach.attachments('training')[1] >>> (inst.noun1, inst.prep, inst.noun2) ('chairman', 'of', 'N.V.')
选择inst.attachment为N的唯一实例:
>>> nattach = [inst for inst in ppattach.attachments('training') ... if inst.attachment == 'N']
使用此子语料库,建立一个分类器,尝试预测哪些介词是用来连接一对给定的名词。例如,给定的名词对"team"和"researchers",分类器应该预测出介词"of"。更多的使用PP附件语料库的信息,参阅http://nltk.org/howto上的语料库HOWTO。
★ 假设你想自动生成一个场景的散文描述,每个实体已经有了一个唯一描述此实体的词,例如the jar,只是想决定在有关的各项目中是否使用in或on,例如the book is in the cupboard对比the book is on the shelf。通过查找语料数据探讨这个问题;编写需要的程序。
| (13) |
|
关于本文档...
针对NLTK 3.0 作出更新。本章来自于Natural Language Processing with Python,Steven Bird, Ewan Klein 和Edward Loper,Copyright © 2014 作者所有。本章依据Creative Commons Attribution-Noncommercial-No Derivative Works 3.0 United States License [http://creativecommons.org/licenses/by-nc-nd/3.0/us/] 条款,与自然语言工具包 [http://nltk.org/] 3.0 版一起发行。
本文档构建于星期三 2015 年 7 月 1 日 12:30:05 AEST